







2.1 热⾝:神经网络中使⽤矩阵快速计算输出的方法
w
j
k
l
w^l_{jk}
wjkl:第 l-1 层第 k 个神经元到第 l 层第 j 个神经元的权重。

a
j
l
a^l_j
ajl:第 l 层第 j 个神经元的激活值。
a j l = σ ( ∑ k w j k l a k l − 1 + b j l ) a^l_j=σ\left(\sum\limits_{k}w^l_{jk}a^{l-1}_k+b^l_j\right) ajl=σ(k∑wjklakl−1+bjl) :激活值与权重,偏置的关联
a l = σ ( w l a l − 1 + b l ) a^l = σ(w^la^{l−1} + b^l) al=σ(wlal−1+bl) :向量化的激活值
z l ≡ w l a l − 1 + b l z^l ≡ w^la^{l−1} + b^l zl≡wlal−1+bl : l 层神经元的带权输⼊
z j l = ∑ k w j k l a k l − 1 + b j l z^l_j=\sum_{k}w^l_{jk}a^{l-1}_k+b^l_j zjl=∑kwjklakl−1+bjl :第 l 层第 j 个神经元的激活函数的带权输入
2.2关于代价函数的两个假设
二次代价函数:
C = 1 2 n ∑ x ∣ ∣ y ( x ) − a L ( x ) ∣ ∣ 2 C=\frac{1}{2n}\sum\limits_{x}||y(x)-a^L(x)||^2 C=2n1x∑∣∣y(x)−aL(x)∣∣2
n 是训练样本的总数;
求和运算遍历了每个训练样本 x;
y = y(x) 是对应的⽬标输出;
L 表示网路的层数;
a
L
=
a
L
(
x
)
a^L = a^L(x)
aL=aL(x) 是当输⼊是 x 时的⽹络输出的激活值向量

为了应用反向传播,提出两个假设:
-
假设代价函数可以被写成一个在每个训练样本x上的代价函数 C x C_x Cx的均值: C = 1 n ∑ x C x C=\frac{1}{n}\sum_xC_x C=n1∑xCx
故每个独立的训练样本代价为: C x = 1 2 ∣ ∣ y − a L ∣ ∣ 2 C_x=\frac{1}{2}||y-a^L||^2 Cx=21∣∣y−aL∣∣2 -
假设代价可以写成神经网络输出的函数,如对一个独立的训练样本x其二次代价函数可写做:
C x = 1 2 ∣ ∣ y − a L ∣ ∣ 2 = 1 2 ∑ j ( y j − a j L ) 2 C_x=\frac{1}{2}||y-a^L||^2=\frac{1}{2}\sum\limits_j(y_j-a^L_j)^2 Cx=21∣∣y−aL∣∣2=21j∑(yj−ajL)2
C 看成仅有输出激活值 aL 的函数才是合理的,⽽ y 仅仅是帮助定义函数的参数⽽已。
2.3 Hadamard乘积
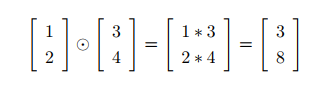
这种类型的按元素乘法有时候被称为 Hadamard 乘积,或者 Schur 乘积。














 2898
2898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









