







当程序出现错误时,系统会自动抛出异常;除此之外,Java也允许程序自行抛出异常,自行抛出异常使用throw语句来完成。
1. 抛出异常
很多时候,系统是否要抛出异常,可能需要根据应用的业务需求来决定,如果程序中的数据、执行与既定的业务需求不符,这就是一种异常。由于与业务需求不符而产生的异常,必须由程序员来决定抛出,系统无法抛出这种异常。
如果需要在程序中自行抛出异常,则应使用throw语句,throw语句可以单独使用,throw语句抛出的不是异常类,而是一个异常实例,而且每次只能抛出一个异常实例。
如果throw语句抛出的异常是Checked异常,则该throw语句要么处于try块里,显式捕获该异常,要么放在一个带throws声明抛出的方法中,即把该异常交给该方法的调用者处理;如果throw语句抛出的异常是Runtime异常,则该语句无须放在try块里,也无须放在带throws声明抛出的方法中;程序既可以显式使用try…catch来捕获并处理该异常,也可以完全不理会该异常,把该异常交给该方法调用者处理。
2. 自定义异常类
在通常情况下,程序很少会自行抛出系统异常,因为异常的类名通常也包含了该异常的有用信息。所以在选择抛出异常时,应该选择合适的异常类,从而可以明确地描述该异常情况。在这种情形下,应用程序常常需要抛出自定义异常。
用户自定义异常都应该继承Exception基类,如果希望自定义Runtime异常,则应该继承RuntimeException基类。定义异常类时通常需要提供两个构造器:一个是无参数的构造器;另一个是带一个字符串参数的构造器,这个字符串将作为该异常对象的描述信息(也就是异常对象的getMessage()方法的返回值)。
public class MyException extends RuntimeException {
public MyException(){}
public MyException(String message){
super(message);
}
}
3. catch和throw同时使用
异常处理方式有如下两种:
- 在出现异常的方法内捕获并处理异常,该方法的调用者将不能再次捕获该异常。
- 该方法签名中声明抛出该异常,将该异常完全交给方法调用者处理。
在实际应用中往往需要更复杂的处理方式——当一个异常出现时,单靠某个方法无法完全处理该异常,必须由几个方法协作才可完全处理该异常。也就是说,在异常出现的当前方法中,程序只对异常进行部分处理,还有些处理需要在该方法的调用者中才能完成,所以应该再次抛出异常,让该方法的调用者也能捕获到异常。
为了实现这种通过多个方法协作处理同一个异常的情形,可以在catch块中结合throw语句来完成。
public class MyException extends Exception {
public MyException(){
}
public MyException(String message){
super(message);
}
}
public class Test {
public static void main(String[] args) {
// 再次捕获bid()方法中的异常
try {
bid("aaa");
} catch (MyException e) {
System.out.println(e.getMessage());
}
}
public static void bid(String price) throws MyException{
double d = 0.0;
try {
d = Double.parseDouble(price);
}catch (Exception e){
// 对异常的处理,仅仅打印异常栈信息
e.printStackTrace();
// 再次抛出异常
throw new MyException("价钱必须是数值,不能是其他字符");
}
}
}
catch块捕获到异常后,系统打印了该异常的跟踪栈信息,接着抛出一个AuctionException异常,通知该方法的调用者再次处理该AuctionException异常。所以程序中的main方法,也就是bid()方法调用者还可以再次捕获AuctionException异常,并将该异常的详细描述信息输出到标准错误输出。
这种catch和throw结合使用的情况在大型企业级应用中非常常用。企业级应用对异常的处理通常分成两个部分:
① 应用后台需要通过日志来记录异常发生的详细情况;
② 应用还需要根据异常向应用使用者传达某种提示。在这种情形下,所有异常都需要两个方法共同完成,也就必须将catch和throw结合使用。
4. 异常链
对于真实的企业级应用而言,常常有严格的分层关系,层与层之间有非常清晰的划分,上层功能的实现严格依赖于下层的API,也不会跨层访问。
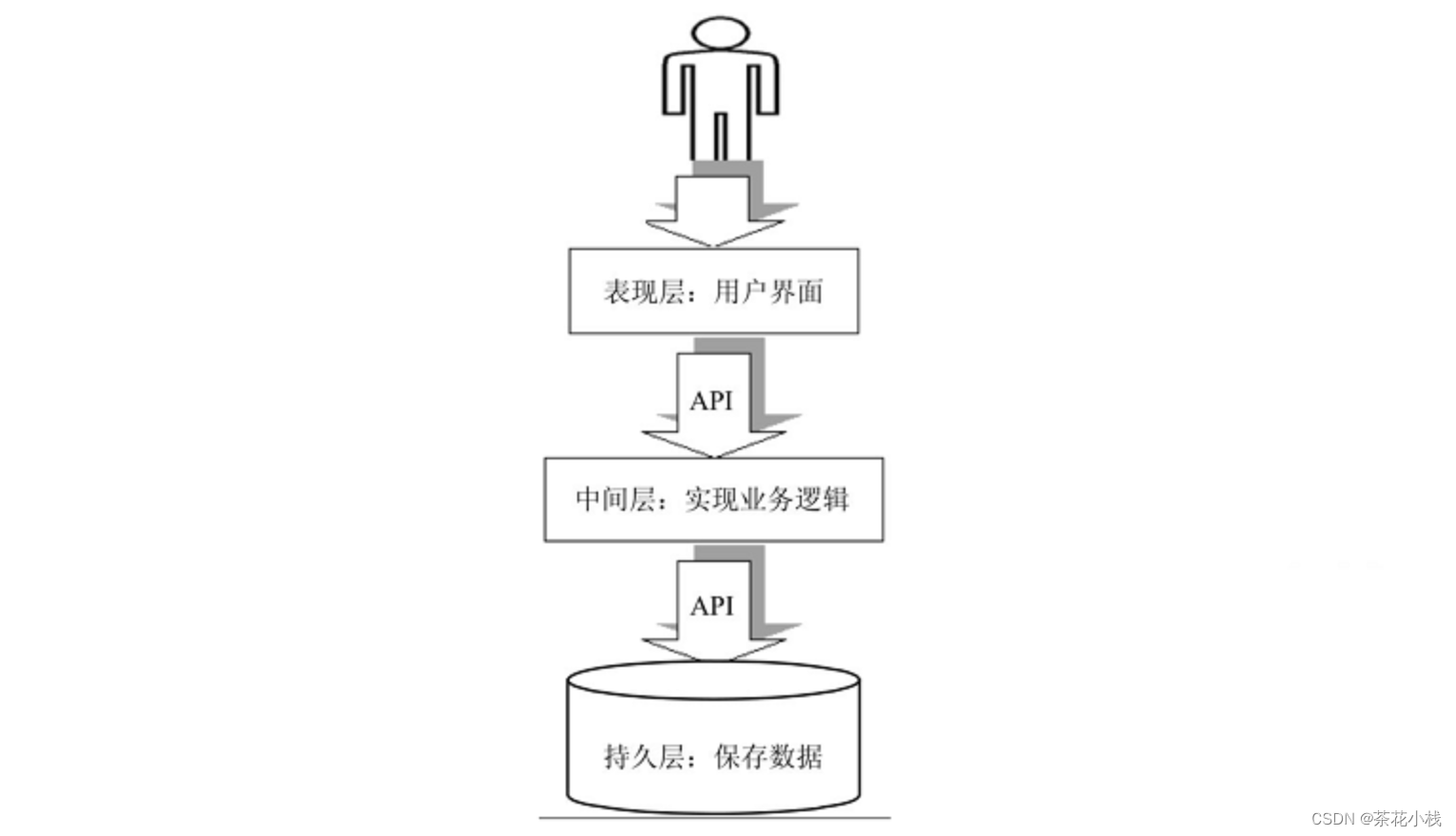
当业务逻辑层访问持久层出现SQLException异常时,程序不应该把底层的SQLException异常传到用户界面,有如下两个原因:
- 对于正常用户而言,他们不想看到底层SQLException异常,SQLException异常对他们使用该系统没有任何帮助。
- 对于恶意用户而言,将SQLException异常暴露出来不安全。
把底层的原始异常直接传给用户是一种不负责任的表现。通常的做法是:程序先捕获原始异常,然后抛出一个新的业务异常,新的业务异常中包含了对用户的提示信息,这种处理方式被称为异常转译。
假设程序需要实现工资计算的方法,则程序应该采用如下结构的代码来实现该方法。
public class MyException extends Exception {
public MyException(){
}
public MyException(String message){
super(message);
}
}
public class Test {
public static void main(String[] args) {
}
public static void calSal() throws MyException {
try {
//实现工资结算
}catch (SQLException sqle){
// 把原始异常信息记录下来,留给管理员
// ...
// 下面异常中的message就是对用户的提示
throw new MyException("访问底层数据库出现异常");
}catch (Exception e){
// 把原始异常信息记录下来,留给管理员
// ...
// 下面异常中的message就是对用户的提示
throw new MyException("系统未知异常");
}
}
}
这种把原始异常信息隐藏起来,仅向上提供必要的异常提示信息的处理方式,可以保证底层异常不会扩散到表现层,可以避免向上暴露太多的实现细节,这完全符合面向对象的封装原则。
这种把捕获一个异常然后接着抛出另一个异常,并把原始异常信息保存下来是一种典型的链式处理(23种设计模式之一:职责链模式),也被称为“异常链”。
所有Throwable的子类在构造器中都可以接收一个cause对象作为参数。这个cause就用来表示原始异常,这样可以把原始异常传递给新的异常,使得即使在当前位置创建并抛出了新的异常,你也能通过这个异常链追踪到异常最初发生的位置。如果我们希望上面的SalException可以追踪到最原始的异常信息,则可以将该方法改写为如下形式。
public class MyException extends Exception {
public MyException(){
}
public MyException(String message){
super(message);
}
// 创建一个可以接收Throwable参数的构造器
public MyException(Throwable throwable){
super(throwable);
}
}
public class Test {
public static void main(String[] args) {
}
public static void calSal() throws MyException {
try {
//实现工资结算
}catch (SQLException sqle){
// 把原始异常信息记录下来,留给管理员
// ...
// 下面异常sqle就是原始异常
throw new MyException(sqle);
}catch (Exception e){
// 把原始异常信息记录下来,留给管理员
// ...
// 下面异常e就是原始异常
throw new MyException(e);
}
}
}
创建了这个SalException业务异常类后,就可以用它来封装原始异常,从而实现对异常的链式处理。
5. Java的异常跟踪栈
异常对象的printStackTrace()方法用于打印异常的跟踪栈信息,根据printStackTrace()方法的输出结果,我们可以找到异常的源头,并跟踪到异常一路触发的过程。
public class MyException extends RuntimeException {
public MyException(){
}
public MyException(String message){
super(message);
}
}
public class Test {
public static void main(String[] args) {
firstMethod();
}
public static void firstMethod(){
secondMethod();
}
public static void secondMethod(){
thirdMethod();
}
public static void thirdMethod(){
throw new MyException("自定义异常信息");
}
}
上面程序中main方法调用firstMethod,firstMethod调用secondMethod,secondMethod调用thirdMethod,thirdMethod直接抛出一个MyException异常。
异常从thirdMethod方法开始触发,传到secondMethod方法,再传到firstMethod方法,最后传到main方法,在main方法终止,这个过程就是Java的异常跟踪栈。

在面向对象的编程中,大多数复杂操作都会被分解成一系列方法调用。这是因为:实现更好的可重用性,将每个可重用的代码单元定义成方法,将复杂任务逐渐分解为更易管理的小型子任务。由于一个大的业务功能需要由多个对象来共同实现,在最终编程模型中,很多对象将通过一系列方法调用来实现通信,执行任务。
所以,面向对象的应用程序运行时,经常会发生一系列方法调用,从而形成“方法调用栈”,异常的传播则相反:只要异常没有被完全捕获(包括异常没有被捕获,或异常被处理后重新抛出了新异常),异常从发生异常的方法逐渐向外传播,首先传给该方法的调用者,该方法调用者再次传给其调用者……直至最后传到main方法,如果main方法依然没有处理该异常,JVM会中止该程序,并打印异常的跟踪栈信息。
异常跟踪栈信息非常清晰——它记录了应用程序中执行停止的各个点。
第一行的信息详细显示了异常的类型和异常的详细消息。接下来跟踪栈记录程序中所有的异常发生点,各行显示被调用方法中执行的停止位置,并标明类、类中的方法名、与故障点对应的文件的行。一行行地往下看,跟踪栈总是最内部的被调用方法逐渐上传,直到最外部业务操作的起点,通常就是程序的入口main方法或Thread类的run方法(多线程的情形)。
虽然printStackTrace()方法可以很方便地用于追踪异常的发生情况,可以用它来调试程序,但在最后发布的程序中,应该避免使用它;而应该对捕获的异常进行适当的处理,而不是简单地将异常的跟踪栈信息打印出来。


















 5310
5310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











