









Dialogue State Tracking with a Language Model using Schema-Driven Prompting
——prompt在对话系统上的应用
1. Idea
第一眼看到题目,就蹦出了几个问题
-
什么是dialogue state tracking?
答: The backbone module of a typical system is dialogue state tracking (DST), where the user goal is inferred from the dialogue history. 对话系统中用于判断用户目标的骨干模型。
-
啥是schema-driven prompting?
答:也就是通过schema description模式描述来增强prompt从而提高性能
We further improve performance by augmenting the prompting with schema descriptions, a naturally occurring source of in-domain knowledge.
-
除了schema-driven prompting,还有别的方法可以对dialogue state tracking进行改进吗?
答:查到一篇论文(Dialog State Tracking with Reinforced Data Augmentation)
-
文中涉及到了categorical和non-categorical具体指啥?
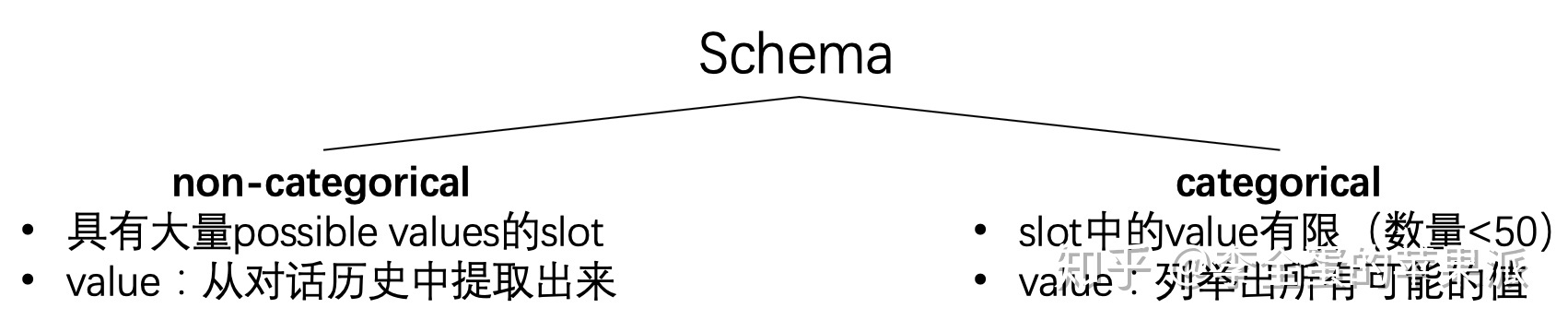
schema将所有slot分成两类,一类叫做non-categorical,一类叫做categorical。
non-categorical包括那些具有大量可能的value的slot,schema中对这些slot不去预定义一个value的list,对于这类slot的value是从对话历史中提取出来的。
categorical包含了那些value有限的slot,以及在训练数据中具体value数量少于50个的slot。在schema里头对这类slot会列举出所有可能的value。
2. Motivation
通常使用特定于特殊目的分类器的特定任务架构来进行面向任务的对话系统的实现。而最近使用基于预先训练过的语言模型的更通用的架构已经取得了良好的结果,因此本文提出了语言建模方法的一种新变体,使用模式驱动的提示schema-driven prompting来提供任务感知的历史编码,进一步将自然语言模式描述合并到DST的提示中,用于分类和非分类槽。
同时也提出一个假设:联合编码对话上下文和模式特定的文本信息可以进一步有利于sequence to sequence的DST模型,有利于任务感知的上下文语境化,从而更有效地指导解码器生成插槽值。
3. Method

这幅图很直接地展示了文章所用的Method,虚线以上是是DST的三种解码形式,而本文所用的是©自然语言增强的prompt。虚线以下展示了本文的方法。
-
增加了域相关提示( X ( d m ) X(d_m) X(dm))和插槽相关提示( X ( s n ) X(s_n) X(sn))
-
提示增强输入 H t = E n c o d e r ( C t , X ( d m ) , X ( s n ) ) H_t=Encoder(C_t,X(d_m),X(s_n)) Ht=Encoder(Ct,X(dm),X(sn)),其中 H t ∈ R L × k H_t∈R^{L×k} Ht∈RL×k是编码器的隐藏状态,L为输入句子的长度,k为编码器的隐藏大小。解码器在编码器隐藏状态的基础上解码出相关的槽值 B t ( d m , s n ) = D e c o d e r ( H t ) B_t(d_m,s_n)=Decoder(H_t) Bt(dm,sn)=Decoder(Ht)
-
该生成处理的总体目标就是给定 C t , X ( d m ) , X ( s n ) C_t,X(d_m),X(s_n) Ct,X(dm),X(sn)的情况下最大化 B t ( d m , s n ) B_t(d_m,s_n) Bt(dm,sn)的似然数$\sum_{(m,n)} \log P(B_t(d_m,s_n)|C_t,X(d_m),X(s_n)) $,也就是在每个解码步骤中,只预测给定模型词汇表中最有可能的token。
-
然后基于符号的提示符(分类槽的可能值列表)输入作为双向编码器的额外输入,潜在地实现具有任务感知功能的上下文化。
-
其中,用来自预训练的LM的权重进行初始化,采用T5作为主干序列到序列的模型。
4. Experiments
4.1 MultiWOZ 2.2: Fully Annotated Natural Language Augmented Prompt

- 基于T5-small and T5-base预训练模型sequential解码策略比independent解码策略低超过5%
- 本文提出的方法(描述的增强/数据增强)在T5-small and T5-base预训练模型上,提高了1%的JGA
4.2 MultiWOZ 2.1: Partially Annotated Natural Language Augmented Prompt

- T5-base 表现比 T5-small 好,且使用了description的模型能够有效提高性能,
- 所有的模型都优于不使用额外对话数据baseline模型。值得注意的是,与MinTL(T5-small)相比,本文的模型即使没有描述的情况也提高了4%以上
- 本方法也优于MinTL( BART-LARGE)方法,虽然都用了sequence to sequence 方法,MinTL( BART-LARGE)的域信息只对应输出解码器,而本文方法通过在编码器侧提示具有域和槽信息的LM来实现任务感知上下文化。这也意味着模式驱动的提示是有效的。
- 与MultiWOZ2.2相比,增强自然语言描述所带来的性能增益不那么明显,这可能是由于MultiWOZ2.1描述中可用的信息减少造成的。
4.3 M2M: Borrowed Natural Language Augmented Prompt

- 本方法在Sim-R和Sim-M+R上实现了SOTA性能,同时在Sim-M上具有可比性。
4.4 Analysis
除此之外,本文也进行了相关的分析(这里就不放图了)
- Breakdown Evaluation for MultiWOZ:对于T5-small和T5-base模型,分类和非分类槽的sequential解码器比独立解码模型差。独立的解码模型在分类槽上取得了更明显的改进,这表明任务特定的提示对指导解码器预测有效值非常有帮助。使用自然语言描述的模型和不使用自然语言描述的模型时,我们观察到两种类型的槽的性能提高。
- Ablation Study on Schema Descriptions:烧灼实验从以下三点进行考虑:① 排除分类插槽的可能值的列表的可能性;②排除插槽描述;③不包括域描述。证明了值集value可以成功地约束模型输出。
- The Effectiveness of Natural Language Augmented Prompt:重点分析了描述增强模型正确跟踪对话状态和未增强模型的对话状态失败的例子,从而证明增强模型的优点。
- Error Analysis of Natural Language Augmented Prompt-based DST:对错误原因进行了分析:① 最常见的错误类型是注释错误,其中模型预测实际上是正确的;② 20%的错误来自于模型未能捕获系统提供的信息;③ 16.66%的误差是由于模型中至少有一个gold slots缺失造成的。(iv)10%的误差是正确的插槽预测和错误的对应值。一般来说,大多数错误很可能是由于缺乏对用户-系统交互的显式建模而造成的。
5. conclusion
本文主要提出了一个基于大规模预训练LM的任务导向对话系统。通过将对话状态跟踪任务重新定义为提示LM的知识,该模型可以受益于知识丰富的序列到序列T5模型。在实验中,所提出的基于自然语言增强提示的DST模型在MultiWOZ2.2上实现了SOTA,在MultiWOZ2.1和M2M上的性能与最近的SOTA模型的性能相当。此外,本文分析提供了证据,表明自然语言提示被有效地用来约束模型的预测,也验证了所提出的假设。
6. Thinking
-
这篇与师兄提的想法有点像,基于prompt改进DST。
-
说实话,感觉contribution不是很突出,就是基于现有的方式,对DST中prompt方式的输入中增加了一个基于符号的表述natural language description
-
但文章的思路可以学习一下,每一个方法所用的原因都有相应的解释,很清晰
使用generation-based的原因
DST主要有两个范式:classification-based 和 generation-based model
- classification-based model:槽值的预测被限制在每个槽的固定集内,非分类槽被限制在训练数据中观察到的值内
- generation-based model:根据对话上下文顺序解码槽值(逐标记解码),并有可能恢复看不见的值。
generation-based在基于大规模预训练神经语言模型(LM)的生成DST在不依赖特定领域模块的情况下取得了很强的效果。
在两个方面推进了generation-based model- 首先,将候选模式标签与对话上下文联合编码,为初始化解码器提供了一个任务感知的上下文化。
- 其次,将与数据库文档相关联的模式类别的自然语言描述作为语言模型的提示纳入编码中,允许统一处理分类插槽和非分类插槽。
使用基于提示的DST的独立解码建模的原因
- sequential(a),将对话历史作为编码器的输入,依次生成domain-slot-value triplets ( d m , s n , v ) (d_m,s_n,v) (dm,sn,v)。这种方法在许多利用自回归LM的系统中被采用,虽简单,但有可能遇到解码长序列的优化问题,从而导致性能较低
- independent(b)©,每个域-插槽对的值都是独立生成的,也可能是并行生成的。域和槽名(嵌入为连续表示)是解码器的初始隐藏状态,要么是解码器的第一个输入。或者为所有可能的域槽对生成值,或者对于当前不活动的域槽组合有一个单独的控制机制。
由于作者有兴趣用特定于任务的信息来丰富输入,因此我们专注于扩展基于提示的DST的独立解码建模。
-
另外发现了一个挺赞的公众号:https://mp.weixin.qq.com/s/vyKCCjAEbuOxpKOd6zhz3w















 1628
1628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









