







 DymSLAM是一个能够重建4D动态场景的系统,它利用双目视频输入,输出包括静态环境的稠密地图、运动物体的3D模型及轨迹。通过多模型拟合分割兴趣点,区分相机自运动和刚体运动,从而实现对动态物体的跟踪和重建。系统包括图像预处理、特征匹配、多运动分割与估计、稠密重建等步骤,不依赖语义线索,适用于未知刚性物体的动态SLAM问题。
DymSLAM是一个能够重建4D动态场景的系统,它利用双目视频输入,输出包括静态环境的稠密地图、运动物体的3D模型及轨迹。通过多模型拟合分割兴趣点,区分相机自运动和刚体运动,从而实现对动态物体的跟踪和重建。系统包括图像预处理、特征匹配、多运动分割与估计、稠密重建等步骤,不依赖语义线索,适用于未知刚性物体的动态SLAM问题。
DymSLAM:4D Dynamic Scene Reconstruction Based on Geometrical Motion Segmentation 论文笔记
摘要
本文介绍了一个动态立体视觉SLAM系统DymSLAM,该系统能够重建具有刚性运动物体的4D(3D+时间)动态场景。
DymSLAM的唯一输入是双目视频,其输出包括静态环境的稠密地图、运动物体的三维模型以及相机和运动物体的轨迹。
- 首先使用传统的SLAM方法检测和匹配连续帧之间的兴趣点。
- 然后采用多模型拟合的方法对不同运动模型(包括自运动模型和刚体运动模型)的兴趣点进行分割。
- 基于属于自运动模型的兴趣点,我们能够估计摄像机的轨迹,重建静态背景。
- 然后利用运动物体运动模型的兴趣点估计它们对相机的相对运动模型,重建物体的三维模型。
- 然后,我们将相对运动转换为全局参考系中运动物体的轨迹。
- 最后,我们将移动对象的3D模型融合到环境的3D地图中,通过考虑它们的运动轨迹来获得一个**4D (3D+时间)**序列。
以前的工作将移动对象视为异常值,并忽略它们,而DymSLAM则不同,它获取关于动态对象的信息。同时,DymSLAM不依赖语义线索或先验知识,适用于未知刚性对象。

系统介绍
在摄像机和物体都在大范围运动的动态场景中,我们利用4D动态场景重建来解决这个动态SLAM问题。
可以得到以下信息:详细的三维点云和运动刚体的运动轨迹,相机的自运动,以及静态背景的稠密点云地图。
首先,对传入的RGB双目序列进行校正和不失真处理。(图像预处理)然后,在每个立体图像对的左帧和右帧以及双目图像帧的时间连续对之间检测和匹配显著的图像特征。然后结合SLAM系统中基于多模型拟合[28]的多运动分割方法,将这些双目和时间匹配的特征点聚类成多个运动模型参数实例。这些运动模型对应于相机和每个运动物体的运动。一旦多运动分割的结果在几帧后稳定下来,通过在超像素级应用分配问题,将场景中的每个像素与单个运动模型关联起来。为了补偿在边界处的不精确分割,我们利用了从运动物体的三维模型投影的蒙版。我们估计当前帧中每个运动模型的6DOF刚体姿态,并在局部BA后输出不同运动下的摄像机和物体的轨迹。通过结合新估计的刚体姿态,每个运动模型的密集三维点云被重建,并随着时间的推移通过融合标记为属于该模型的点得到改进。最后,我们将每个物体点云及其轨迹转换为全局参考系,得到动态场景的4D (3D +时间)点云。
多运动视觉里程计
处理了匹配特征点[28]的多运动分割,以及每个运动模型[29]的VO估计。我们利用RANSAC[3],[30]对传统的运动模型参数估计进行扩展,同时估计立体摄像机和运动物体的轨迹。该方法采用多模型拟合方法对动态场景中存在的多个运动模型进行估计,并在存在多个运动物体的场景中实现对每个运动刚体目标的VO估计。
A. 多运动分割
使用经典的LIBVISO2方法来从双目图像中提取和匹配特征点,并使用优先排列的量化残差[28]来表示用于链接聚类的数据点[32]、[33],以分割属于不同运动的跟踪特征点。
假设模型计算的残差矩阵为R
其中矩阵R的每一列表示N个数据点
的假设模型的残差值
每行表示M个假设模型参数
下每个点的残差值
接下来,我们分别量化残差矩阵R的每一列:

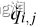
表示残差矩阵R量化后矩阵Q第i、j列的元素,θ是量化水平,通常θ∈[100,800],本文取100](https://i-blog.csdnimg.cn/blog_migrate/dd691a78e0a24068a6c596b1dc069fc5.png)
我们使用截断级别(3)来描述偏好,因为量化值越高,对数据点的影响越小。

其中λ是量化长度,∀λ∈[1,50],通常取1。对于数据点x,其量化残差偏好表示为所获得的截断量化残差矩阵Q的第i行,也就是
以上是用量化残差表示数据点的方法。当需要表示假设模型时,首先转置残差矩阵。并且可以对转置后的矩阵执行相同的运算,以获得假设模型的量化残差的偏好表示。与最初只从场景中采样假设的其他方法不同,我们在采样集群内的假设和使用排列偏好聚类点之间迭代交替[28]。在对属于不同运动模型的内点进行分类后,使用RANSAC对每个运动模型参数进行稳健估计。属于每个运动模型参数的内点稍后可以通过识别场景的静态部分来用于相机和运动对象的运动估计。
B. 多运动估计
在这一部分中,我们将描述如何将属于不同运动模型的内点转换为独立的刚体运动,以及摄像机和每个移动刚体对象的轨迹[29]。在连续的图像序列中,我们首先将多运动分割得到的准确而稳定的运动标签分配给每个运动对象。这是通过使用基于滑动窗口[29]的关节标签关联方法来完成的。对于滑动窗口内的当前帧和相邻的n个关键帧(在我们的实验中,n取4),我们将标签l(I)从特征点传递到匹配点。在当前帧中,我们采用具有最大系数的标签:

其中w(I)表示对应于不同关键帧的权重,该权重随着时间间隔的增加而减小。
然后,通过使用传统的VO批量估计技术,仅使用刚体假设来估计每个标签的运动轨迹。通过最小化当前帧中属于该特定模型的对应特征点与与前一帧中的姿势对齐的3D特征点簇之间的几何迭代最近点(ICP)误差的能量函数,来跟踪具有单一运动模型的每个运动对象的六自由度刚体姿态。我们以摄像机在第一帧中的位置作为全局参考帧,在识别出表示摄像机TC运动的模型后,估计摄像机和运动对象在全局参考帧中的运动轨迹。对于每个运动对象,根据估计的姿态将3D视觉特征投影到第一帧中,以计算运动对象的表面点集的重心。结果被认为是将每个移动对象与摄影机关联的初始变换Tinit。通过考虑随着时间的移动而产生的新的点来调整和更新重心。具有单个运动模型的每个运动对象在全局参考系中的运动TMtM1可以通过以下方式获得


运动目标掩码(Mask)
A.标签分配
估计每个运动物体在全局参考系中时刻t的绝对姿态,它由VO处理之后的刚体变换TMtM1表示。摄像机在时间t相对于全局参考系的运动由刚性变换TCtc1来描述。
在本部分中,通过将后续帧的每个点与一个刚体模型的运动相关联,将其指定给单个标签。为了完成高效的逐个像素的运动分割,我们在标记分配过程中应用了基于超像素分割的标记算法(简单线性迭代聚类(SLIC)[34])。我们使用少量的超像素而不是大量的像素来解决SLIC的标注问题。具有每个标签的运动模型与每个超像素的中心相关联,以便将标签分配给该超像素内的所有像素。
SLiC[34]考虑了像素的位置和颜色,而没有结合由于三维空间中的高分辨率而必不可少的深度信息。在本文中,我们考虑每个超像素的位置、颜色和深度,并对其内部像素的位置、颜色和深度进行平均。
超像素的聚类的距离度量由下式给出:


B.mask 掩码投影
我们完成了像素级的运动分割,得到每一帧运动对象的运动分割掩码。为了补偿边界分割的不准确,我们利用了从3D模型到2D图像转换得到的投影掩码。对于每个运动目标,我们使用其运动估计将其更新的最新3D模型投影到当前帧的2D图像中。

因此,随着每个物体3D模型重建的完整性的提高,最终的分割效果在理论上会变得越来越好。运动分割掩码和融合投影掩码后的最终分割模板如图2所示。对两种分割结果的边界的比较也如图2所示。可以看出,融合投影掩码可以很好地改善边界分割不准确的效果。

图2.(A)是运动分割掩码,(B)是融合投影掩码后的最终分割掩码。(A)和(B)中的透明矩形表示感兴趣的部分,它们在©、(D)和(E)中放大。©、(D)和(E)显示了两个分割结果的边界的比较。上图显示运动分割掩码,下图显示最终的分割掩码。©和(E)中的结果改善了分割不足的效果,而(D)中的结果改善了过度分割的效果
稠密重建
A.静态背景稠密建图
在静态背景映射中,我们只使用与摄像机运动相关的像素,并将运动对象的所有像素视为离群点。这种立体密集映射策略是基于rtabmap[36]方法实现的。基于摄像机的运动轨迹和运动目标模板的分割,利用属于静态背景的点建立密集的三维点云图。
B.运动目标稠密重建
基于多运动分割和运动对象掩码的结果,我们重建了每个运动对象的3D模型,该模型与单个刚性变换标签相关联。

在运动过程中,通过拼接新的点云来更新物体的3D模型,并通过刚性变换TMtM1将其变换到全局参考系中。3D模型的更新不仅可以不断地提高运动目标模板的分割效果,而且可以将其重心变换的结果应用于运动目标的运动估计。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









