






SDN介绍
在kubernetes中,当节点和Pod的数量上升后,手动管理节点上绑定的端口是十分困难的,这也是NodePort类型的Service的缺点之一。而一旦Pod不再“借用”节点的IP和端口来暴露自身的服务,就不得不面临一个棘手的问题:Pod的本质是节点中的进程,节点外的物理网络设备(交换机/路由器)并不知晓Pod的存在。它们在接收目的地址为Pod IP的数据包时,无法完成进一步的传输工作。
为此我们需要使用一些CNI(Container Network Interface)插件(如Flannel、Calico和Open vSwitch等)来优化Kubernetes集群的网络模型,这种新型的网络设计理念称为SDN(Software-defined Networking)。根据SDN实现的层级,我们可以将其分为Underlay Network和Overlay Network:
Overlay 网络允许设备跨越底层物理网络(Underlay Network)进行通信,而底层却并不知晓 Overlay 网络的存在。Underlay 网络是专门用来承载用户 IP 流量的基础架构层,它与 Overlay 网络之间的关系有点类似物理机和虚拟机。Underlay 网络和物理机都是真正存在的实体,它们分别对应着真实存在的网络设备和计算设备,而 Overlay 网络和虚拟机都是依托在下层实体使用软件虚拟出来的层级。
Underlay Network
利用Underlay Network实现Pod跨节点通信,既可以只依赖TCP/IP模型中的二层协议,也可以使用三层。但无论哪种实现方式,都必须对底层的物理网络有所要求。
二层
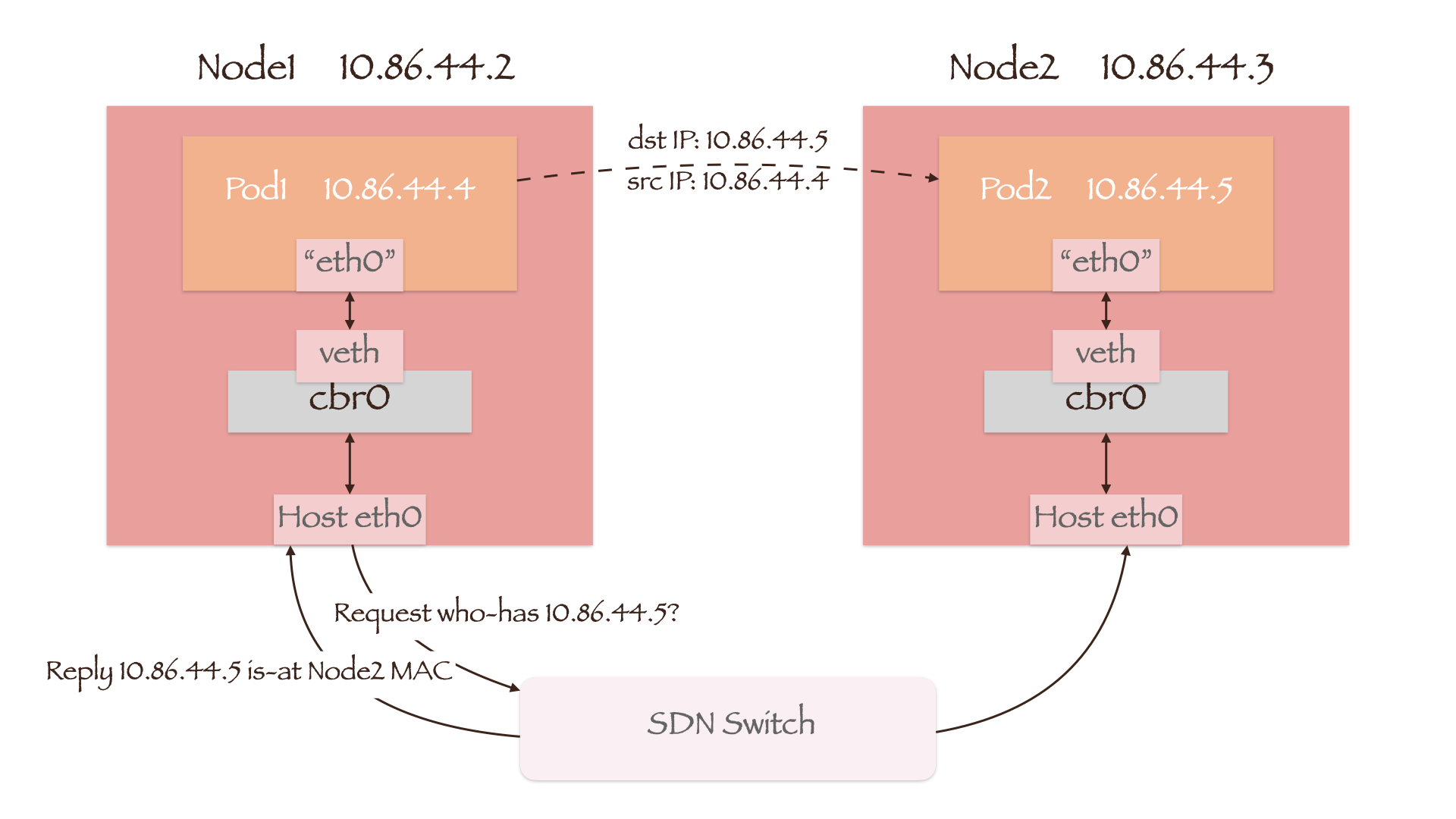
如图所示,Pod与节点的IP地址均处于同一网段。当Pod1向另一节点上的Pod2发起通信时,数据包首先通过veth-pair和cbr0送往Node1的网卡。由于目的地址10.86.44.4与Node1同网段,因此Node1将通过ARP广播请求10.86.44.4的MAC地址。
CNI插件不仅为Pod分配IP地址,它还会将每个Pod所在的节点信息下发给SDN交换机。这样当SDN交换机接收到ARP请求时,将会答复Pod2所在节点Node2的MAC地址,数据包也就顺利地送到了Node2上。
三层
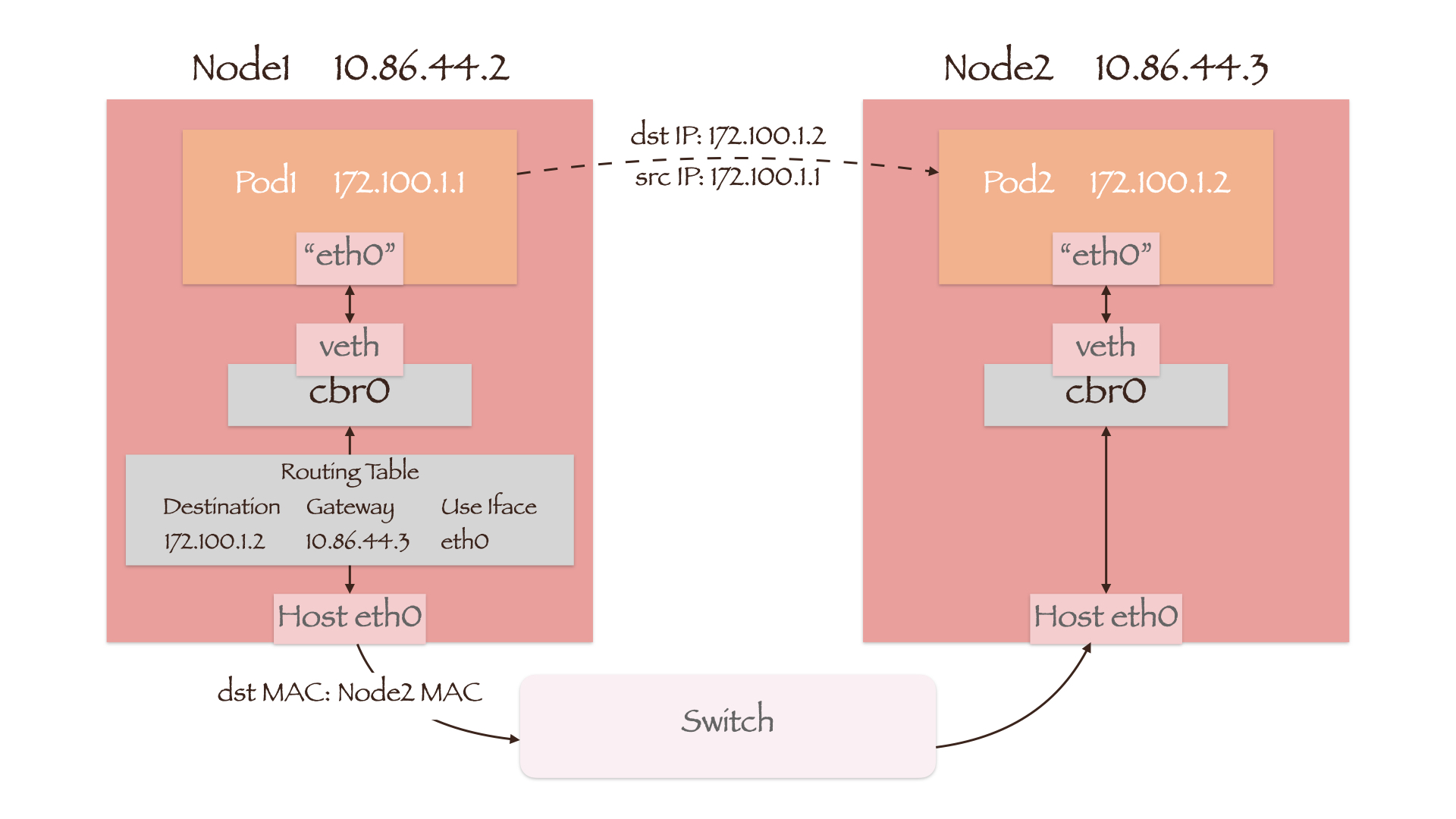
如图所示,Pod与节点的IP地址不再处于同一网段。当Pod1向另一节点上的Pod2发起通信时,数据包首先通过veth-pair和cbr0进入宿主机内核的路由表(Routing Table)。CNI插件在该表中添加了若干条路由规则,如目的地址为Pod2 IP的网关为Node2的IP。这样数据包的目的MAC地址就变为了Node2的MAC地址,它将会通过交换机发送到Node2上。
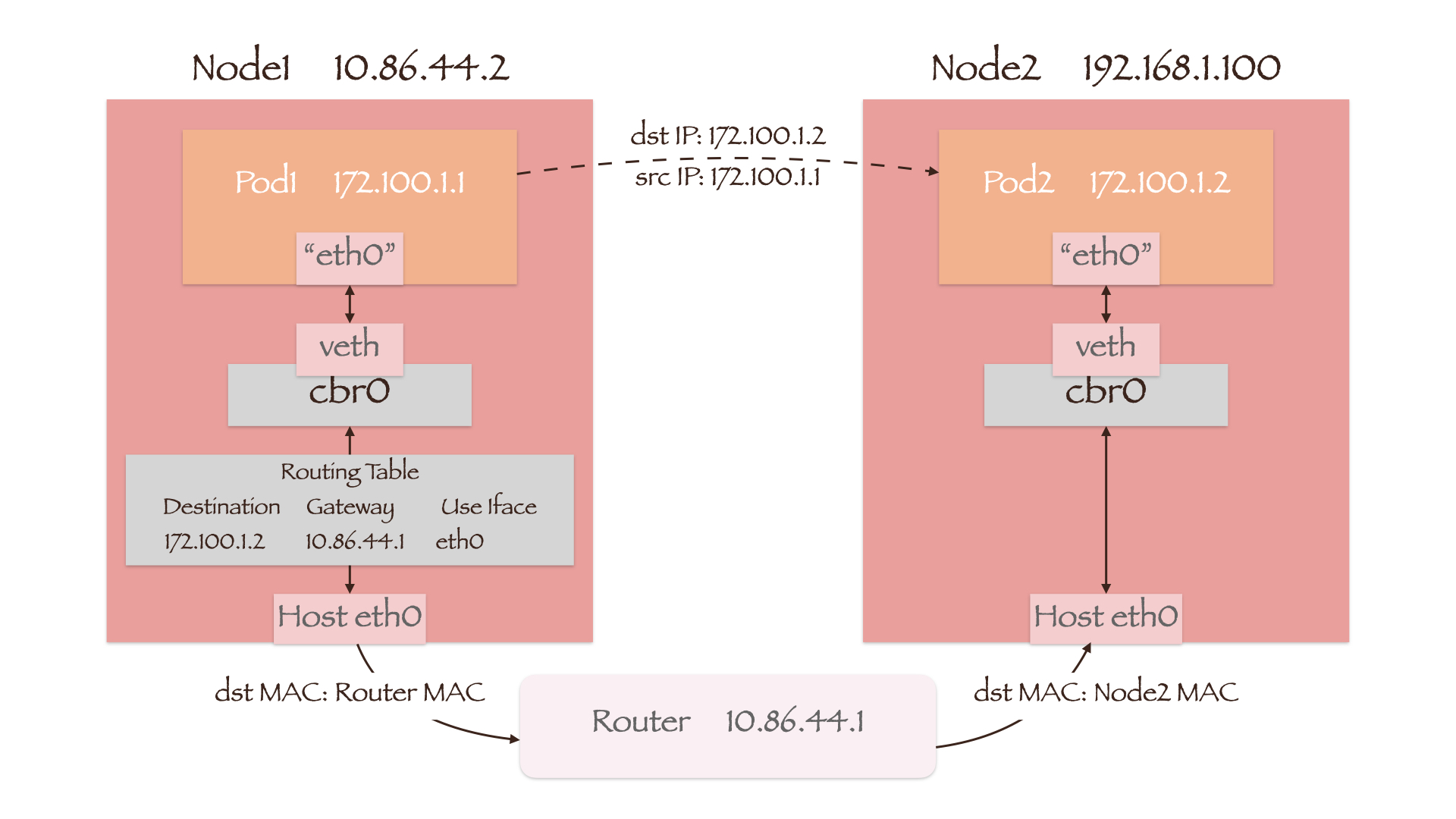
由于这种实现方式基于三层协议,因此不要求Node1和Node2处于同一网段。如下图所示,此时需要将目的地址为Pod2 IP的网关设置为路由器的IP。数据包的目的MAC地址首先变为路由器的MAC地址,然后经过路由器后再变为Node2的MAC地址。
通过上面的描述我们可以发现,想要实现三层的Underlay网络,需要在多个节点间下发和同步路由表。于是很容易想到用于交换路由信息的BGP(Border Gateway Protocol)协议:
边界网关协议(英语:Border Gateway Protocol,缩写:BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或“前缀”表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。
对于Calico的BGP模式来说,我们可以把集群网络模型视为在每个节点上都部署了一台虚拟路由器。路由器可以与其他节点上的路由器通过BGP协议互通,它们称为一对BGP Peers。Calico的默认部署方式为Full-mesh,即创建一个完整的内部BGP连接网,每个节点上的路由器均互为BGP Peers。这种方式仅适用于100个节点以内的中小型集群,在大型集群中使用的效率低下。而Route reflectors模式则将部分节点作为路由反射器,其他节点上的路由器只需与路由反射器互为BGP Peers。这样便可以大大减少集群中BGP Peers的数量,从而提升效率。
Overlay Network
Overlay网络可以通过多种协议实现,但通常是对IP数据包进行一层外部封装(Encapsulation)。这样底层的Underlay网络便只会看到外部封装的数据,而无需处理内部的原有数据。Overlay网络发送数据包的方式取决于其类型和使用的协议,如基于VxLAN实现Overlay网络,数据包将被外部封装后以UDP协议进行发送:
Overlay网络的实现并不依赖于底层物理网络设备,因此我们就以 两节点不处于同一网段且Pod与节点亦处于不同网段的例子来说明Overlay网络中的数据包传递过程。集群网络使用VxLAN技术组建,虚拟网络设备VTEP(Virtual Tunnel End Point)将会完成数据包的封装和解封操作。
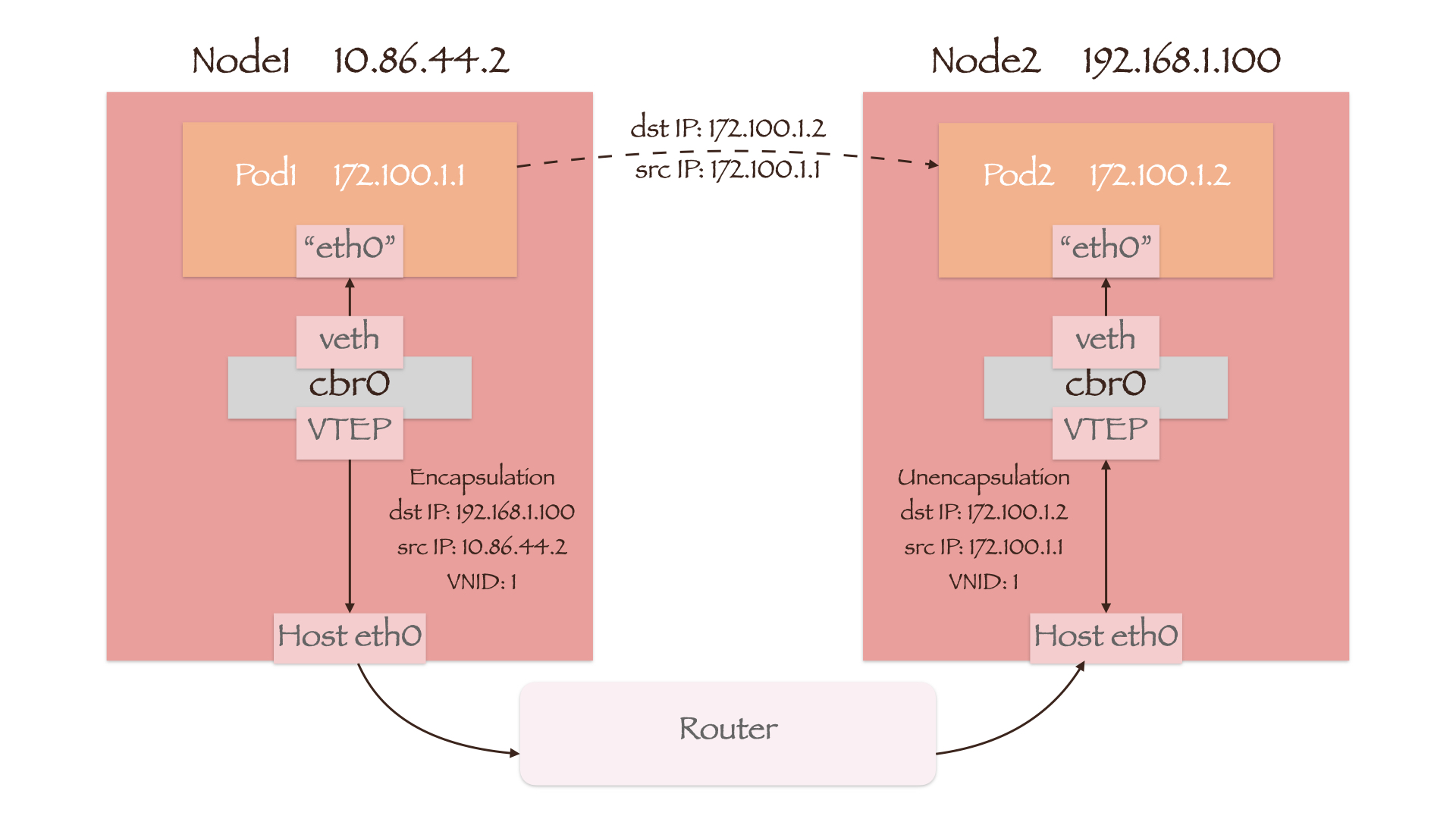
Node1上的VTEP收到Pod1发来的数据包后,首先会在本地的转发表中查找目的Pod所在节点的IP,即192.168.1.100。随后它将本机IP地址10.86.44.2、Node2的IP地址192.168.1.100和Pod1的VNID(VxLAN Network Identifier)封装在原始数据包外,从Node1的网络接口eth0送出。由于新构建的数据包源/目的地址均为节点的IP,因此外部的路由器可以将其转发到Node2上。Node2中的VTEP在接收到数据包后会首先进行解封,若源VNID(Pod1的VNID)与目的VNID(Pod2的VNID)一致,便会根据原始数据包中的目的地址172.100.1.2将其发送到Pod2上。此处的VNID检查,主要是为了实现集群的网络策略管理和多租户隔离。
kubernetes中使用SDN
在Kubernetes中,SDN技术用于解决“每个Pod有独立IP, Pod之间可以不经过NAT直接互访”这一Kubernetes集群最基本的技术要求。Flannel是一种SDN技术,它可以在Kubernetes集群中实现容器网络。Flannel的工作方式是依赖etcd实现统一的配置管理机制,当一台服务器上的Flannel启动时,它会连接所配置的etcd集群,从中取到当前的网络配置以及其他已有服务器已经分配的IP段,并从未分配的IP段中选取其中之一作为自己的IP段。路由也由Flannel完成,网络流量先进入Flannel控制的Tunnel中,由Flannel根据当前的IP段映射表转发到对应的服务器上
(1)安装flannel
使用下面的yam文件安装flannel,执行命令
kubectl apply -f kube-flannel.yml(2)查看安装结果
kubectl get po -A |grep flannel
安装flannel之后,它对主机做了什么
1、创建一个名为flannel.1的VXLAN网卡

可以看到mtu为1450(IP头、UDP头、MAC头、vxlan协议共占了50)。dstport为8472,local IP为节点IP,查看flannel.1的信息如下
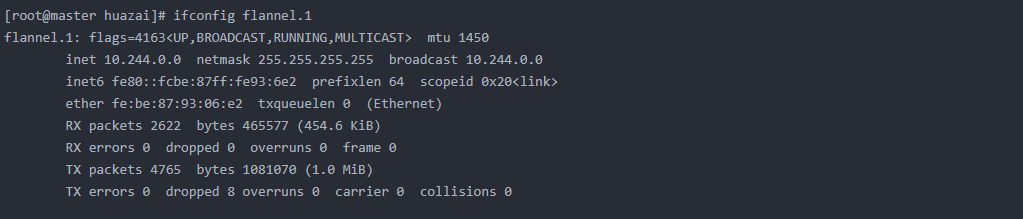
2、创建到其他节点pod cidrs(可通过kubectl get node master -o yaml得知)的路由表,主要是能让Pod中的流量路由到flannel.1接口

3、在节点中添加一条该节点的IP及VTEP设备的静态ARP缓存

以上的mac地址均为对应节点上flannel.1设备的mac
pod间如何进行访问
1、同一个节点的pod如何访问
以下面两个pod为例,两个pod都在node1,ip分别为10.244.1.8、10.244.1.9,假设在ip为10.244.1.8的pod中去ping ip为10.244.1.9的pod

进入pod ip为10.244.1.8的pod中

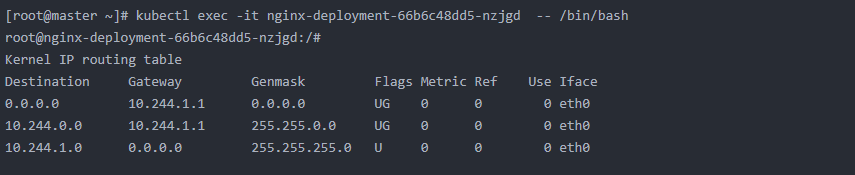
查看其路由

可以发现在同一个节点上的pod,直接进行访问了(在同一个网络段),没有经过转发。进入另外一个pod中查看路由,发现也是一样的
2、不同节点的pod如何访问
以下面两个pod为例,其中一个pod在node1上,IP为10.244.1.8,另外一个pod在node2,IP为10.244.2.4

进入pod ip为10.244.1.8的pod中

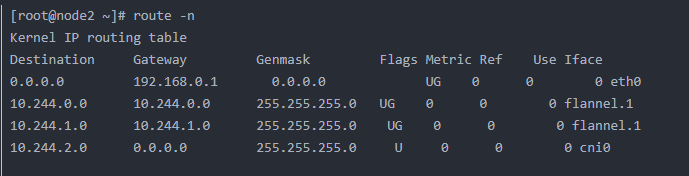
查看其路由 root@nginx-deployment-66b6c48dd5-jcwc9:/# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.244.1.1 0.0.0.0 UG 0 0 0 eth0 10.244.0.0 10.244.1.1 255.255.0.0 UG 0 0 0 eth0 10.244.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0 可以发现如果是执行ping 10.244.2.4则需要经过10.244.1.1,而10.244.1.1为node1上cn0的IP,cni0为flannel自己创建的网桥

再查看node1上的路由
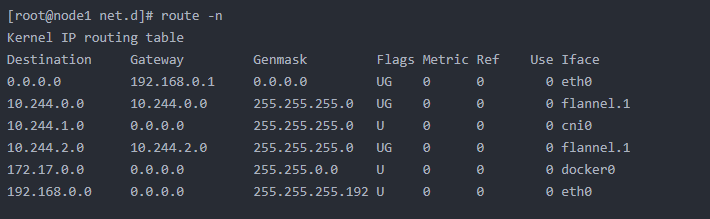
由路由发现,目标地址为10.244.2.0的数据包的下一跳为10.244.2.0,且要通过flannel.1,flannel.1作为一个VTEP设备,收到报文后将按照VTEP的配置进行封包。查看node1上的arp和fdb
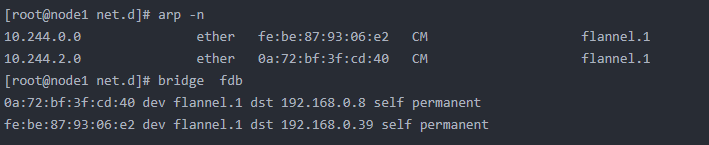
这里的话,通过etcd可以得知10.244.2.4在node2上,并且可以得到node2的IP,并且通过node1上转发表,可以知道node2上对应的VTEP的mac,然后根据flannel.1设备创建时的设置参数(VNI、local IP、Port)进行VXLAN封包。然后数据包通过node1跟node2之间的网络连接,VXLAN包到达node2,通过端口8472,VXLAN包被转发给VTEP设备flannel.1进行解包,解封装后的IP包匹配node2中的路由表(10.244.2.0),内核将IP包转发给cni0。
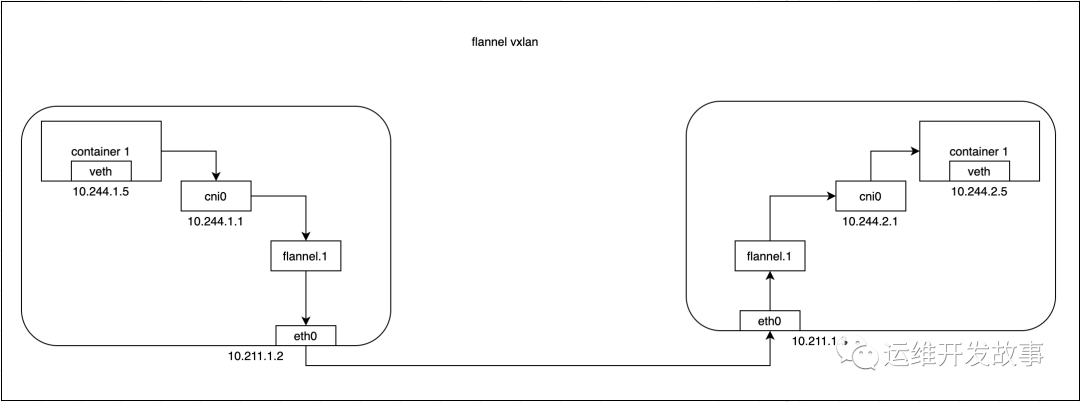
通过以上发现,不同节点上的pod要互相进行访问时,需要通过主机路由,需要经过内核的封包解包操作,整个过程如下所示:
参考资料
- 正确的在Kubernetes集群中使用SDN技术方法_Kubernetes中文社区
- Kubernetes:SDN网络模型 - koktlzz - 博客园
- 滑动验证页面
- https://sookocheff.com/post/kubernetes/understanding-kubernetes-networking-model/
- https://www.kubernetes.org.cn/4538.html
- https://koktlzz.github.io/posts/explorations-on-the-openshift-sdn-network-model/
- 还有人不知道Overlay网络?看完这个你就全懂了-CSDN博客
- https://feisky.gitbooks.io/sdn/content/
- https://sdn.feisky.xyz/rong-qi-wang-luo/index/kubernetes
- https://sdn.feisky.xyz/sdn-and-nfv/index
- https://www.cnblogs.com/goldsunshine/p/10740928.html
- https://blog.csdn.net/wanger5354/article/details/122401717

















 1332
1332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









