







介绍
文章标题:A Survey on Open Set Recognition
文章作者:Atefeh Mahdavi, Marco Carvalho
关键词:classification、open set recognition、multi-task learning、support vector machines、risk of the unknown
摘要
开放集识别(OSR)是关于处理模型在训练过程中没有学习到的未知情况。本文综述了OSR的研究现状,并分析了它们各自的优缺点,以期对新的研究者有所帮助。OSR模型的分类提供了沿着广泛的总结最近的进展。分析了OSR与多类分类、新奇检测等相关任务之间的关系。它的结论是,OSR可以适当地处理未知的情况下,在现实世界中捕捉所有可能的类的训练数据是不切实际的。最后,突出了OSR的应用,并为未来的研究课题提出了一些新的方向。
介绍
在OSR中,在训练模型时只有有限数量的已知类可用,并且在测试环境中出现在训练时从未见过的未知类的可能性。在这种情况下,算法中应考虑未知类及其风险。这样的系统不仅需要识别和区分属于源域的实例(即,包含在训练数据集中的已知类),但也拒绝目标域中的未知类(测试阶段中使用的类)。直到最近,几乎所有基于机器学习的系统的成功都是通过在“闭集”分类任务上进行的。在这样的系统中,源域和目标域被假设为包含相同的对象类,并且系统仅在训练期间已经看到的已知类上进行测试。
与“封闭集“设置不同,更现实的场景是解决由对象的“开放集“组成的现实问题。随着构建智能系统和利用基于机器学习的系统的出现,广泛的应用需要健壮的人工智能方法。处理“未知的未知数”可以被认为是一种方法,使系统能够在面对世界的限制和未建模方面时稳健地行动。忽略未知对象会导致系统的不正确开发并限制其可用性。
然而,在真实的动态世界中为识别/分类任务建立正确和完整的模型提出了多个挑战,因为预测和训练未知对象的所有可能示例是禁止的,并且当在测试床中评估时模型可能失败。
OSR系统有两大类。第一个任务是区分已知类实例和未知类实例。这种无法区分已知类别的机制充当的是检测器而不是分类器。在第二类中,类的数量超过两个,OSR关注的是区分已知的类。该系统识别未知数,并将输入标记为最适合的已知类别之一或未知。OSR的潜在解决方案所面临的挑战是估计所有已知类别的正确概率并保持它们的性能,同时沿着未知类别的精确预测并优化它们的模型。
本文的结构如下:首先,我们简要区分OSR与多分类分类和异常检测问题,并讨论它们的局限性。然后,我们提出两种OSR算法的广泛类别,并详细介绍每个类别下的重要研究。这里描述的类别涵盖基于统计学和基于深度神经网络的算法。表1代表现有方法对这些类别及其子类别的分类。在最后一节中,我们对本文的综述进行总体总结。
现有的开集识别的方法如下

统计学的方法有:
- 拒绝适应SVM
- 稀疏表示
- 基于距离
- 边际分布
深度神经网络的方法:
- 对抗学习
- 基于背景类的建模
- 其他
OSR与多类分类和异常检测
OSR被称为基于分类的任务。大多数OSR的方法都是基于常规分类器形成的,因为它们与分类任务非常接近;然而,对OSR有效的分类器的适应并不总是可能的。分类和异常检测是OSR最接近的亲戚。表2总结了OSR和这些相关区域之间的关系。
下表是OSR和其他识别的区别
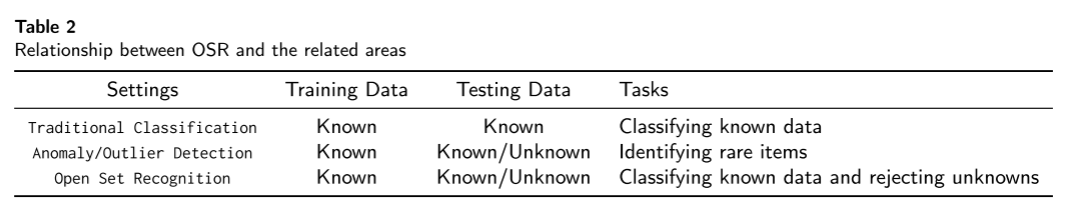
在传统的多分类分类器中,由于封闭集假设的存在,所有输入都被标记并归类为在训练期间观察到的已知类中的一个。更准确地说,在封闭集分类任务中,学习者只能访问一组已知的固定类。
图1就是OSR相比于传统方法的好处

(a)这里展示了一个传统的最近类均值(NCM)分类器的决策边界。想象我们有三个不同的已知类别,分别用菱形、圆形和正方形来表示。分类器根据这些已知类别的数据进行训练,然后确定一个边界来划分不同类别。
(b)是从封闭的三个类别模型向外放大看原始数据集在整个空间的分布情况。可以看到,由于分类器在训练时并不知道所有可能的类别,它就只能根据已有的训练数据(也就是那三个已知类别)来给所有的东西分类,不管是见过的还是没见过的。这样就会导致在开放空间中的未知输入很容易被错误分类,因为它没有办法准确判断这些未知的东西到底属于哪一类。
(c)就是OSR 的方法,就像是有了更多的信息,知道哪些区域可能是未知的,不会轻易把未知的东西分到已知的类别里。
统计学的方法




深度神经网络的方法
受人脑启发的人工神经网络模拟生物神经元的组织和学习。它由神经元或处理计算单元组成,这些单元相互连接,并组织在三种类型的层中,称为输入层,隐藏层和输出层。输入层接收数据并与隐藏层通信,在隐藏层中使用加权路径进行实际处理。然后,隐藏层连接到网络中的最后一层以给出输出。额外的隐藏层为网络提供了更大的灵活性,并使其更强大地建模输入和输出之间的复杂关系。这种具有许多隐藏层的神经网络被称为深度神经网络(DNN)(见图3)。
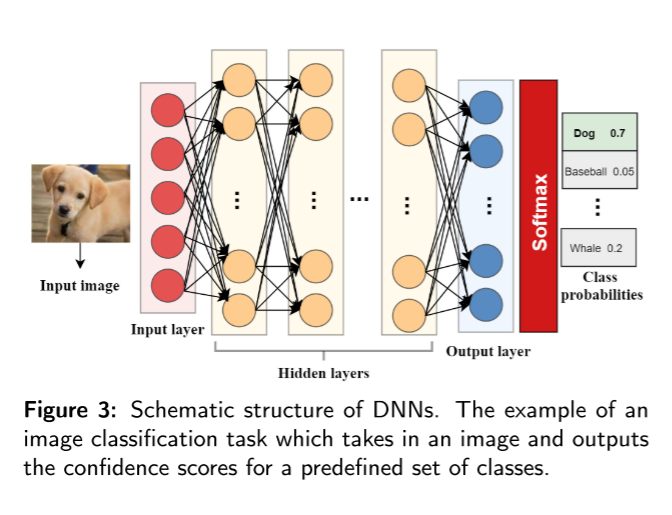
用圆圈表示的神经元通过几个加权连接发送信号来相互通信。权重基本上是前一层的神经元对当前层的神经元的影响。每个神经元都有一个激活状态,它是神经元的输出,并进入下一层。一层中神经元的激活值作为下一层激活函数的输入,其中权重连接定义了该贡献的量。这就是在前向传播过程中更新当前层的激活值的方式。在多类问题中,大多数DNN通常使用Softmax函数作为输出层中的激活函数。通过调整加权连接的值,在反向传播中训练网络。训练的目标是最小化损失函数,例如表示softmax函数的输出与期望输出之间的差异的交叉熵,以实现训练数据中的低分类错误。这个过程会产生一组适当调整的权重,使神经网络能够有效地用于最初设计的目的。最后,在测试期间,Softmax函数表示样本被标记为类的概率。由于其封闭的性质,深度网络将未知样本与Softmax给出的最大得分的类联系起来,导致该样本的错误分类。
然而,随着向深度网络的转变,深度网络结合了学习特征和学习分类器,OSR系统的性能仍然远未达到最佳[117]。研究已经通过对Softmax分数进行阈值处理来解决这个问题。似乎对于未知样本,该函数为所有类别产生低概率,因此对输出概率进行阈值处理可以帮助拒绝未知数。然而,将深度网络与阈值概率相结合会确定不确定的预测,这些预测是未知输入的一小部分。
因此,阈值Softmax不足以检测欺骗性或对抗性示例。[118,119]等研究表明,DNN特别容易受到这些示例的影响,并且很容易被欺骗。欺骗的例子针对所需的类,并试图增加该类的相应概率。这些人工构建的示例对人类来说是完全不可感知的,但分类器将它们视为所需类别的成员,并以高度的确定性标记它们(见图4(c))。一个更具限制性的情况是拒绝一个对抗性的例子[120]-一个视觉上类似的输入到训练数据集,带有很小但故意的扰动,这样它就被分类器错误地标记为一个完全不同的高置信度的类(见图4(d))。
此外,比阈值softmax更有效的拒绝解决方案是使用垃圾或背景类,这在大多数现代检测方法中占主导地位,如[27-29]。这种基于背景类的建模可以通过在训练过程中添加另一个类作为未知样本的代表来解决神经网络中的未知问题。虽然这种方法适用于PASCAL [128]和MS-COCO [129]等数据集,但它可能是负数据集偏差的来源[130],并且在真实的世界中具有无限负空间的限制,其中许多未知输入被拒绝。最近,Dhamija等人[26]将SoftMax与熵开集和目标球损失结合起来,考虑背景和未知的训练样本。这些损失增加了未知输入的SoftMax熵,同时最小化了未知样本深度表示的欧几里得长度。这种修改增加了深特征空间中的分离,并改进了背景和未知类的处理。
OpenMax使用从正训练样本构建的EVT模型来定义每类CAP模型,该模型可以通过对模型设定阈值来限制开放空间的风险,以拒绝未知输入。首先,计算每个训练实例X的激活向量,并将其定义为V(x)=v1(x),v2(x)…vN(x)对于每一类,y=1,2,3…N,利用NCM概念[103,132],仅在正确分类的训练示例上分别计算每个类别的平均激活向量(MAV)。然后,根据MAV类和正训练实例之间的最大距离,对每个类拟合Weibull分布,见图5
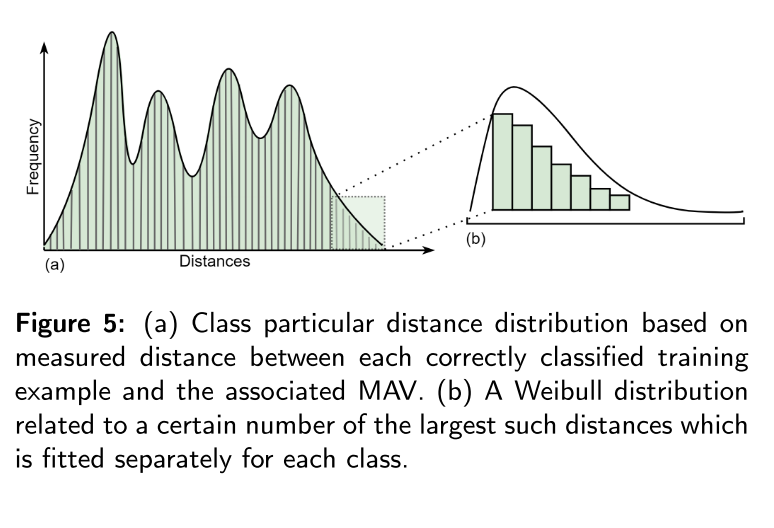
(a)是基于每个正确分类的训练样本和相关MAV之间的测量距离,对特定距离分布进行分类。(b)与一定数量的最大距离相关的Weibull分布,对每个类别分别进行拟合。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











