







强化学习第六章:随机近似与随机梯度下降
随机近似算法(Stochastic Approximation, SA)
SA算法是一类寻根(方程求解)或优化问题的 随机迭代 算法。随机采样,迭代近似。还有,SA相较于其他方法(比如梯度下降)的强大之处在于 不需要知道 目标函数或者其导数或梯度的 表达式 。
RM算法(Robbins-Monro, RM)
RM算法是SA算法中非常经典的一个算法。
RM算法干什么的
假使,现在求解的问题:
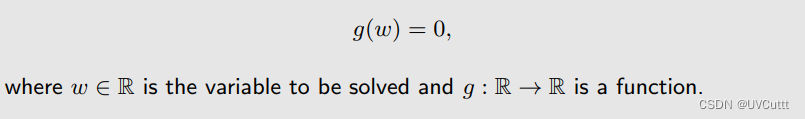
其他类似的问题(优化问题等)也可以转化为方程求根问题:

MakaBaka表示很熟悉,不就是求方程的根 w 嘛,但是挠了挠头发现连方程都不知道是啥,咋求根呢?MakaBaka手指一掐,白眼一翻,喃喃道:“RM算法助我!!!”。
RM算法怎么干的
下面这么干的:

MakaBaka拿着 wk 发现拿到的 g(w) 不够好,该如何优化呢,RM告诉MakaBaka说执行一个仪式:“把 wk 往下面的黑盒里面塞,得到 g(w) 之后加噪音拿到 g˜(wk, ηk) ,用 wk 减去 g˜(wk, ηk) 的一部分,这部分是多少呢,由 ak 决定”。
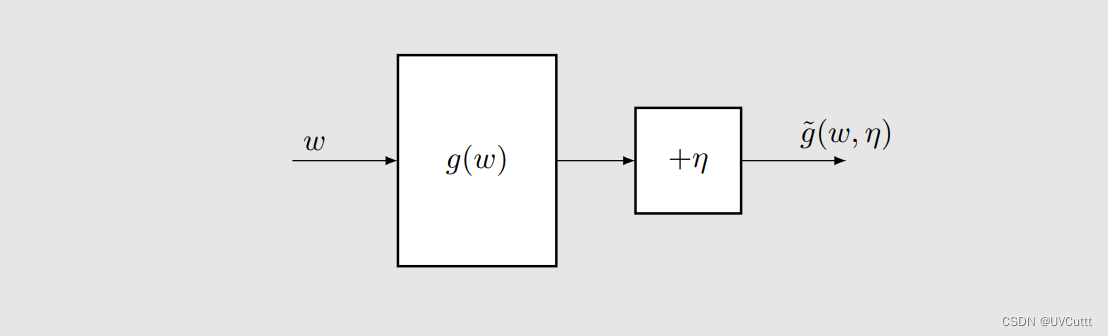
这样得到的 wk+1 就比 wk 更好吗?举个直观的例子验证一下,现在有这么一个问题:
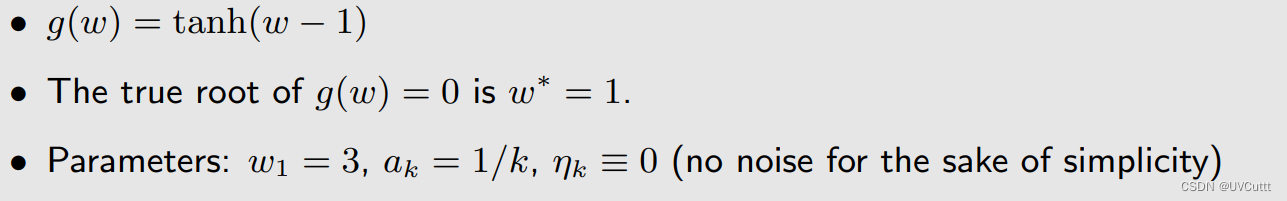
根据RM的仪式得到的中间过程:
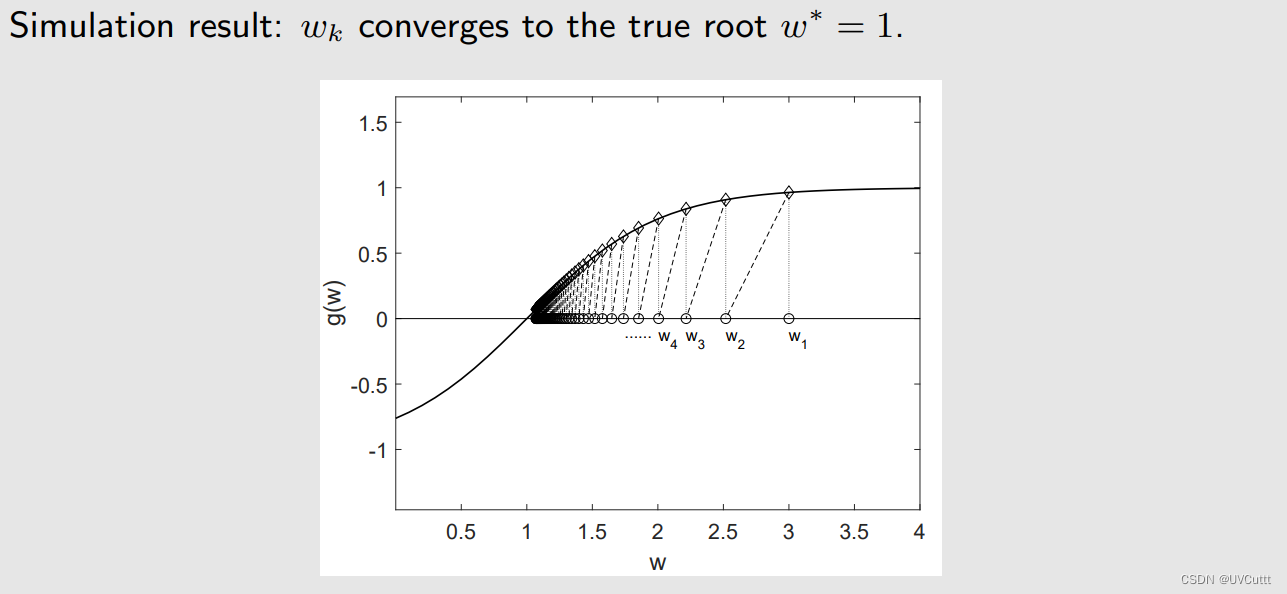
分析一下:
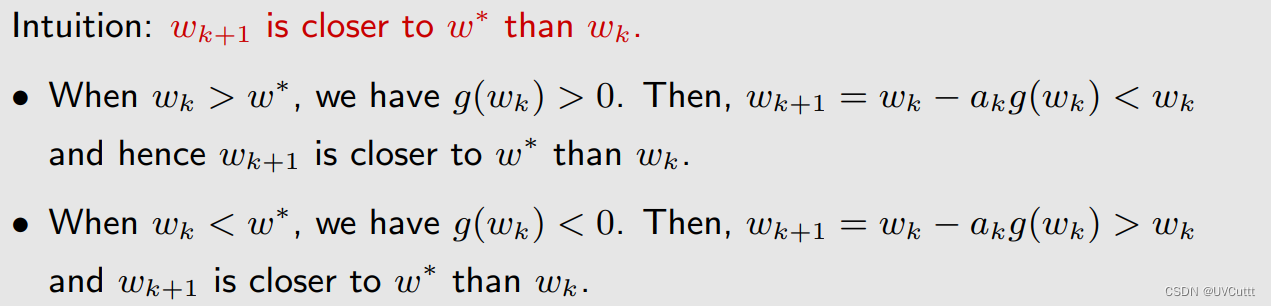
MakaBaka笑着说:“每次 wk 减去 ak*g˜(wk, ηk) 之后都能朝着根前进,随着 k 增大, g(w) 逐渐收敛到0, g˜(wk, ηk) 中噪音的噪音越来越大, ak 逐渐收敛到0,太神奇了”。
RM算法为什么能这么干
细心和眼尖的人已经发现了,上面举的例子是不是个巧合呢,其他的行不行,比如单调递减的呢?好问题,这里给出什么时候能向上面那样做,RM原话:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









