






 本文指导如何在Ubuntu系统中安装ibus输入法,包括使用apt-get安装ibus-libpinyin,配置中文智能拼音,并介绍如何导入搜狗细胞词库以增强词库功能,涉及Python脚本解析词库内容。
本文指导如何在Ubuntu系统中安装ibus输入法,包括使用apt-get安装ibus-libpinyin,配置中文智能拼音,并介绍如何导入搜狗细胞词库以增强词库功能,涉及Python脚本解析词库内容。
安装ibus输入法
apt-get install ibus-libpinyin
然后在ubuntu设置中输入源中找到,添加中文(智能拼音)

一般情况
到这里:
GitHub - broly8/libpinyin-dict: ibus-libpinyin可用32万txt词库
导入最上面的dict.txt就行
导入方式
如果首选项可以导入那就首选项导入
坑:
文件后缀名改称.txt然后等以下,我的经验看要等5分钟
然后重启下
ibus ibus-daemon -r -d -x 不然
cp 你的词典文件.txt /usr/share/ibus-libpinyin/db/local.db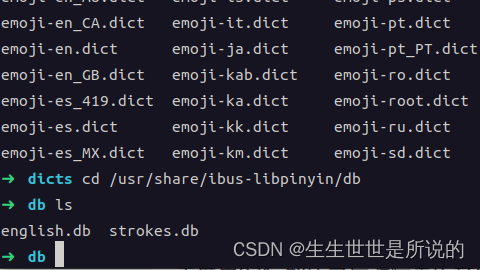
手动导入
到这里
搜索计算机找到
随便找一个比方说:
#!/usr/bin/python
# -*- coding: utf-8 -*-
import struct
import sys
import binascii
import pdb
# 搜狗的scel词库就是保存的文本的unicode编码,每两个字节一个字符(中文汉字或者英文字母)
# 找出其每部分的偏移位置即可
# 主要两部分
# 1.全局拼音表,貌似是所有的拼音组合,字典序
# 格式为(index,len,pinyin)的列表
# index: 两个字节的整数 代表这个拼音的索引
# len: 两个字节的整数 拼音的字节长度
# pinyin: 当前的拼音,每个字符两个字节,总长len
#
# 2.汉语词组表
# 格式为(same,py_table_len,py_table,{word_len,word,ext_len,ext})的一个列表
# same: 两个字节 整数 同音词数量
# py_table_len: 两个字节 整数
# py_table: 整数列表,每个整数两个字节,每个整数代表一个拼音的索引
#
# word_len:两个字节 整数 代表中文词组字节数长度
# word: 中文词组,每个中文汉字两个字节,总长度word_len
# ext_len: 两个字节 整数 代表扩展信息的长度,好像都是10
# ext: 扩展信息 前两个字节是一个整数(不知道是不是词频) 后八个字节全是0
#
# {word_len,word,ext_len,ext} 一共重复same次 同音词 相同拼音表
# 拼音表偏移,
startPy = 0x1540
# 汉语词组表偏移
startChinese = 0x2628
# 全局拼音表
GPy_Table = {}
# 解析结果
# 元组(词频,拼音,中文词组)的列表
GTable = []
def byte2str(data):
'''将原始字节码转为字符串'''
i = 0
length = len(data)
ret = u''
while i < length:
x = data[i:i+2]
t = chr(struct.unpack('H', x)[0])
if t == u'\r':
ret += u'\n'
elif t != u' ':
ret += t
i += 2
return ret
# 获取拼音表
def getPyTable(data):
if data[0:4] != b"\x9D\x01\x00\x00":
return None
data = data[4:]
pos = 0
length = len(data)
while pos < length:
index =struct.unpack('H',data[pos:pos+2])[0]
# print(index)
pos += 2
l = struct.unpack('H',data[pos:pos+2])[0]
# print(l)
pos += 2
py = byte2str(data[pos:pos + l])
#print(py)
GPy_Table[index] = py
pos += l
# 获取一个词组的拼音
def getWordPy(data):
pos = 0
length = len(data)
ret = []
while pos < length:
index =struct.unpack('H',data[pos:pos+2])[0]
ret.append(GPy_Table[index])
pos += 2
return '\''.join(ret)
# 获取一个词组
def getWord(data):
pos = 0
length = len(data)
ret = u''
while pos < length:
index = struct.unpack('H', data[pos] + data[pos + 1])[0]
ret += GPy_Table[index]
pos += 2
return ret
# 读取中文表
def getChinese(data):
#import pdb
# pdb.set_trace()
pos = 0
length = len(data)
while pos < length:
# 同音词数量
same = struct.unpack('H',data[pos:pos+2])[0]
# print '[same]:',same,
# 拼音索引表长度
pos += 2
py_table_len = struct.unpack('H',data[pos:pos+2])[0]
# 拼音索引表
pos += 2
py = getWordPy(data[pos: pos + py_table_len])
# 中文词组
pos += py_table_len
for i in range(same):
# 中文词组长度
c_len =struct.unpack('H',data[pos:pos+2])[0]
# 中文词组
pos += 2
word = byte2str(data[pos: pos + c_len])
# 扩展数据长度
pos += c_len
ext_len = struct.unpack('H', data[pos:pos + 2])[0]
# 词频
pos += 2
count = struct.unpack('H', data[pos:pos+2])[0]
# 保存
GTable.append((count, py, word))
# 到下个词的偏移位置
pos += ext_len
def deal(file_name):
print ('-' * 60)
f = open(file_name, 'rb')
data = f.read()
f.close()
if data[0:12] != b"\x40\x15\x00\x00\x44\x43\x53\x01\x01\x00\x00\x00":
print ("确认你选择的是搜狗(.scel)词库?")
sys.exit(0)
# pdb.set_trace()
print( "词库名:", byte2str(data[0x130:0x338])) # .encode('GB18030')
print("词库类型:", byte2str(data[0x338:0x540])) # .encode('GB18030')
print("描述信息:", byte2str(data[0x540:0xd40])) # .encode('GB18030')
print("词库示例:", byte2str(data[0xd40:startPy])) # .encode('GB18030')
getPyTable(data[startPy:startChinese])
getChinese(data[startChinese:])
if __name__ == '__main__':
# 将要转换的词库添加在这里就可以了
o = []
import os
for f in os.listdir("./"):
if f.find('.scel') != -1:
o.append(f)
print("找到词库文件:"+f)
for f in o:
deal(f)
# 保存结果
f = open('sougou.txt', 'w')
for count, py, word in GTable:
# GTable保存着结果,是一个列表,每个元素是一个元组(词频,拼音,中文词组),有需要的话可以保存成自己需要个格式
# 我没排序,所以结果是按照上面输入文件的顺序
# f.write(unicode('{%(count)s}' % {'count': count} + py + ' ' + word).encode('UTF-8')) # 最终保存文件的编码,可以自给改
#f.write(unicode('%s %s %s' % (word, py, count)).encode('UTF-8'))
f.write(f'{word} {py} {count}')
f.write('\n')
f.close()把py文件和scel放在一个文件夹中,然后运行!
python transfer.py输出sougou.txt,导入ibus就行了。

















 2540
2540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









