






哈希表
引入
定义
- 哈希表是根据关键码的值而直接进行访问的数据结构(比如数组)
解决问题
- 一般是用来快速判断一个元素是否出现在集合里(亦或判断一个元素之前是否出现过)
- 牺牲空间换时间( 因为我们要使用额外的数组/set/map来存放数据才能实现快速的查找,查找时间效率是O(1) )
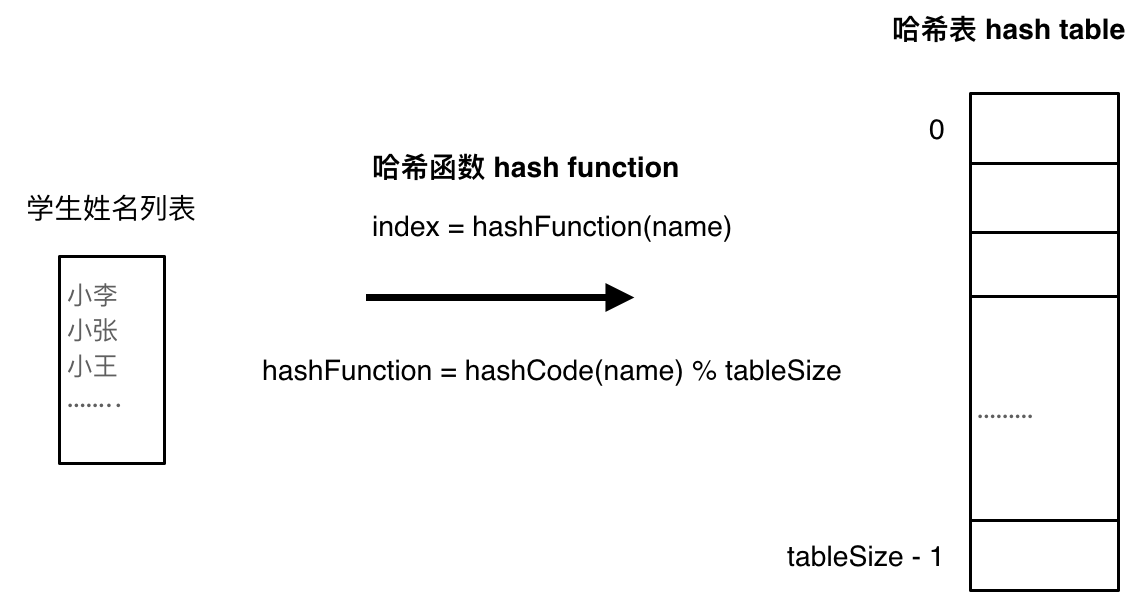
哈希函数
- 功能:将目标映射到哈希表上的索引(key)
- 实现: 哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。
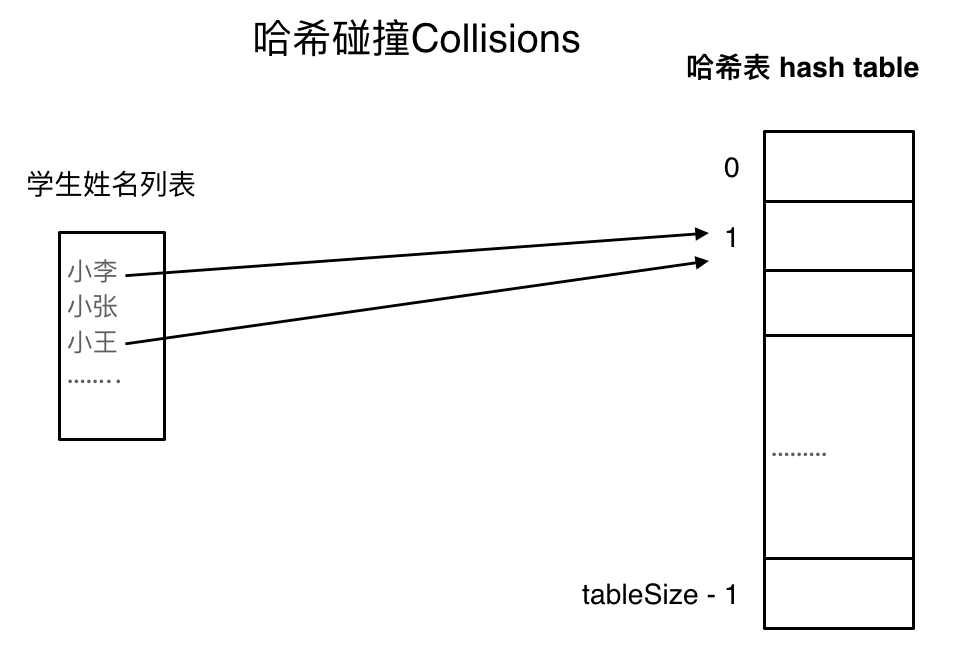
哈希碰撞
- 目标:解决dataSize(hashCode)大于tableSize的问题,此时会出现多个学生映射到同一索引上的情况。
-
方法
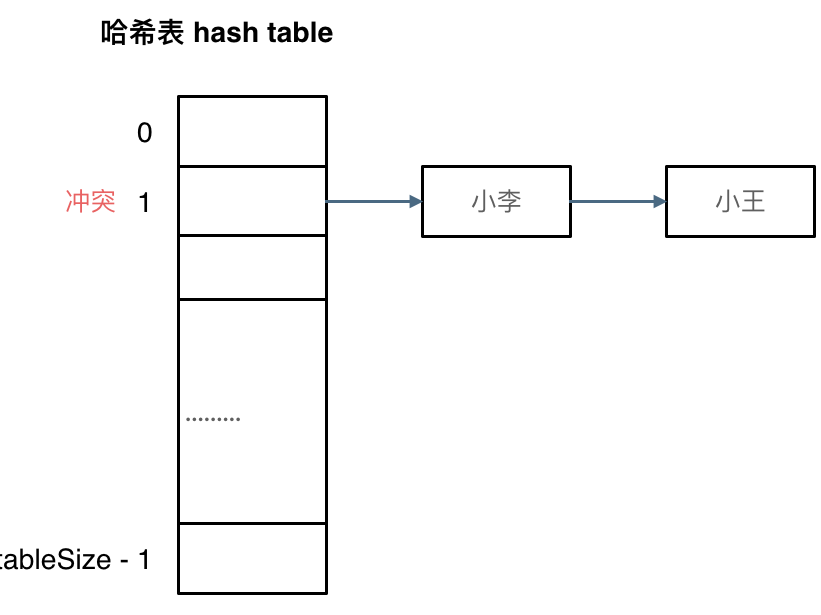
- 拉链法:发生冲突的元素被储存在链表中。
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
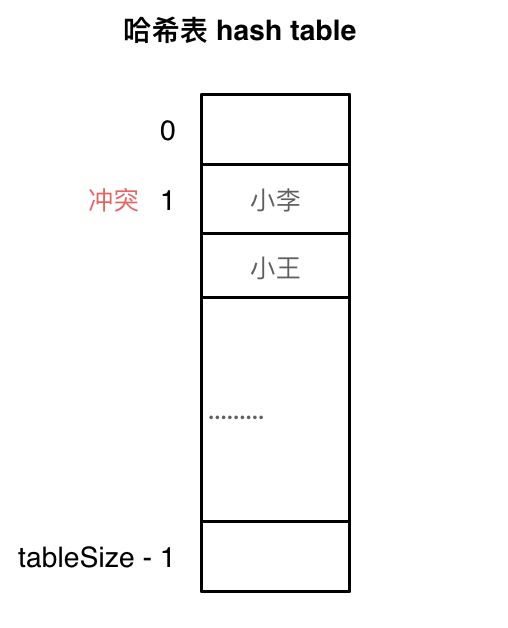
- 线性探测法: tableSize一定要大于dataSize,依靠哈希表中的空位解决冲突问题。
例如冲突的位置,放了小李,那么就向下找一个空位放置小王的信息 。
哈希结构
- 数组
- 下标代替索引映射:[i]-value
- 数据范围较小时使用:O(tableSize) < O(dataSize^2)
- 集合(set)
- 映射(map)
- 需要用到key-value结构
- 可以用结构体和动态数组实现
有效的字母异位词
-
前提
- 字符串只包含小写字母
-
要点
- 定义一个大小为26(字母)的哈希表(数组)record,所有value初始化为0 。
- s字符串的字母出现一次对应索引的value+1,t字符串的字母出现一次对应索引的value-1,若record最终为0,返回True,否则返回False。

哈希数组
时间复杂度O(n),因为空间大小是常量,所以空间复杂度为O(1)
bool isAnagram(char* s, char* t) {
int record[26] = {0};
int sSize = strlen(s);
int tSize = strlen(t);
if (sSize != tSize){
return false;
}
for (int i = 0; i < sSize; i++){
// 并不需要记住字符a的ASCII,只要求出一个相对数值就可以了
record[(s[i]-'a')] ++;
record[(t[i]-'a')] --;
}
for (int i = 0; i < 26; i++){
if (record[i] != 0){
return false;
}
}
return true;
}
两个数组的交集
- 前提
- 输出结果中的每个元素是唯一的(去重)
- 可以不考虑输出结果的顺序
- 限制了数值的大小,可以使用数组
- 要点
- 用哈希表记录数组1的元素,遍历数组2 时查找哈希表判断此元素是否已存在。
- 若在哈希表中查找到该元素,结束后将对应的哈希表值置零以去重。
哈希数组
时间复杂度O(m+n),空间复杂度为O(n)
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* intersection(int* nums1, int nums1Size, int* nums2, int nums2Size, int* returnSize) {
int nums1cntRecord[1000] = {0};
int lessSize = nums1Size < nums2Size ? nums1Size : nums2Size;
int *returnNums = calloc(lessSize, sizeof(int));
int returnIndex = 0;
int i;
for (i = 0; i < nums1Size; i++){
nums1cntRecord[nums1[i]]++;
}
for (i = 0; i < nums2Size; i++){
if (nums1cntRecord[nums2[i]] > 0){
returnNums[returnIndex] = nums2[i];
returnIndex++;
nums1cntRecord[nums2[i]] = 0;
}
}
*returnSize = returnIndex;
return returnNums;
}
哈希set
自定义set数据结构,太麻烦不用
快乐树
- 前提
- 正整数
- 要点
- 题目说会无限循环代表求和的过程中sum会重复出现。
- 退出条件:sum重复出现,若此时sum=1则返回True,否则返回False。
- 方法一:数学不等式缩小sum范围,使用数组哈希查找是否重复出现
- 方法二:快慢指针循环相遇
/*
标准库数据类型
typedef struct _div_t{
int quot;
int rem;
}div_t;
函数div(int numer, int denom),分子number除以分母denom,返回商quot、余数rem。
typedef unsigned char uint8_t;
- 8位无符号整数类型
- _t 表示这些数据类型是通过typedef定义的,而不是新的数据类型
*/
int getsum(int n){
div_t div_n = {.quot = n};
int sum = 0;
while (div_n.quot){
div_n = div(div_n.quot, 10);
sum += div_n.rem * div_n.rem;
}
return sum;
}
哈希数组
bool isHappy(int n) {
//1 <= n <= 2^31 - 1 (2^31 = 2147483648)
// sum = a1^2 + a2^2 + ... ak^2
// first round:
// 1 <= k <= 10
// 1 <= sum <= 1 + 81 * 9 = 730 (25+25 < 81+1)
// second round:
// 1 <= k <= 3
// 1 <= sum <= 36 + 81 * 2 = 198
// third round:
// 1 <= sum <= 81 * 2 = 162
// fourth round:
// 1 <= sum <= 81 * 2 = 162
uint8_t sumRecord[163] = {0};
int sum = getsum(getsum(getsum(n)));
while (sumRecord[sum] == 0){
sumRecord[sum] = 1;
sum = getsum(sum);
}
return sum==1;
}
快慢指针
bool isHappy(int n) {
int fast = n;
int slow = n;
do{
fast = getsum(getsum(fast));
slow = getsum(slow);
}while (fast != slow);
return fast==1;
}
两数之和
- 前提
- 数组中同一个元素在答案里不能重复出现
- 可以假设只存在一个有效答案
- 可以按任意顺序返回答案
- 要点
- 查找target-num[i]是否在哈希表中
- 因为范围不定,且需要查找数值和返回数组下标,选择map
- key存数值,value存下标
哈希map
/* leetcode 支持 ut_hash 函式庫 */
typedef struct {
int key;
int value;
UT_hash_handle hh;
}map;
map *hashMap = NULL;
map* hashMapFind(int key){
map* tmp = NULL;
HASH_FIND_INT(hashMap, &key, tmp);
return tmp;
}
void hashMapAdd(int key, int value){
if (hashMapFind(key) == NULL){
map* tmp = malloc(sizeof(map));
tmp -> key = key;
HASH_ADD_INT(hashMap, key, tmp);
tmp -> value = value;
}
}
void hashMapPrint(){
map* cur = NULL;
for (cur = hashMap; cur != NULL; cur = cur -> hh.next){
printf("key:%d, value:%d\n", cur -> key, cur -> value);
}
}
void hashMapCleanUp(){
map *cur, *tmp;
HASH_ITER(hh, hashMap, cur, tmp){
HASH_DEL(hashMap, cur);
free(cur);
}
}
int* twoSum(int* nums, int numsSize, int target, int* returnSize) {
map *hashMapRes = NULL;
int *indexRes = malloc(sizeof(int)*2);
hashMap = NULL;
for (int i = 0; i < numsSize; i++){
hashMapAdd(nums[i], i);
}
hashMapPrint();
for (int i = 0; i < numsSize; i++){
hashMapRes = hashMapFind(target - nums[i]);
if (hashMapRes != NULL && hashMapRes -> value != i){
indexRes[0] = i;
indexRes[1] = hashMapRes -> value;
*returnSize = 2;
return indexRes;
}
}
hashMapCleanUp();
return NULL;
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









