







高阶函数和内存分析
- 函数式编程最鲜明的特点就是,函数属于first class,就是说函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数。或者作为别的函数的返回值。
- 一个函数可以接收另一个函数作为参数,这种函数就称为高阶函数
- Python内建的高阶函数由map,reduce,filter,sorted
def test():
print("test")
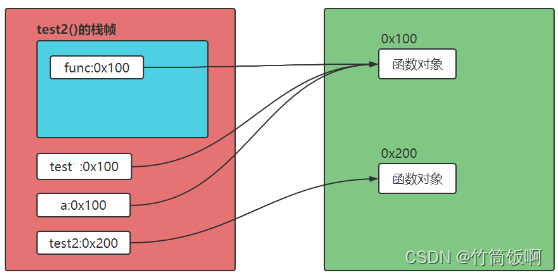
def test2(func):
"""
test2就是一个高阶函数
:param func:
:return:
"""
func()
print("tets2")
if __name__ == '__main__':
print(test)
print(type(test))
a = test # a和test都指向了同一个函数对象
a()
test2(a) # a作为参数传递给test2
"""
运行结果
<function test at 0x000001BCC6B2E280>
<class 'function'>
test
test
tets2
"""内存分析
lambda表达式和匿名函数
lambda表达式可以用来声明匿名函数。lambda函数是一种简单的、在同一行中定义函数的方法。lambda函数实际上生成了一个函数对象。lambda表达式只允许包含一个表达式,不能包含复杂语句,该表达式的计算结果就是函数的返回值。lambda表达式的基本语法如下:
lambda arg1,arg2,arg3...:表达式f = lambda a,b,c:a+b+c
print(f)
print(f(1,2,3))
g = [lambda a:a,lambda b:b*2,lambda c:c*3]
print(g[0](6),g[1](7),g[2](8))
"""
运行结果
<function <lambda> at 0x000001783C3CB820>
6
6 14 24
"""偏函数
Python中functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。
偏函数:作用就是把一个函数某些参数固定住(也就是设置默认值),返回一个新的函数,调用这个新的函数会更简单。如:int()函数可以把字符串转换成整数,当仅传入字符串时,int()函数默认按十进制转换。但int()还提供额外的base参数,默认值为10.如果传入base参数,就可以做到N进制的转换:
print("转换为八进制",int('123',base=8))
print("转换为十六进制",int('123',base=16))如果要大量转换二进制字符串,每次传入int(x,base=2)比较麻烦,于是可以定义一个int2()的函数,默认base=2
def int2(x,base=2):
return int(x,base)
print(int2('100000'))
print(int2('10101'))
"""
运行结果
32
21
"""functools.partial就可以帮助我们创建一个偏函数,不需要定义int2()
import functools
int2 = functools.partial(int,base=2)
print(int2("100"))
print(int2("101"))
print(int2("100",base=10)) # 也可以覆盖base的值
"""
运行结果
4
5
100
"""闭包closure
函数的作用域时独立的、封闭的,外部的执行环境访问不了,但是闭包具有这个能力和权限。闭包时一个函数,但是闭包这个函数可以访问到另一个函数的作用域。函数和自由变量的总和就是一个闭包。
闭包的特点:
- 存在内外层函数嵌套的情况
- 内层函数引用了外层函数的变量或参数
- 外层函数把内层函数这个函数本省作为返回值返回
def outer():
print("outer")
def inner():
# nonlocal a
print("inner")
return inner
a = outer()
print("===========*3")
a()
print("===========*3")
b = outer
print("===========*3")
b()
"""
运行结果:
outer
===========*3
inner
===========*3
===========*3
outer
"""def outer():
print("outer")
a = 1
def inner():
nonlocal a
print("inner")
print(f"a:{a}") # a为自由变量
a += 1
return inner
x = outer()
print("===========*3")
x()
"""
运行结果:
outer
===========*3
inner
a:1
"""闭包的作用:
- 隐藏变量,避免全局污染
- 可以读取函数内部的变量
闭包使用不当,优点会编程缺点:
- 导致变量不会被垃圾回收机制回收,造成内存消耗
- 不恰当使用闭包可能会造成内存泄漏的问题
闭包和自由变量
例1:使用全局变量实现变量自增,但污染了其他程序
a = 10
def add():
global a
a += 1
print("a:",a)
def print_ten():
if a==10:
print("a:ten")
else:
print("全局变量a,不等于10")
add()
add()
add()
print_ten()
"""
运行结果:
a: 11
a: 12
a: 13
全局变量a,不等于10
"""例2:定义局部变量,不污染,但无法递增
a = 10
def add():
a = 10
a += 1
print("a:",a)
def print_ten():
if a==10:
print("a:ten")
else:
print("全局变量a不等于10")
add()
add()
add()
print_ten()
"""
运行结果:
a: 11
a: 11
a: 11
a:ten
"""例3:通过闭包,可以实现函数内部局部变量递增,不影响全局变量
a = 10
print("全局变量a:",id(a))
def add():
a = 10
print("add中的a:",id(a))
def increment():
nonlocal a
print("increment中的a:",id(a))
a += 1
print("a:",a)
return increment
def print_ten():
if a==10:
print("a:ten")
else:
print("全局变量a不等于10")
print("========"*3)
increment = add()
print("========"*3)
increment()
increment()
increment()
print_ten()
print(id(a))
print("global a:",a)
"""
运行结果:
全局变量a: 1356532443728
========================
add中的a: 1356532443728
========================
increment中的a: 1356532443728
a: 11
increment中的a: 1356532443760
a: 12
increment中的a: 1356532443792
a: 13
a:ten
1356532443728
global a: 10
"""Map函数的使用
map()函数接收两种参数,一是函数,一种是序列(可传入多个序列),map将传入的函数依次作用到序列的每一个元素,并把结果作为新的list返回。
不使用map实现:
# 不使用map
def f(x):
return x*x
L = []
for n in [1,2,3,4,5,6,7,8,9]:
L.append(f(n))
print(L)
"""
运行结果:
[1, 4, 9, 16, 25, 36, 49, 64, 81]
"""使用map实现:
# 使用map
def f(x):
return x*x
L = map(f,[1,2,3,4,5,6,7,8,9])
print(list(L))
"""
运行结果:
[1, 4, 9, 16, 25, 36, 49, 64, 81]
"""匿名函数+map函数:
L = map(lambda n:n*n,[1,2,3,4,5,6,7,8,9])
print(list(L))
"""
运行结果:
[1, 4, 9, 16, 25, 36, 49, 64, 81]
"""map函数传入两个列表:
def f(x,y):
return x+y
L = map(f,[1,2,3,4],[10,20,30])
print(list(L))
"""
运行结果:
[11, 22, 33]
"""map函数传入两个列表+匿名函数
L = map(lambda x,y:x+y,[1,2,3,4],[10,20,30])
print(list(L))
"""
运行结果:
[11, 22, 33]
"""reduce函数
reduce位于functools模块。reduce把一个函数作用在一个序列上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算。
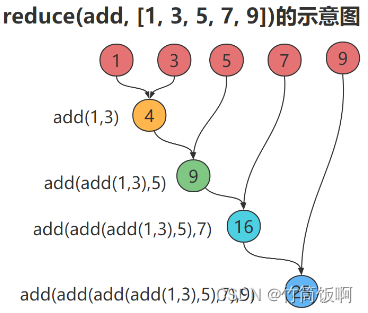
reduce实现对一个序列求和
from functools import reduce
def add(x,y):
return x+y
sum = reduce(add,[1,2,3,4,5])
print(sum) # 15
filter函数
内置filter()用于过滤序列。filter()把传入的函数依次作用域每个元素,然后根据返回值是True或False决定保留还是丢弃该元素。
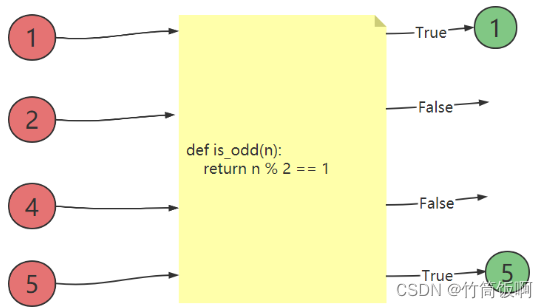
# 过滤掉偶数
def is_odd(n):
return n%2==1
L = filter(is_odd,[1,2,3,4,5])
print(list(L)) # [1,3,5]
# 匿名函数实现
L = filter(lambda n:n%2==1,[1,2,3,4,5])
print(list(L))# 删除空字符串
def not_empty(s):
return s and s.strip()
L = filter(not_empty,['A','','B',None,'c','d',' '])
print(list(L)) # ['A', 'B', 'c', 'd']
# 匿名函数实现
L = filter(lambda s:(s and s.strip()),['A','','B',None,'c','d',' '])sorted函数
sorted()函数是一个高阶函数,可以接收一个key函数来实现自定义排序。
list0 = [1,5,3,12,0,-10,66]
list1 = sorted(list0)
print("升序:",list1)
list2 = sorted(list0,key=abs)
print("key=abs:",list2)
list3 = sorted(list0,key=abs,reverse=True)
print("key=abs+reverse:",list3)
list_0 = ["a","ab","abcde","abc","D","A"]
list_1 = sorted(list_0)
print("字符串:",list_1)
list_2 = sorted(list_0,key=str.lower) # 用upper也是一样的效果
print("忽略大小写排序:",list_2)
list_3 = sorted(list_0,key=str.upper,reverse=True)
print("忽略大小写排序,反向:",list_3)
"""
运行结果:
升序: [-10, 0, 1, 3, 5, 12, 66]
key=abs: [0, 1, 3, 5, -10, 12, 66]
key=abs+reverse: [66, 12, -10, 5, 3, 1, 0]
字符串: ['A', 'D', 'a', 'ab', 'abc', 'abcde']
忽略大小写排序: ['a', 'A', 'ab', 'abc', 'abcde', 'D']
忽略大小写排序,反向: ['D', 'abcde', 'abc', 'ab', 'a', 'A']
"""
sorted对自定义对象的排序
from functools import cmp_to_key
class Student:
def __init__(self,age,name):
self.age = age
self.name = name
def custom_sorted(stu1,stu2):
if stu1.age < stu2.age:
return -1
if stu1.age > stu2.age:
return 1
return 0
stu0 = Student(25,'张三')
stu1 = Student(16,'坤坤')
stu2 = Student(28,'archer')
stu_list = sorted([stu0,stu1,stu2],key=cmp_to_key(custom_sorted))
for stu in stu_list:
print(f"name:{stu.name},age:{stu.age}")
"""
运行结果:
name:坤坤,age:16
name:张三,age:25
name:archer,age:28
"""














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









