






论文:PrototypeFormer: Learning to Explore Prototype Relationships for Few-shot Image Classification
tag:few-shot,prototype
一言以蔽之:作者提出了一种可学习的原型提取模型和一种基于子原型的对比损失函数。
Method:
- 作者表示全局平均池化一组特征这种方法不太好,p1,这么做可能会引入噪声(这个说法挺有意思的,一般不应该说会丢失信息吗?)。
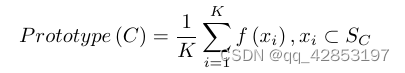
- 作者认为背景会对分类产生影响,也会提供与类别相关的上下文特征。所以提出了一种原型提取模型。其形状类似于vit,p2,是基于vit的结构所做。
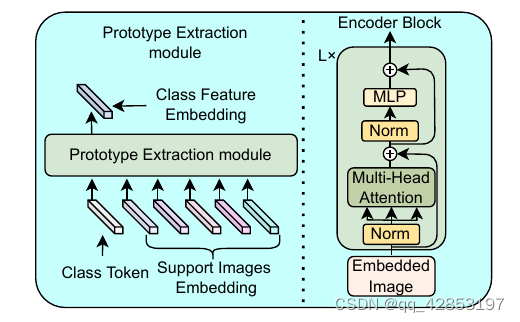
这个类似于vit的结构就叫prototype extraction,整个环节用表示,最终的结果就是一个类的特征条,输入的class token是support images embedding的GAP,其实就是上边p1的东西。这个K+1个输入,最终的输出记作Prototype(C)。
最后的预测结果也是基于距离度量的,比较常用。他的分类损失函数是交叉熵,并且给了这样一个公式。p3,实在是过于复杂了点,我姑且当它是我理解的那样的交叉熵吧。
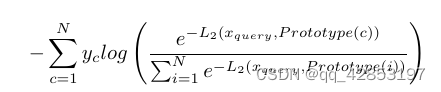
这部分介绍作者的第二部分工作,原型对比损失。一开始先介绍了一下对比学习和对比损失,我并不是很了解,所以仔细看了一下。一步一步介绍原型对比损失函数。对于某个类别c C 的K个样本,随意去掉其中一个,可以得到K种不同的结果,所以最终可以得到K个不同的有K-1个样本+一个classtoken的集合。把原本长度为K+1的扔进去得到一个Prototype(C)。把这K个集合扔进上文的prototype extraction中,得到K个class feature embedding,叫做sub-prototype。把它这么表示:
我们使用从同类支持集样本中得到的K个子原型叫做正对,不同类支持集得到的子原型叫做负对。最后就是比较复杂的,算一下损失函数。

将前后两种损失函数加合在一起,就是整体的loss。
整体如图
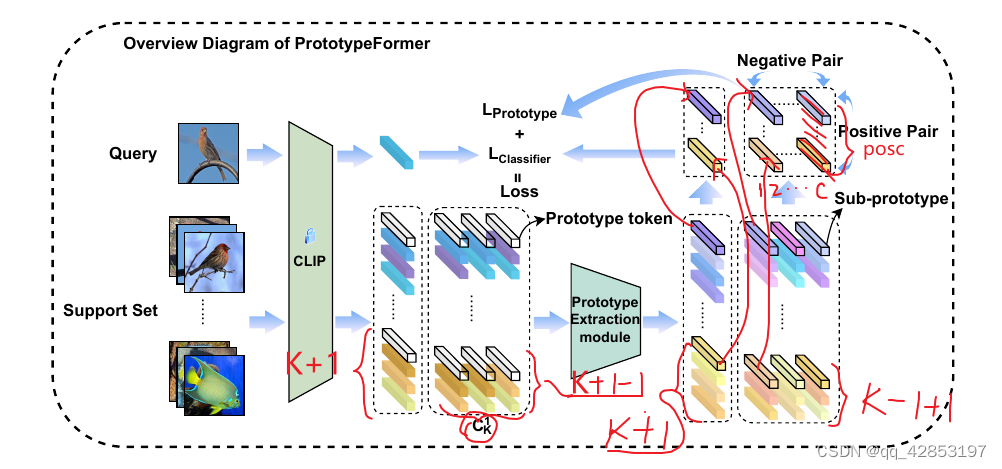
在训练的过程中,clip部分使用的是vit-L/14会被冻结,只训练prototype extraction module。
总结一下:作者做的这个工作很有创意啊,通过K种不同的采样构建正负集,在正负集的基础上计算loss。非常需要那么点数学功底,改进loss这种创意我短时间比较难做到。第一部分介绍的prototype extraction module比较容易理解。
难免有表达不当或理解错误的地方,希望大家一起交流。















 3009
3009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









