









要求: 1 万条以上的京东手机评论爬取(爬取内容为评论 +score)
浏览器部分
为了一次爬取评论更多的手机所以在选取url的时候优先筛选相应品牌评论更多的款,以我爬取的vivo品牌为例:
1.筛选评论
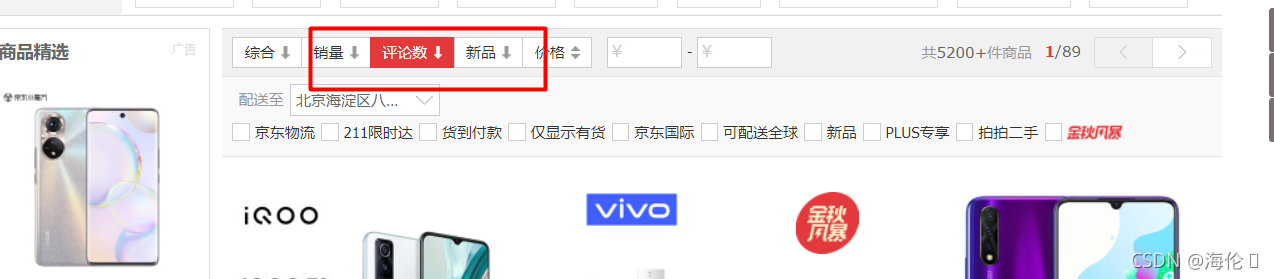
2.选择一款商品后点击对应评论
3.f12键进入调试界面
4.选择js文件格式:因为我们想要获取的评论是保留在JSON格式里面的而不是在url里面,通过检查与ctrl+F就可以发现。
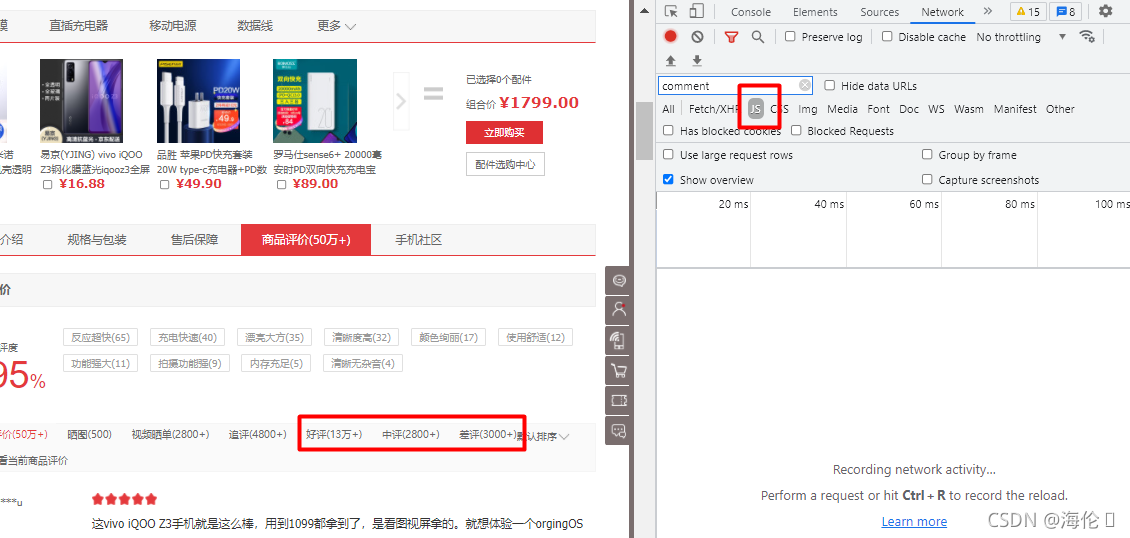
5.分别点击好评、中评、差评,就可以看到分别出现三个JSON格式文件与他们对应
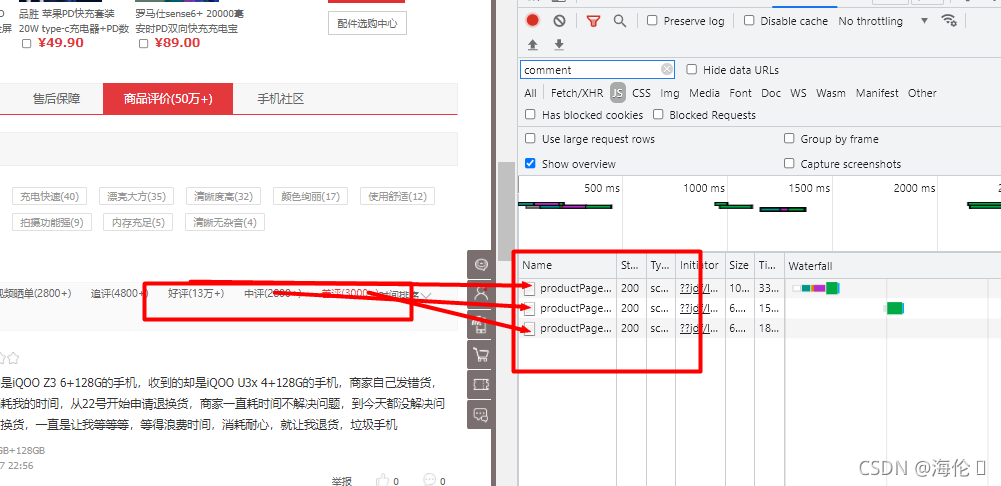
6 以好评对应JSON文件为例,点击第一个:可以看到请求url,问号之前为不带参数的url,问号之后为带参数的,我们如果调params话直接
comment_url = 'https://club.jd.com/comment/productPageComments.action'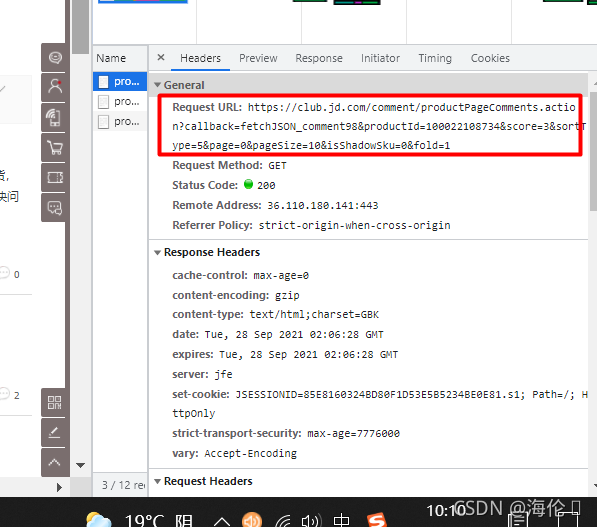
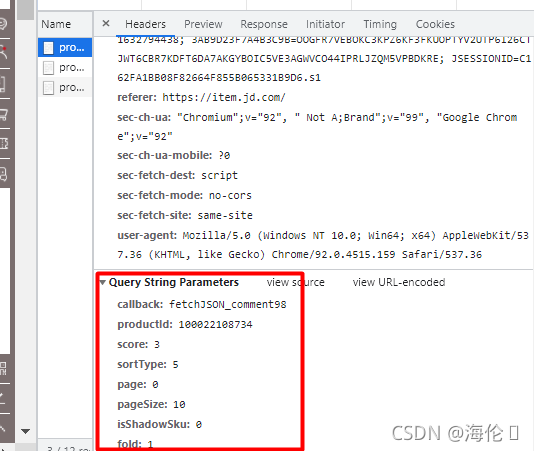
7.下滑查看参数值:直接复制过来
params = {
'productId': 100022108734, # 商品id,先写死
'score': 3,
'sortType': 5,
'page': page,
'pageSize': 10,
'callback': 'fetchJSON_comment98',
'isShadowSku': 0,
'fold': 1
}
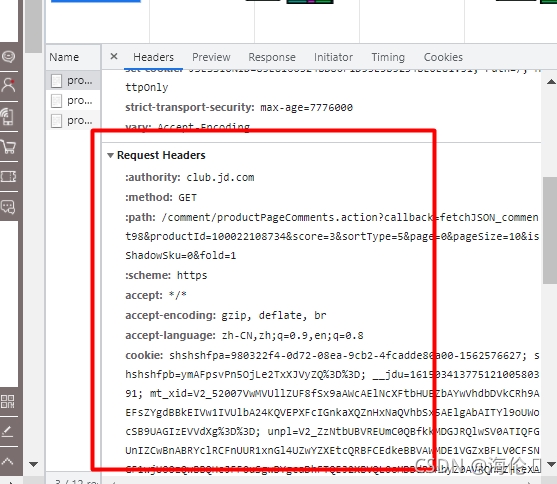
8.编写header:
headers = {
'cookie':'shshshfpa=980322f4-0d72-08ea-9cb2-4fcadde80a00-1562576627; shshshfpb=ymAFpsvPn5OjLe2TxXJVyZQ==; __jdu=16150341377512100580391; mt_xid=V2_52007VwMVUllZUF8fSx9aAWcAElNcXFtbHUEZbAYwVhdbDVkCRh9AEFsZYgdBBkEIVw1IVUlbA24KQVEPXFcIGnkaXQZnHxNaQVhbSx5AElgAbAITYl9oUWocSB9UAGIzEVVdXg==; unpl=V2_ZzNtbUBVREUmC0QBfkkMDGJRQlwSV0ATIQFGUnIZCwBnABRYclRCFnUUR1xnGl4UZwYZXEtcQRBFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHseXAFmARddQFFFEXULRlV6HVUEZQsSbXJQcyVFDENceRhbNWYzE20AAx8TcwpBVX9UXAJnBxNfR1dBE3MMRld7GF0BbgIQVUJnQiV2; PCSYCityID=CN_110000_110100_110108; user-key=0245721f-bdeb-4f17-9fd2-b5e647ad7f3e; jwotest_product=99; __jdc=122270672; mba_muid=16150341377512100580391; wlfstk_smdl=ey5hfakeb6smwvr1ld305bkzf79ajgrx; areaId=1; ipLoc-djd=1-2800-55811-0; __jdv=122270672|baidu|-|organic|not set|1632740808675; token=48ce2d01d299337c932ec85a1154c65f,2,907080; __tk=vS2xv3k1ush1u3kxvSloXsa0YznovSTFXUawXSawushwXpJyupq0vG,2,907080; shshshfp=3da682e079013c4b17a9db085fb01ea3; shshshsID=2ee3081dbf26e0d2b12dfe9ebf1ac9a8_1_1632744359396; __jda=122270672.16150341377512100580391.1615034138.1632740809.1632744359.28; __jdb=122270672.1.16150341377512100580391|28.1632744359; 3AB9D23F7A4B3C9B=OOGFR7VEBOKC3KPZ6KF3FKUOPTYV2UTP6I26CTJWT6CBR7KDFT6DA7AKGYBOIC5VE3AGWVCO44IPRLJZQM5VPBDKRE; JSESSIONID=82C0F348483686AC9A673E31126675D3.s1',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
} 
代码编写部分
1.采用解析方式:re解析(不了解同学可以看b站学习,参考链接:2021年最新Python爬虫教程+实战项目案例(最新录制)_哔哩哔哩_bilibili)
通过带参数的url查看JSON格式
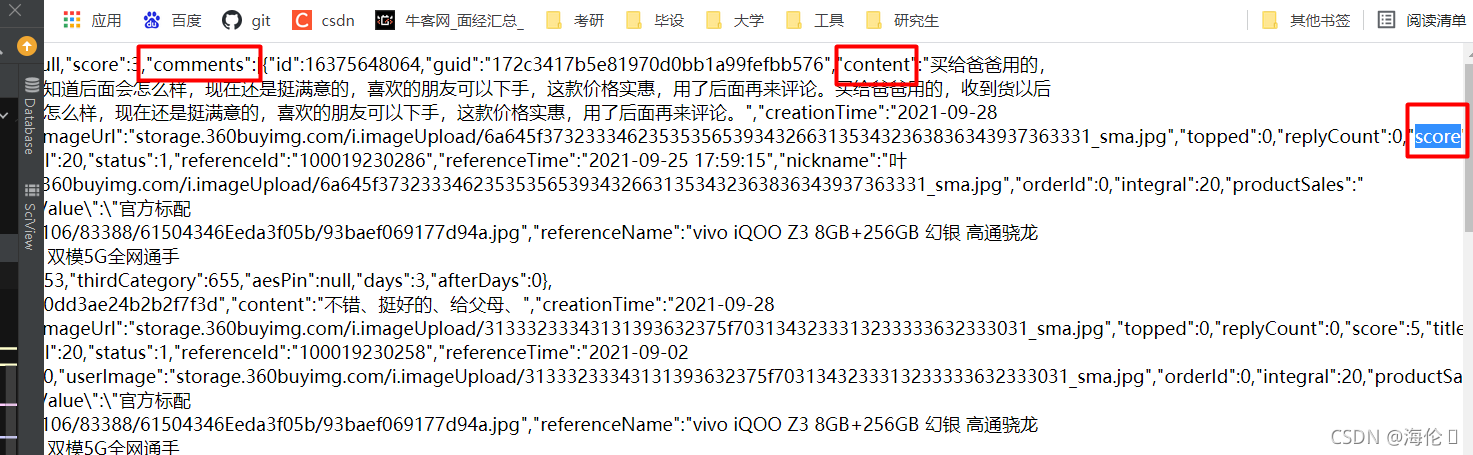
关键代码:
obj1 = re.compile(r'.*?"comments":(?P<coments>.*?)[)];', re.S)
obj2 = re.compile(r'.*?"content":"(?P<content>.*?)",".*?"score":(?P<score>.*?),"', re.S)2.去除评论中的多余字符
dic['content'] = dic['content'].replace('\\n', '').replace('…','') #去掉换行字符存入字典中3.附上完成参考代码:
import requests
import csv
import re
import time
comment_url = 'https://club.jd.com/comment/productPageComments.action'
f = open("JDcontents_vivo.csv", mode="a", encoding="utf-8", newline='')
csvwriter = csv.writer(f)
row = ('评论', '评分')
csvwriter.writerow(row)
for i in range(200):
print(i)
page = i
params = {
'productId': 100010624227, # 商品id,先写死
'score': 3,
'sortType': 6,
'page': page,
'pageSize': 10,
'callback': 'fetchJSON_comment98',
'isShadowSku': 0,
'fold': 1
}
headers = {
'cookie':'shshshfpa=980322f4-0d72-08ea-9cb2-4fcadde80a00-1562576627; shshshfpb=ymAFpsvPn5OjLe2TxXJVyZQ==; __jdu=16150341377512100580391; mt_xid=V2_52007VwMVUllZUF8fSx9aAWcAElNcXFtbHUEZbAYwVhdbDVkCRh9AEFsZYgdBBkEIVw1IVUlbA24KQVEPXFcIGnkaXQZnHxNaQVhbSx5AElgAbAITYl9oUWocSB9UAGIzEVVdXg==; unpl=V2_ZzNtbUBVREUmC0QBfkkMDGJRQlwSV0ATIQFGUnIZCwBnABRYclRCFnUUR1xnGl4UZwYZXEtcQRBFCEdkeBBVAWMDE1VGZxBFLV0CFSNGF1wjU00zQwBBQHcJFF0uSgwDYgcaDhFTQEJ2XBVQL0oMDDdRFAhyZ0AVRQhHZHseXAFmARddQFFFEXULRlV6HVUEZQsSbXJQcyVFDENceRhbNWYzE20AAx8TcwpBVX9UXAJnBxNfR1dBE3MMRld7GF0BbgIQVUJnQiV2; PCSYCityID=CN_110000_110100_110108; user-key=0245721f-bdeb-4f17-9fd2-b5e647ad7f3e; jwotest_product=99; __jdc=122270672; mba_muid=16150341377512100580391; wlfstk_smdl=ey5hfakeb6smwvr1ld305bkzf79ajgrx; areaId=1; ipLoc-djd=1-2800-55811-0; __jdv=122270672|baidu|-|organic|not set|1632740808675; token=48ce2d01d299337c932ec85a1154c65f,2,907080; __tk=vS2xv3k1ush1u3kxvSloXsa0YznovSTFXUawXSawushwXpJyupq0vG,2,907080; shshshfp=3da682e079013c4b17a9db085fb01ea3; shshshsID=2ee3081dbf26e0d2b12dfe9ebf1ac9a8_1_1632744359396; __jda=122270672.16150341377512100580391.1615034138.1632740809.1632744359.28; __jdb=122270672.1.16150341377512100580391|28.1632744359; 3AB9D23F7A4B3C9B=OOGFR7VEBOKC3KPZ6KF3FKUOPTYV2UTP6I26CTJWT6CBR7KDFT6DA7AKGYBOIC5VE3AGWVCO44IPRLJZQM5VPBDKRE; JSESSIONID=82C0F348483686AC9A673E31126675D3.s1',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
comment_resp = requests.get(url=comment_url, params=params, headers=headers)
comment_resp.close()
obj1 = re.compile(r'.*?"comments":(?P<coments>.*?)[)];', re.S)
obj2 = re.compile(r'.*?"content":"(?P<content>.*?)",".*?"score":(?P<score>.*?),"', re.S)
file_json = 'comments.json'
comment_str = obj1.finditer(comment_resp.text)
for it in comment_str:
json = it.group('coments')
print(json)
result = obj2.finditer(json)
for it in result:
#print(it.group('content'))
dic = it.groupdict() # 字典
dic['content'] = dic['content'].replace('\\n', '').replace('…','') #去掉换行字符存入字典中
csvwriter.writerow(dic.values())
print("over!")
time.sleep(5)
f.close()
如何完成一万条
因为京东评论一次性不能对同一手机爬取那么多评论,所以要不断调参来爬取同一品牌其他手机来完成一万条评论实验,为后面情感分析做好数据准备。

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









