







1.朴素贝叶斯法
朴素贝叶斯法是基于贝叶斯定理和特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布,然后基于此模型,对给定的输入 x,利用贝叶斯定理求出后验概率最大的输出 y 。
朴素贝叶斯法通过训练数据集学习联合概率分布 P(X, Y) , 具体来说,学习先验概率分布和条件概率分布。
 先验概率:根据已有的数据得到的概率
先验概率:根据已有的数据得到的概率
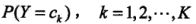
条件概率分布
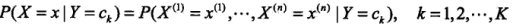
朴素贝叶斯法对条件概率做了条件独立性假设,即用于分类的特征在类确定的条件下都是独立的(实际上是不太可能的),这一假设使得可以计算条件概率,使得贝叶斯法变得简单,但是有时会牺牲一定的分类准确度,而朴素贝叶斯法也因此得名。
条件独立性假设:
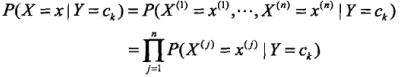
贝叶斯交换定理
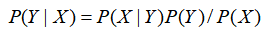
通过计算从数据集得到的先验概率和条件概率,可以得到输入为 x 时的后验概率
将条件独立性假设代入公式
由于分母对于所有类别都相同,所以最终的公式为
2.算法流程
 3.C++代码
3.C++代码
当前任务为文本分类
//naiveBayes.h
#ifndef NAIVEBAYES_H_
#define NAIVEBAYES_H_
#include<vector>
#include<string>
#include<set>
#include<opencv2/opencv.hpp>
using cv::Mat;
using std::vector;
using std::string;
using std::set;
//创建所有文档中出现的不重复词的集合
void createVocabList(const vector<vector<string>>& postingList, set<string>& vocabSet);
//将词向量转变成文本特征矩阵
Mat vec2Mat(const set<string>& vocabSet, vector<string>&vec);
//词集模型,判断文档中的单词那些在输入向量中出现,出现为1,否则为0
void setOfWords2Vec(const set<string>& vocabSet, const vector<string>&inputSet, vector<int>&output);
//词袋模型,判断文档中的单词那些在输入向量中出现,出现则+1,未出现为0
void bagOfWords2Vec(const set<string>& vocabSet, const vector<string>&inputSet, vector<int>&output);
//朴素贝叶斯分类器训练函数
void trainNB0(const Mat& trainMatrix, const vector<int>& classVec, vector<float>& pb, vector<Mat>& pVect);
//测试函数
int classifyNB(const  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2471
2471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











