







- 在开发过程中 常常读取excel的数据,一般excel第一行数据做为标题,而我碰到一个需求是标题不一定在第一行,而且标题还会出现竖向,横向合并等情况。又该怎么实现呢?请看下面分析
场景分析
-
我们的需要的标题是 场景1 第一行数据:姓名,性别,年龄 等
-
场景1 比较常见的excel第一行一般为标题:

-
场景2 多行标题并且含有标题合并现象
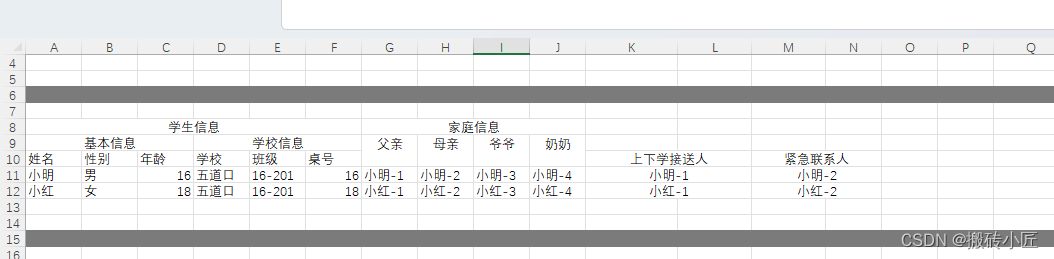
-
场景3 标题含有合并以及标题之间有几列是空格的情况
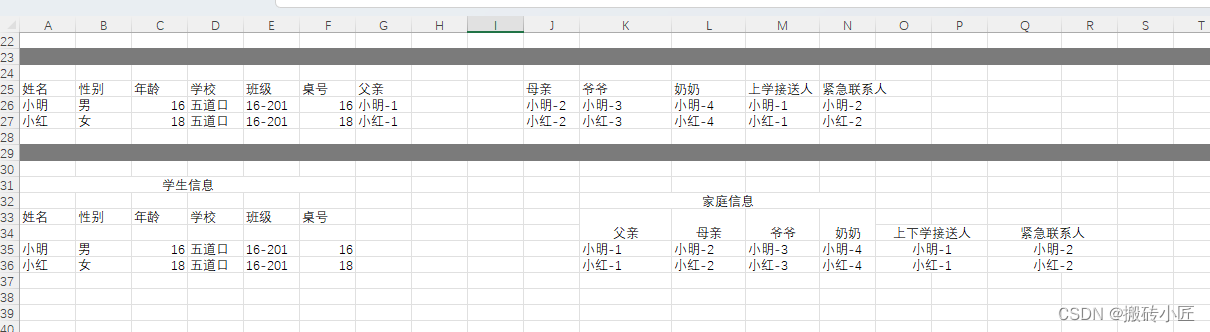
-
场景4 (待实现)应该可以在excel指定列 如图标颜色的是需要的标题

实现分析
- 借助工具 easyExcel
- easyExcel 可以设置从第几行读取数据,我们只要知道标题所在的范围去解析标题
比如:场景1 标题在第一行范围为A1:L1, 场景2 标题范围为 A10:N10
代码实现
- 获取标题
/**
* 获取excel的标题 适用于excel的标题所在行有合并单元格格式
* @param file
* @param headStartIndex 标题所在单元格行号(从0开始) eg:A1:B10, result:1
* @param headEndIndex 标题所在单元格行号(从0开始) eg:A1:B10, result:10
* @return
*/
public static List<String> readExcelHead(MultipartFile file,int headStartIndex,int headEndIndex) {
//表头
List<String> headList = new ArrayList<>();
Map<Integer,Object> headMap = new LinkedHashMap<>(16);
try {
EasyExcelFactory.read(file.getInputStream(), new AnalysisEventListener<Map<Integer, Object>>() {
/**
* 单次缓存的数据量
*/
public static final int BATCH_COUNT = 1000;
/**
*临时存储
*/
private List<Map<Integer, Object>> cachedDataList =ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
@Override
public void invoke(Map<Integer, Object> data, AnalysisContext context) {
cachedDataList.add(data);
if (cachedDataList.size() >= BATCH_COUNT) {
saveData();
// 存储完成清理 list
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData();
}
private void saveData() {
if (cachedDataList.size() > 0) {
List<Map<Integer, Object>> subData = CollectionUtil.sub(cachedDataList, 0, headEndIndex - headStartIndex +1);
for (int i = 0; i < subData.size(); i++) {
Map<Integer, Object> dataMap = subData.get(i);
for (int j = 0; j < dataMap.keySet().size(); j++) {
if (ObjectUtil.isNotNull(dataMap.get(j))) {
headMap.put(j,dataMap.get(j));
}
}
}
}
}
/**
* 在转换异常 获取其他异常下会调用本接口。抛出异常则停止读取。如果这里不抛出异常则 继续读取下一行。
*
* @param exception
* @param context
* @throws Exception
*/
@Override
public void onException(Exception exception, AnalysisContext context) {
log.error("解析失败,但是继续解析下一行:{}", exception.getMessage());
if (exception instanceof ExcelDataConvertException) {
ExcelDataConvertException excelDataConvertException = (ExcelDataConvertException) exception;
log.error("第{}行,第{}列解析异常,数据为:{}", excelDataConvertException.getRowIndex(),
excelDataConvertException.getColumnIndex(), excelDataConvertException.getCellData());
}
}
}).sheet().headRowNumber(headStartIndex).doRead();
} catch (IOException e) {
log.error("读取文件失败:{}", ExceptionUtil.stacktraceToString(e));
}
//返回数据跟excel标题顺序保持一致
List<Integer> keyList = headMap.keySet().stream().sorted().collect(Collectors.toList());
keyList.stream().forEach(key -> {
headList.add(StrUtil.toString(headMap.get(key)));
});
return headList;
}
- 获取Excel内容
/**
* 获取excel的内容 适用于excel的标题所在行有合并单元格格式
* @param file
* @param headStartIndex 标题所在单元格行号(从0开始) eg:A1:B10, result:1
* @param headEndIndex 标题所在单元格行号(从0开始) eg:A1:B10, result:10
* @return
*/
public static List<Map<String, Object>> readExcel(MultipartFile file,int headStartIndex,int headEndIndex) {
List<Map<String, Object>> mapList = CollUtil.newArrayList();
//表头
Map<Integer, String> importHeads = new HashMap<>();
try {
EasyExcelFactory.read(file.getInputStream(), new AnalysisEventListener<Map<Integer, Object>>() {
/**
* 单次缓存的数据量
*/
public static final int BATCH_COUNT = 1000;
/**
*临时存储
*/
private List<Map<Integer, Object>> cachedDataList =ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
@Override
public void invoke(Map<Integer, Object> data, AnalysisContext context) {
cachedDataList.add(data);
if (cachedDataList.size() > 0) {
List<Map<Integer, Object>> subData = CollectionUtil.sub(cachedDataList, 0, headEndIndex -headStartIndex +1);
for (int i = 0; i < subData.size(); i++) {
Map<Integer, Object> dataMap = subData.get(i);
for (int j = 0; j < dataMap.keySet().size(); j++) {
if (ObjectUtil.isNotNull(dataMap.get(j))) {
importHeads.put(j,StrUtil.toString(dataMap.get(j)));
}
}
}
}
if (cachedDataList.size() >= BATCH_COUNT) {
//转换表头
executeMapHeader();
// 存储完成清理 list
cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT);
}
}
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
executeMapHeader();
}
/**
* 在转换异常 获取其他异常下会调用本接口。抛出异常则停止读取。如果这里不抛出异常则 继续读取下一行。
*
* @param exception
* @param context
* @throws Exception
*/
@Override
public void onException(Exception exception, AnalysisContext context) {
log.error("解析失败,但是继续解析下一行:{}", exception.getMessage());
if (exception instanceof ExcelDataConvertException) {
ExcelDataConvertException excelDataConvertException = (ExcelDataConvertException) exception;
log.error("第{}行,第{}列解析异常,数据为:{}", excelDataConvertException.getRowIndex(),
excelDataConvertException.getColumnIndex(), excelDataConvertException.getCellData());
}
}
private void executeMapHeader() {
if (ObjectUtil.isNotNull(importHeads)) {
if (CollUtil.isEmpty(mapList)) {
cachedDataList = CollUtil.sub(cachedDataList,headEndIndex-headStartIndex,cachedDataList.size());
}
cachedDataList.forEach(data -> {
LinkedHashMap<String, Object> dataMap = new LinkedHashMap<>(16);
//返回的数据跟excel导入的数据顺序保持一致
List<Integer> keyList = importHeads.keySet().stream().sorted().collect(Collectors.toList());
keyList.stream().forEach(key -> {
dataMap.put(importHeads.get(key), data.get(key));
});
mapList.add(dataMap);
});
}
}
}).sheet().headRowNumber(headStartIndex).doRead();
} catch (IOException e) {
log.error("读取文件失败:{}", ExceptionUtil.stacktraceToString(e));
}
mapList.remove(0);
return mapList;
}
展示结果
-
读取头结果
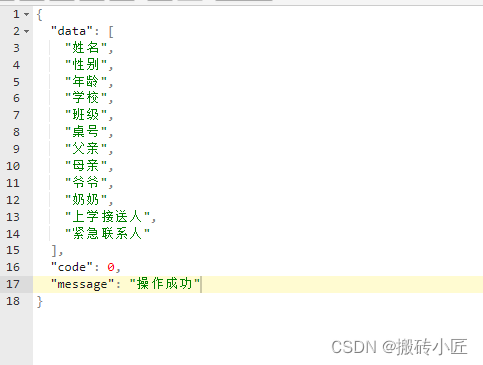
-
读取数据结果
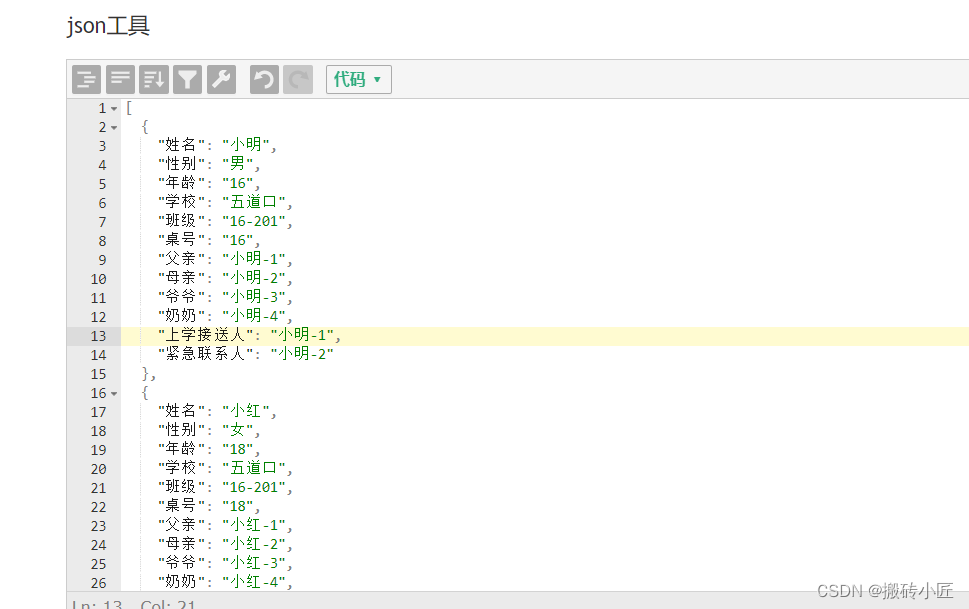















 9102
9102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









