






安装服务
brew tap probezy/core && brew install cpolar
// 安装cpolar
sudo cpolar service install
// 启动服务
sudo cpolar service start
访问管理网站
http://127.0.0.1:9200/#/tunnels/list
菜单“隧道列表” 》 编辑 自定义暴露的端口
再到在线列表中查看公网域名
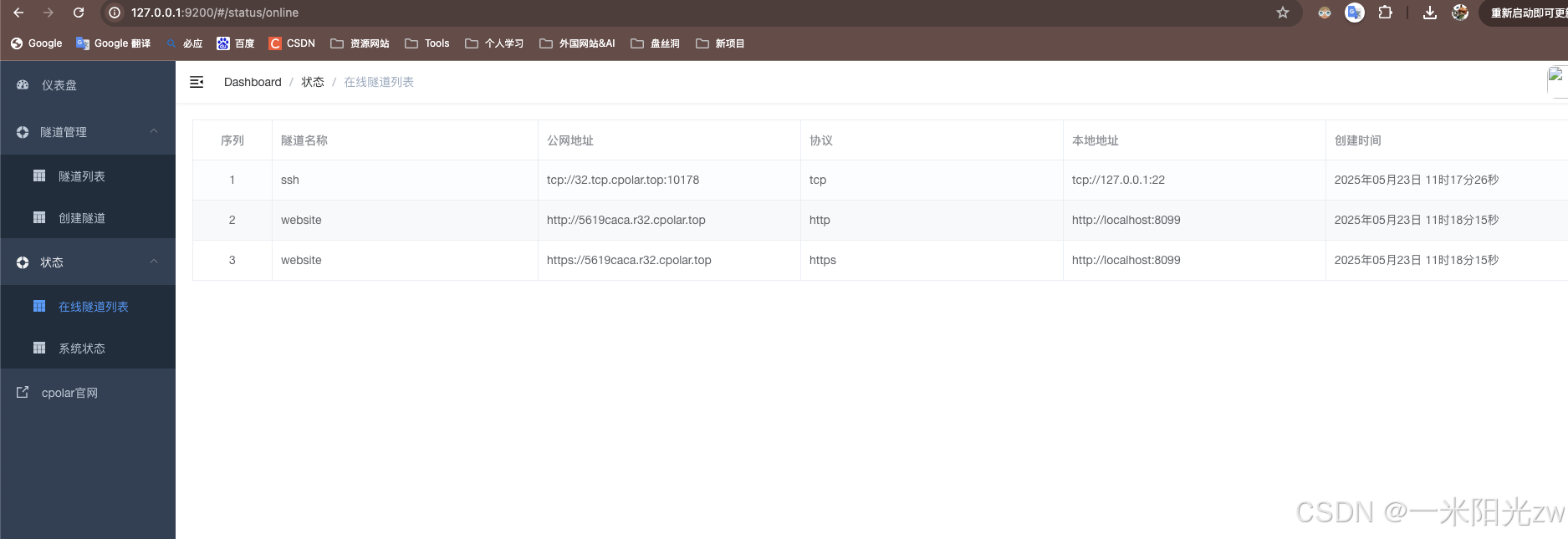
我这里8099端口启动了自己的项目
先用本地地址验证接口是否正常,没问题后用公网地址请求
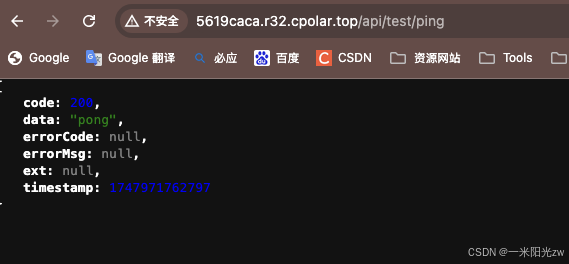
可以正常访问说明没问题



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











