







1.对象数据的处理:

(1)person类:
package com.mr.day05.test01;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class person implements Writable {
private String name;
private int age;
private int score;
private String sex;
public person(String name, int age, int score, String sex) {
this.name = name;
this.age = age;
this.score = score;
this.sex = sex;
}
public person() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.name);
out.writeInt(this.age);
out.writeInt(this.score);
out.writeUTF(this.sex);
}
@Override
public void readFields(DataInput in) throws IOException {
this.name = in.readUTF();
this.age = in.readInt();
this.score = in.readInt();
this.sex = in.readUTF();
}
@Override
public String toString() {
return "person{" +
"name='" + name + '\'' +
", age=" + age +
", score=" + score +
", sex='" + sex + '\'' +
'}';
}
}
(2)
package com.mr.day05.test01;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class onlymap2object01 {
public static class map01 extends Mapper<LongWritable, Text, person, NullWritable> {
person persons;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
persons=new person();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (key.get()!=0){
//String[] vsplit = value.toString().split(" ");
String vsplits=new String(value.getBytes(),0,value.getLength(),"GBK");
String[] vsplit= vsplits.split(",");
if (vsplit.length>=4){
persons.setName(vsplit[0]);
persons.setAge(Integer.valueOf(vsplit[1]));
persons.setScore(Integer.valueOf(vsplit[2]));
persons.setSex(vsplit[3]);
context.write(persons,NullWritable.get());
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS","hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(onlymap2object01.class);
job.setMapperClass(map01.class);
job.setNumReduceTasks(0);
//指定map和reduce输出数据的类型
job.setMapOutputKeyClass(person.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\01-对象数据处理\\input01"));
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\01-对象数据处理\\output01");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
job.submit();
}
}
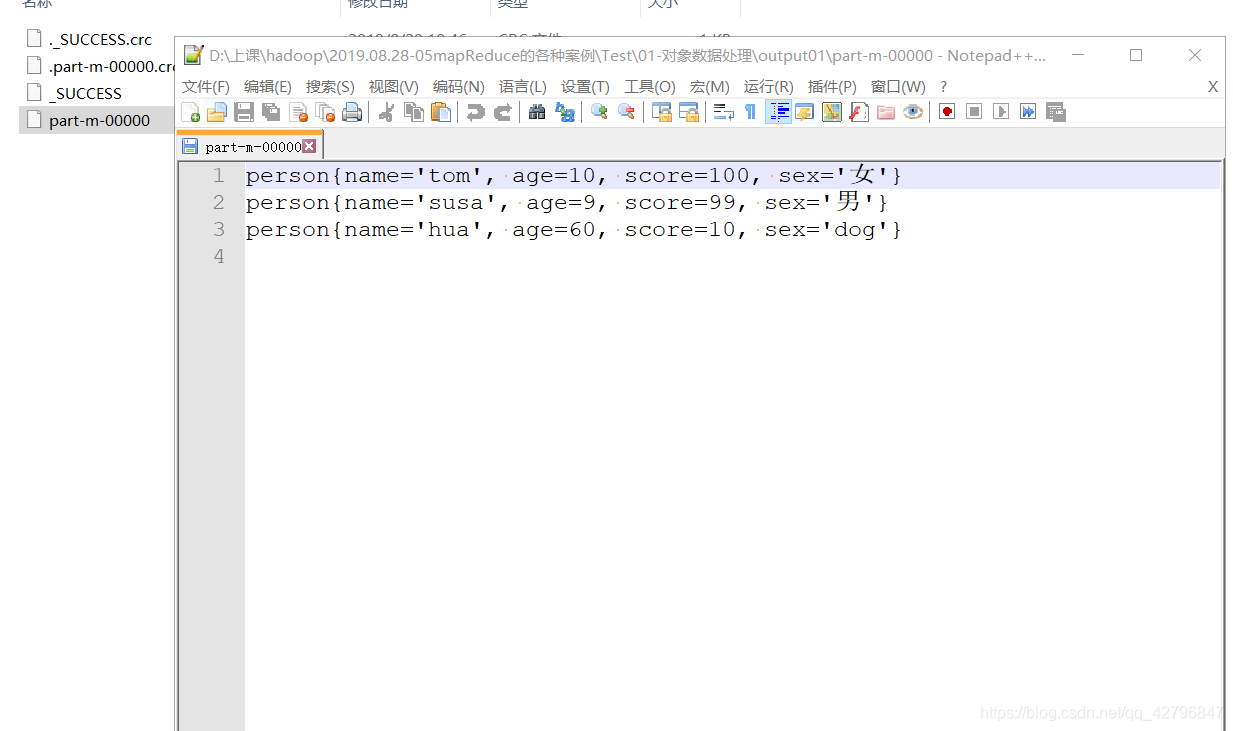
结果图:
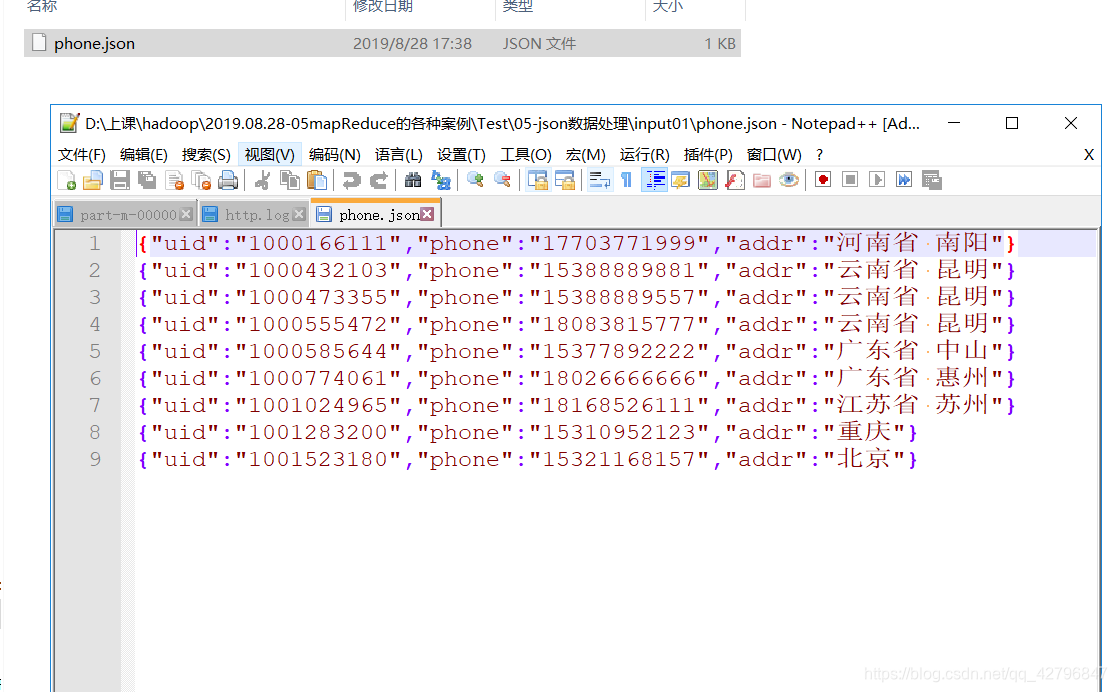
2.json数据处理
package com.mr.day05.test05;
public class Phone {
private long uid;
private long phone;
private String addr;
public long getUid() {
return uid;
}
public void setUid(long uid) {
this.uid = uid;
}
public long getPhone() {
return phone;
}
public void setPhone(long phone) {
this.phone = phone;
}
public String getAddr() {
return addr;
}
public void setAddr(String addr) {
this.addr = addr;
}
public Phone(long uid, long phone) {
this.uid = uid;
this.phone = phone;
}
public Phone() {
}
@Override
public String toString() {
return "Phone{" +
"uid=" + uid +
", phone=" + phone +
", addr='" + addr + '\'' +
'}';
}
}
package com.mr.day05.test05;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.codehaus.jackson.map.ObjectMapper;
import java.io.IOException;
public class ReadJson2Object {
public static class ReadJson2ObjectMapper extends Mapper<LongWritable, Text,Phone, NullWritable> {
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=new String(value.getBytes(),0,value.getLength(),"GBK");
ObjectMapper objectMapper = new ObjectMapper();
Phone phone = objectMapper.readValue(line, Phone.class);
context.write(phone,NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(ReadJson2Object.class);
job.setMapperClass(ReadJson2ObjectMapper.class);
job.setOutputKeyClass(Phone.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job,new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\05-json数据处理\\input01"));
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\05-json数据处理\\output01");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
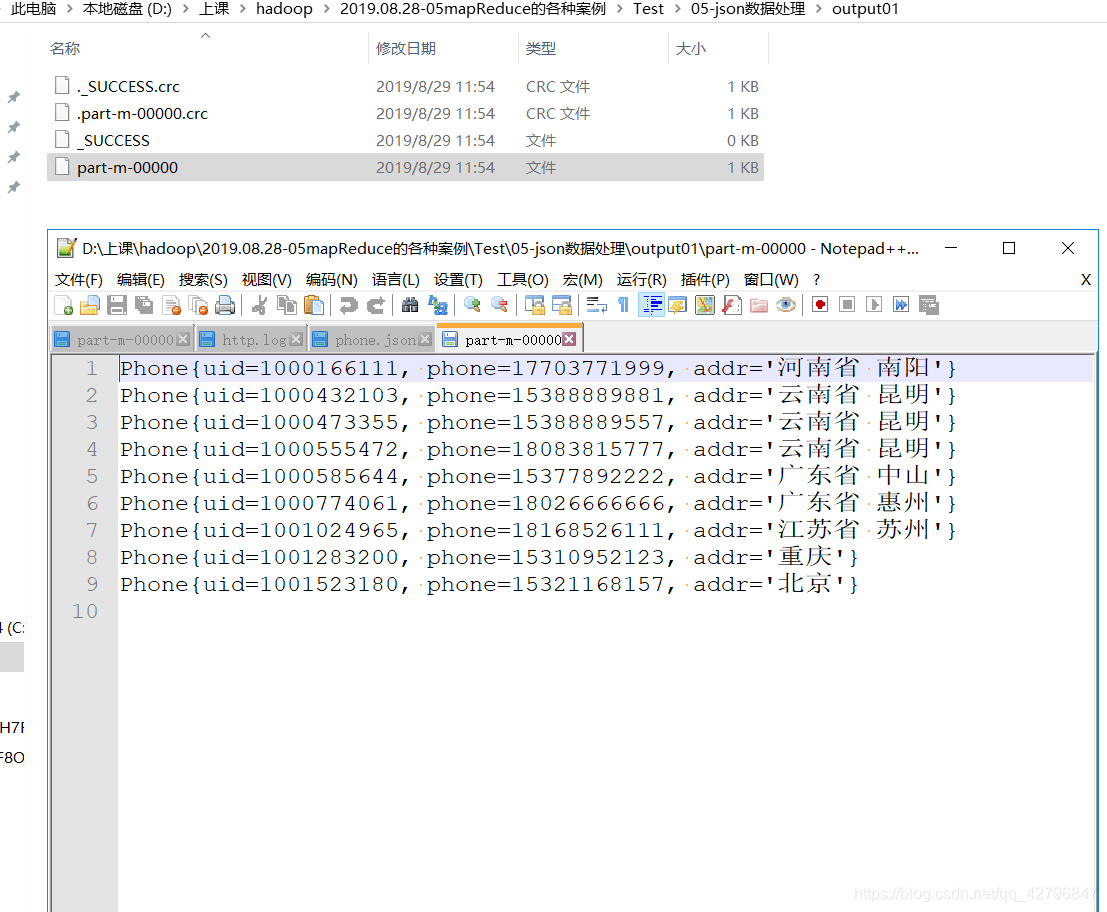
结果图:
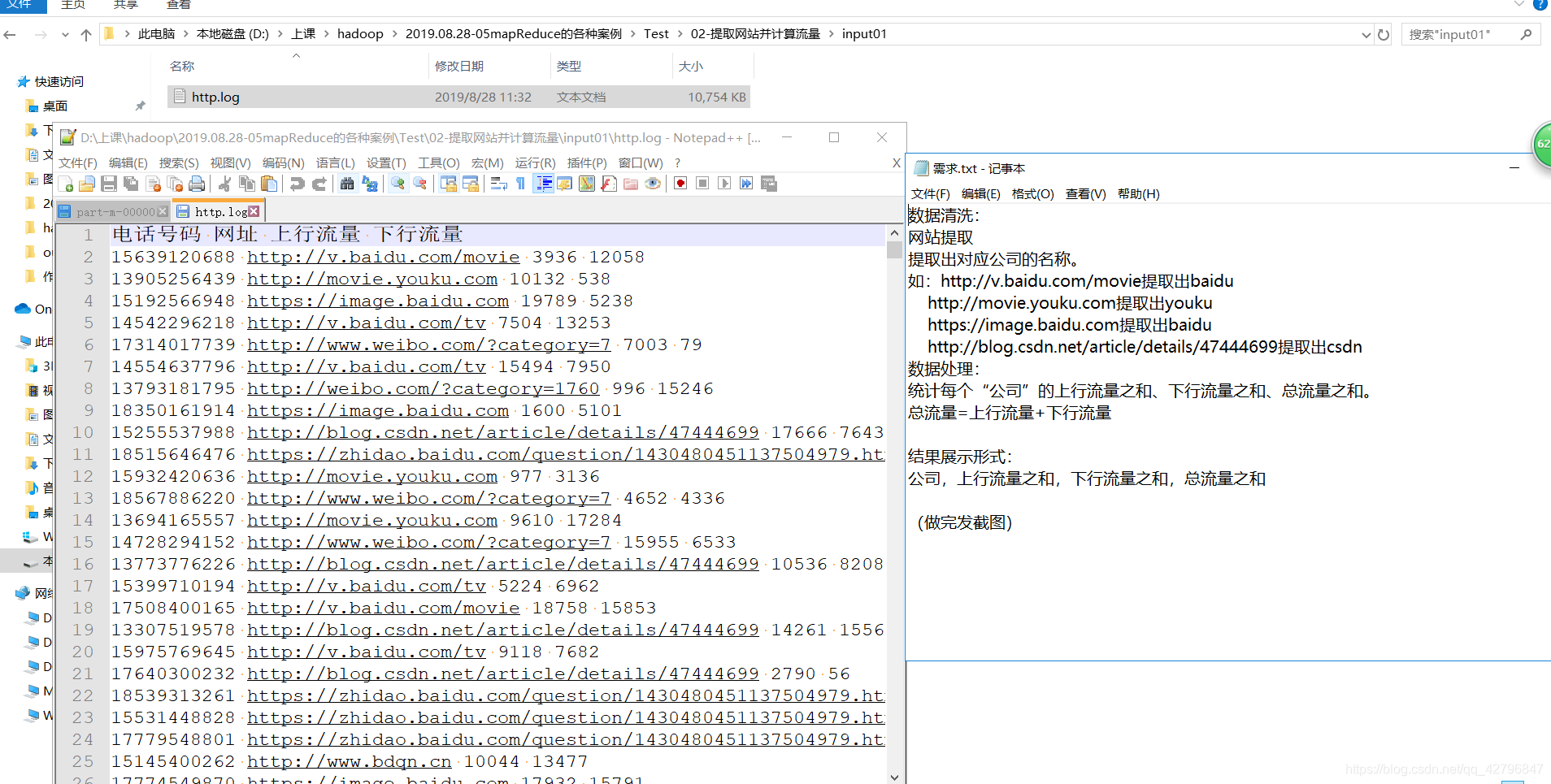
3.提取网站并计算流量
package com.mr.day05.test02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class mrtest02 {
public static class map01 extends Mapper<LongWritable, Text, Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (key.get()!=0){
String[] split1 = value.toString().split("//");
String[] split2 = split1[1].split("/");
String[] name = split2[0].split("[.]");
String[] fls = value.toString().split(" ");
String fl = fls[2];
String f2 = fls[3];
context.write(new Text(name[name.length-2]),new Text(fl+" "+f2));
}
}
}
public static class reduce01 extends Reducer<Text,Text,Text,Text> {
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int ssum=0;
int xsum=0;
int zsum=0;
for (Text unm: values){
String[] s = unm.toString().split(" ");
ssum+=Integer.valueOf(s[0]);
xsum+=Integer.valueOf(s[1]);
}
zsum=ssum+xsum;
context.write(key,new Text(ssum+","+xsum+","+zsum) );
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS","hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(mrtest02.class);
job.setMapperClass(map01.class);
job.setReducerClass(reduce01.class);
//指定map和reduce输出数据的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job,new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\02-提取网站并计算流量\\input01"));
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\02-提取网站并计算流量\\output01");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
job.submit();
}
}
结果图:

4.分组TopN:

(1.Student类继承WritableComparable自定义排序)
package com.mr.day05.test03;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Student implements WritableComparable<Student> {
private String name;
private String subject;
private double avescore;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSubject() {
return subject;
}
public void setSubject(String subject) {
this.subject = subject;
}
public double getAvescore() {
return avescore;
}
public void setAvescore(double avescore) {
this.avescore = avescore;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.name);
dataOutput.writeUTF(this.subject);
dataOutput.writeDouble(this.avescore);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.name=dataInput.readUTF();
this.subject=dataInput.readUTF();
this.avescore=dataInput.readDouble();
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", subject='" + subject + '\'' +
", avescore=" + avescore +
'}';
}
@Override
public int compareTo(Student s) {
if (s.getAvescore()==this.getAvescore()){
return s.getName().compareTo(this.getName());
}else {
return s.getAvescore() >this.getAvescore() ? 1:-1;
}
}
}
(2.重写Partitioner定义分区)
package com.mr.day05.test03;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.*;
public class SubjectPadrtitioner extends Partitioner <Student, NullWritable>{
// Map<String,Integer> map=new HashMap<String,Integer>();
List<String> list=new ArrayList<>();
@Override
public int getPartition(Student student, NullWritable nullWritable, int numPartitions) {
/* map.put("computer",0);
map.put("english",1);
map.put("algorithm",2);
map.put("math",3);
return map.get(student.getSubject());*/
System.out.println(student);
if (list.contains(student.getSubject())){
return list.indexOf(student.getSubject());
}else {
list.add(student.getSubject());
return list.indexOf(student.getSubject());
}
}
}
(3)
package com.mr.day05.test03;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class mrtest3 {
public static class map03 extends Mapper<LongWritable, Text,Student, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] vsplit = value.toString().split(",");
if (vsplit.length>=3){
Student student = new Student();
Double sum=0.0;
int num = vsplit.length - 2;
for (int i=2;i<vsplit.length;i++){
sum+=Double.valueOf(vsplit[i]);
}
Double avescore=sum/num;
student.setSubject(vsplit[0]);
student.setName(vsplit[1]);
student.setAvescore(avescore);
//System.out.println(student);
context.write(student,NullWritable.get());
}
}
}
public static class Reduce03 extends Reducer<Student,NullWritable,Student, NullWritable> {
protected void reduce(Student key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//System.out.println(key);
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//conf.set("fs.defaultFS","hdfs://master:9000");
Job job = Job.getInstance(conf);
job.setJarByClass(mrtest3.class);
job.setMapperClass(map03.class);
job.setReducerClass(Reduce03.class);
job.setNumReduceTasks(4);
job.setPartitionerClass(SubjectPadrtitioner.class);
//指定map和reduce输出数据的类型
job.setMapOutputKeyClass(Student.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Student.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\03-分组TopN\\input01"));
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\03-分组TopN\\output01");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
job.submit();
}
}
结果图:
1
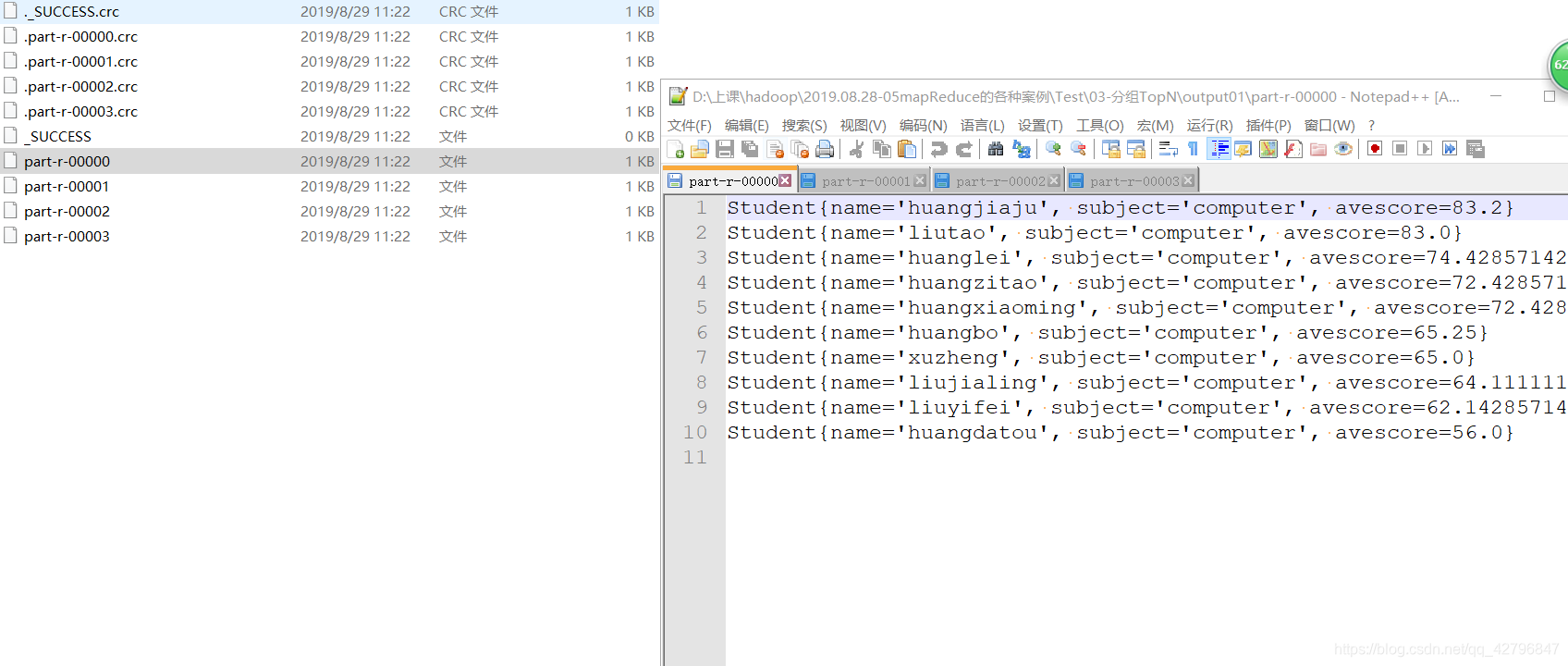
2

3

4

5.MapjoinTest
小表:

大表(小连大)
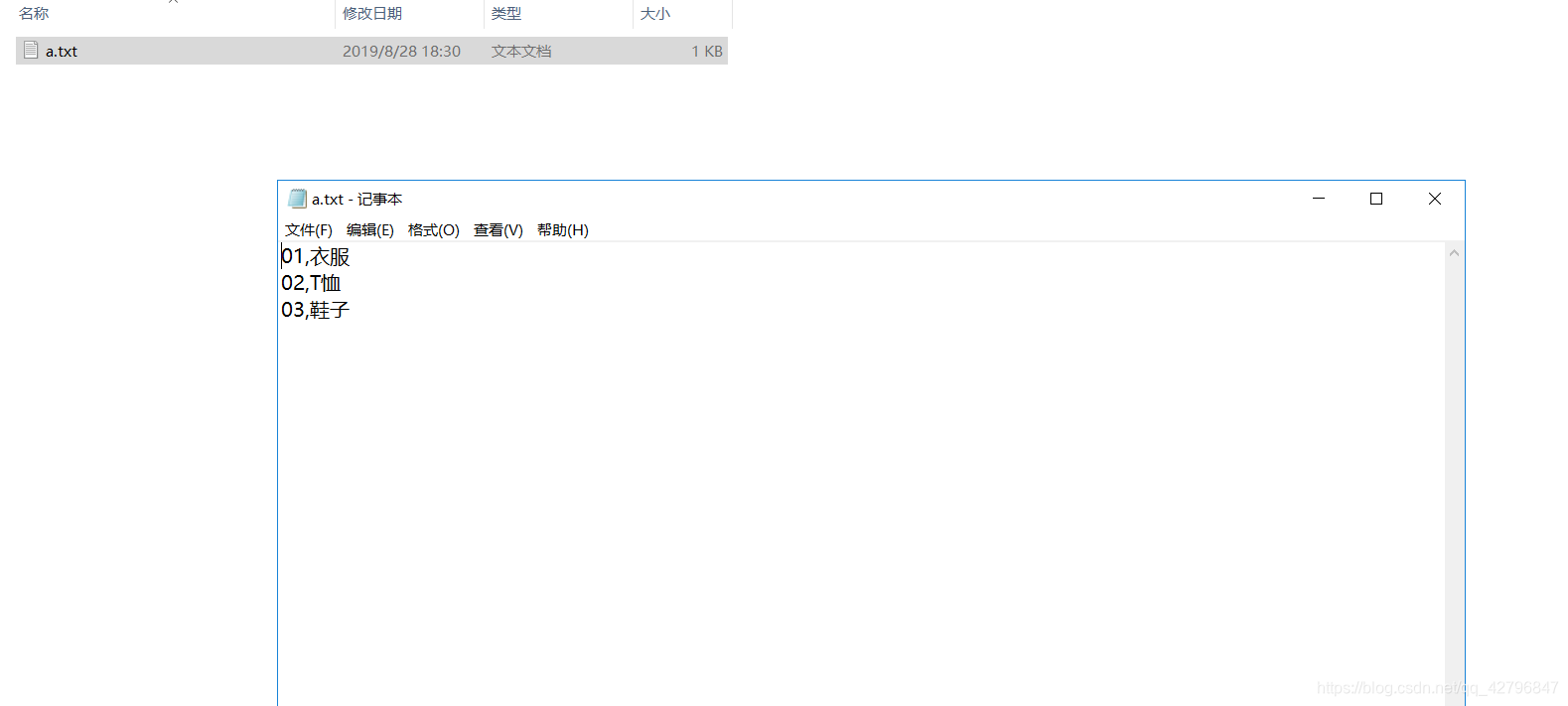
package com.mr.day05.test04;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class MapJoinTest04 {
public static class MapJoinTestMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
Map<String,String> goodsMap = new HashMap<String,String>();
protected void setup(Context context) throws IOException, InterruptedException {
BufferedReader br = new BufferedReader(new FileReader("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\04-MapjoinTest\\input01\\小表\\b.txt"));
String line = "";
while (StringUtils.isNotBlank(line=br.readLine())){
String[] split = line.split(",");
if (split.length>=2){
goodsMap.put(split[0],split[1]);
}
}
}
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String vsplits=new String(value.getBytes(),0,value.getLength(),"GBK");
String[] split = vsplits.split(",");
if (split.length>=2){
String goodInfo = goodsMap.get(split[0]);
context.write(new Text(split[0]+ ","+split[1]+","+goodInfo),NullWritable.get());
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MapJoinTest04.class);
job.setMapperClass(MapJoinTestMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setNumReduceTasks(0);
// job.addCacheFile(new URI("hdfs://B01master:9000/join/cache/user.txt"));
FileInputFormat.setInputPaths(job,new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\04-MapjoinTest\\input01\\inout01"));
FileSystem fs = FileSystem.get(conf);
Path outPath = new Path("D:\\hadoop\\2019.08.28-05mapReduce的各种案例\\Test\\04-MapjoinTest\\input01\\outout01");
if (fs.exists(outPath)){
fs.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
结果图:
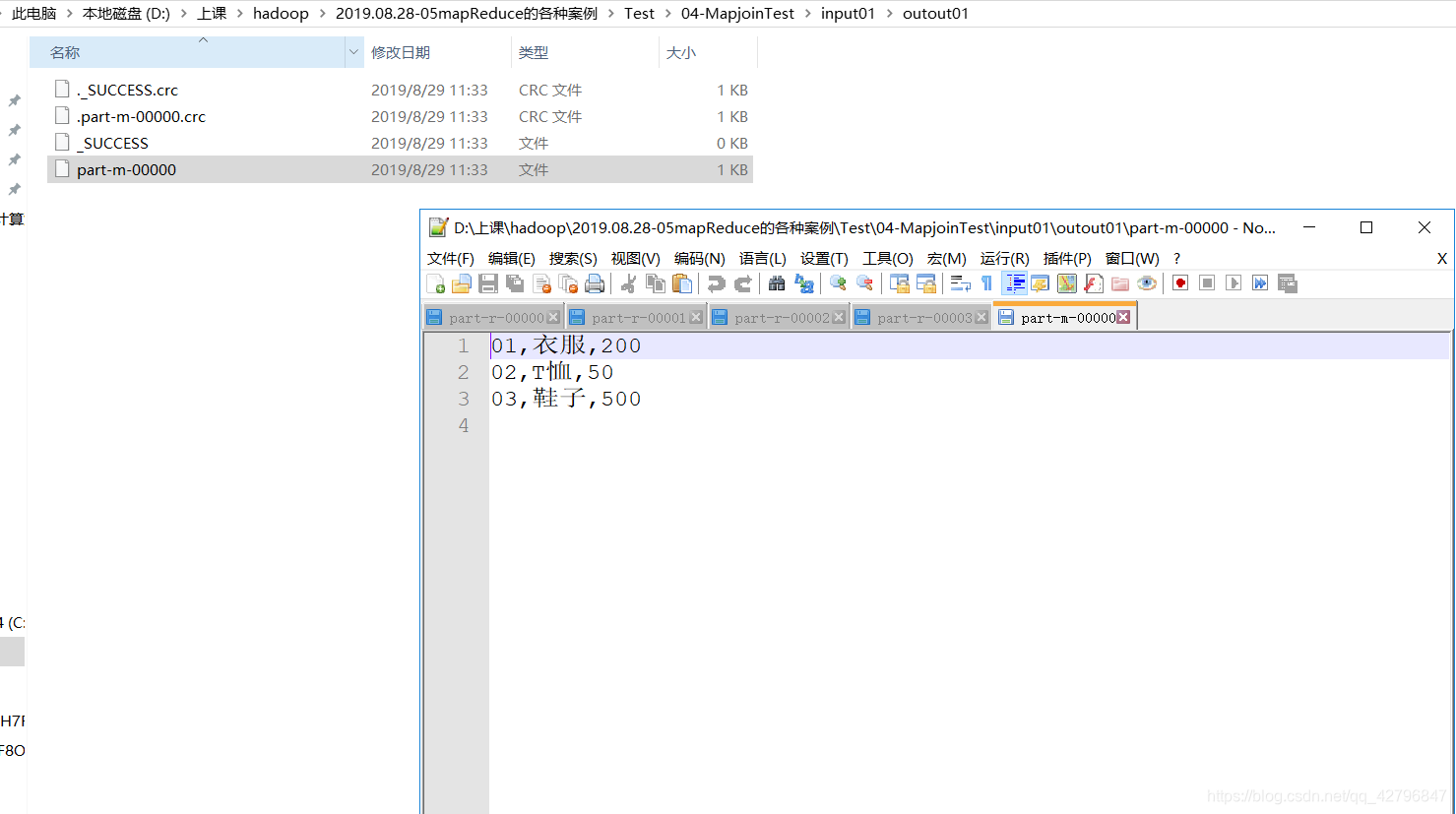














 223
223











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









