







一.前提:
1.什么叫哈希表值?
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值,使用hashCode()方法,支持此方法是为了提高哈希表的性能。
采用散列表(哈希表),根据 key 的 hashcode 值生成数组下标(通过内存地址直接查找,没有任何判断),时间复杂度完美情况下可以达到 n1(和数组相同,但是比数组用着爽多了,但是需要多出很多内存,相当于以空间换时间)了,反之时间换空间。
使用哈希表值很方便,在查询检索的时候很快的查找到对应的元素的存储地址。(根据元素计算得到哈希表值,再根据哈希表值来取出该元素)
!!!判定集合元素相等标准是哈希表值相等,还要equals为真。
详情参考:
https://blog.csdn.net/zj15527620802/article/details/88547914(标题:最详细的equal和hashcode详解)
https://www.cnblogs.com/Qian123/p/5703507.html#_labelTop(标题:Java提高篇——equals()与hashCode()方法详解)
测试:::
可以来重写hashCode方法和equals方法来测试,注意:如果要重写方法,两种方法应该同时重写(因为一个方法满足相同,则另一个方法理论上也应该相同)
分析equals返回true和hashCode返回相同哈希表值情况:::
1.如果元素值相等,但哈希表值不相同,表示存放在不同的地址(一般表现在添加新的对象,虽然对象含有的值相等,但是不是一个对象,这是可以添加成功的)
2.如果哈希表值相同,元素不相等,这就很麻烦!因为把两个不相等的元素放在一个地址上很麻烦,只能通过增加一个链式结构保存对象,这种情况会导致性能下降(所以哈希表值相同,元素值也应该相等,即为同一个对象)
3.如果哈希表值相同,而且元素值相等,即表示同一个元素对象(一般表现在你添加一个相同的元素对象,并没有添加成功,因为集合中已经存在了!)
二.接口目录:
- Collection接口(三个子接口Set,Queue,List),Map接口
三.Collection接口目录:
- Collection接口的抽象方法功能:添加元素/集合,清空集合,移除元素/集合,判空/包含,返回Iterator对象用于遍历集合元素,集合元素个数size(),转换成数组toArray(),
//测试条件批量移除方法
HashSet<String> hashSet = new HashSet<String>();
hashSet.add("123");
hashSet.add("456");
hashSet.removeIf(new Predicate<String>() {
@Override
public boolean test(String t) {
// TODO Auto-generated method stub
if (t.equals("123")) {
return true;
}
return false;
}
});
System.out.println(hashSet);
结果:
[456]- 遍历集合方式:
- 1.使用父接口Iterable的forEach(Consumer action)方法,实现函数式接口Consumer
//使用函数式接口Consumer的accept方法迭代
HashSet<String> hashSet = new HashSet();
hashSet.add("你好啊");
hashSet.add("你好");
hashSet.add("你");
hashSet.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println("我是迭代方法:" + s);
}
});
//Lambda表达式写法
hashSet.forEach(s -> System.out.println("我是迭代方法2:" + s));
结果:
我是迭代方法:你
我是迭代方法:你好
我是迭代方法:你好啊
我是迭代方法2:你
我是迭代方法2:你好
我是迭代方法2:你好啊- 2 .使用迭代器集合接口Iterator(该接口不同于其他集合接口,只用于遍历)
//使用迭代器接口对象
常用方法:
hasNext() //返回是否有下一个
next() //返回下一个元素
remove() //移除当前元素
forEachRemaining(Consumer action) //使用第一种遍历方式
//测试1
Iterator<String> iterator = hashSet.iterator();
while (iterator.hasNext()) {
System.out.println("我是迭代器3:" + iterator.next());
}
结果:
我是迭代器3:你
我是迭代器3:你好
我是迭代器3:你好啊
//测试2
Iterator<String> iterator2 = hashSet.iterator();
while (iterator2.hasNext()) {
String s = iterator2.next();
if ("你好".equals(s)) {
iterator2.remove();
}
System.out.println("我是迭代器4:" + s);
}
Iterator<String> iterator3 = hashSet.iterator();
iterator3.forEachRemaining(s -> System.out.println("我是迭代器5:" + s));
结果:
我是迭代器4:你
我是迭代器4:你好
我是迭代器4:你好啊
我是迭代器5:你
我是迭代器5:你好啊- 3.通用forEach方法遍历集合
-
Set接口:(不重复)
- HashSet:采用哈希算法
- LinkedHashSet:HashSet的子类,以插入的顺序排序,利于迭代,在哈希表的基础上使用链表的数据结构维护插入顺序
- TreeSet:采用红黑树的数据结构(采用两种排序方式:自然排序(默认),定制排序)
- TreeSet额外的方法:
- Comparator comparator():若采用定制排序,返回定制排序所使用的Comparator;若采用自然排序,返回null
- Object first():返回集合第一个元素
- Object last():返回集合最后一个元素
- Object lower(Object e):返回指定元素(可以不是元素中的元素)之前的一个元素
- Object highter(Object e):返回指定元素(可以不是元素中的元素)之后的一个元素
- SortSet subSet(Object fromElement, Object toElement):返回两元素之间的子集
- SortSet headSet(Object toElement):返回指定元素之前的子集
- SortSet tailSet(Object fromElement):返回指定元素之后的子集
- 自然排序
- 自动调用compareTo方法比较大小排序(升序),返回0表示两个元素值相等,大于0表示前一个元素值大,相反元素值小
- 某些常用类已经实现了Comparable接口的compareTo方法:如BigDecimal,BigInteger,Character,Boolean,String,Date,Time
- 定制排序
- 定制排列顺序,如降序,调用Comparable接口的compare(e1,e2)方法
- TreeSet额外的方法:
//测试实现函数式comparator接口,完成倒序
TreeSet<String> treeSet = new TreeSet<String>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
// TODO Auto-generated method stub
return -o1.compareTo(o2);
}
});
treeSet.add("123");
treeSet.add("789");
treeSet.add("134");
treeSet.add("12");
treeSet.add("1234");
treeSet.add("789");
System.out.println(treeSet);
结果:
[789, 134, 1234, 123, 12]- Set性能分析:
- HashSet和TreeSet是Set集合的典型,HashSet性能总是比TreeSet好,因为TreeSet需要额外的红黑树算法维护顺序。
- HashSet方便添加,查询
- LinkedHashSet方便遍历
- 以上集合类都不是线程安全的,可以通过Collections工具类的synchronizedSortedSet方法保证Set集合同步性,防止多线程非同步访问
SortedSet<String> treSet = Collections.synchronizedSortedSet(new TreeSet<String>());
-
List接口:(可重复)
- List接口相对于父接口额外的方法:
-
voidadd(int index, E element)将指定的元素插入此列表中的指定位置(可选操作)。
booleanaddAll(int index, Collection<? extends E> c)将指定集合中的所有元素插入到此列表中的指定位置(可选操作)。
Eget(int index)返回此列表中指定位置的元素。
ListIterator<E>listIterator()返回列表中的列表迭代器(按适当的顺序)。
ListIterator<E>listIterator(int index)从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
Eremove(int index)删除该列表中指定位置的元素(可选操作)。
default voidreplaceAll(UnaryOperator<E> operator)将该列表的每个元素替换为将该运算符应用于该元素的结果。
booleanretainAll(Collection<?> c)仅保留此列表中包含在指定集合中的元素(可选操作)。
Eset(int index, E element)用指定的元素(可选操作)替换此列表中指定位置的元素。
default voidsort(Comparator<? super E> c)使用随附的
Comparator排序此列表来比较元素。List<E>subList(int fromIndex, int toIndex)返回此列表中指定的 fromIndex (含)和 toIndex之间的视图。
-
- List接口相对于父接口额外的方法:
- sort方法中实现
Comparator函数式接口来排序://测试sort方法实现函数式接口Comparator ArrayList<String> arrayList = new ArrayList<String>(); arrayList.add("123456"); arrayList.add("1"); arrayList.add("789"); arrayList.add("12"); arrayList.add("157"); //比长度 arrayList.sort(new Comparator<String>() { @Override public int compare(String o1, String o2) { // TODO Auto-generated method stub return o1.length()-o2.length(); } }); System.out.println(arrayList); //如果使用compareTo结果又不一样,比较大小,倒序 arrayList.sort(new Comparator<String>() { @Override public int compare(String o1, String o2) { // TODO Auto-generated method stub return -o1.compareTo(o2); } }); System.out.println(arrayList); 结果: [1, 12, 789, 157, 123456] [789, 157, 123456, 12, 1] - List实现类 ArrayList和Vector的异同:
- 相同之处:两者都是基于数组实现的List类,而且方法上功能很相似。
- 不同之处:ArrayList线程不安全,必须通过Collections工具类的方法保证同步性,而Vector是线程安全的(但依然不推荐使用),该类太过古老,由于线程安全,性能相对ArrayList较低。
//ArrayList和Vector通过一个initialCapacity参数来设置数组长度
//当添加元素超出数组长度,就会重分配数组,默认重分配长度增加10
//void ensureCapacity(int minCapacity) 设置最小重分配增加长度(一次性设置合适的最小长度,目的是减少多次重分配数组带来的性能损耗)
//void trimToSize() 调整数组长度为现有元素的长度(目的是节省存储空间)
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.ensureCapacity(30);
arrayList.add("123456");
arrayList.add("1");
arrayList.add("789");
arrayList.add("12");
arrayList.add("157");
arrayList.trimToSize();-
Queue接口:(可重复)
- Queue接口抽象方法:
-
booleanadd(E e)将指定的元素插入到此队列中,如果可以立即执行此操作,而不会违反容量限制,
true在成功后返回IllegalStateException如果当前没有可用空间,则抛出IllegalStateException。Eelement()检索,但不删除,这个队列的头。
booleanoffer(E e)如果在不违反容量限制的情况下立即执行,则将指定的元素插入到此队列中。
Epeek()检索但不删除此队列的头,如果此队列为空,则返回
null。Epoll()检索并删除此队列的头,如果此队列为空,则返回
null。Eremove()检索并删除此队列的头。
-
- 两个值得注意的实现类:
- PriorityQueue实现类:
- 是一个标准的队列实现类,不是绝对的队列,是因为违背了“先进先出”的原则,队列的顺序是按照元素的大小重新排序
- 分为自然排序和定制排序(前面已经介绍,就是实现函数式接口)
- LinkedList实现类:
- 是Queue和List的实现类,综合了队列,栈,链表的特点。是一个双向链表。
//测试LinkedList实现类 LinkedList<String> linkedList = new LinkedList<String>(); linkedList.add("123"); //插入到队列 linkedList.offerLast("345"); //插入到队尾 linkedList.offer("12"); //插入到队列 linkedList.offerFirst("456"); //插入到队头 linkedList.push("999"); //插入到栈顶(队头) System.out.println(linkedList); //结果:[999, 456, 123, 345, 12] System.out.println(linkedList.pop()); //出栈 结果:999 System.out.println(linkedList.peekFirst()); //检索不删除队头 结果:456 System.out.println(linkedList.peekLast()); //检索不删除队尾 结果:12 System.out.println(linkedList); //结果:[456, 123, 345, 12] System.out.println(linkedList.pollFirst()); //检索并删除队头 结果:456 System.out.println(linkedList); //结果:[123, 345, 12]
- 是Queue和List的实现类,综合了队列,栈,链表的特点。是一个双向链表。
- PriorityQueue实现类:
- 各种线性表的性能分析:
- 随机访问时,以数组为底层实现比较好;插入,删除操作时,以链表为底层实现比较好。总体上,ArrayList性能比LinkedList性能好。
- ArrayList,Vector适合遍历
- LinkedList适合插入,删除;若要遍历,最好使用迭代器Iterator
- 线程安全依然使用Collections工具类
- Queue接口抽象方法:
四.Map接口目录:
- Map接口抽象方法功能:清空(clear),移除(remove),添加(put,putAll),获取值(get),获取所有键的Set集合(keySet),获取所有值的Collections集合(values),判空(isEmpty),判是否包含键/值(containsKey,containsValue),获取键值对组成的Set集合-每个元素都是Map.Entry(Entry是Map的内部类)的对象(entrySet)
- 对每个Map元素,内部类Entry封装了一个键值对,Entry的三个方法:getKey(),getValue(),setValue(V value)(对当前元素设置新的value)
- Java8新增的Map方法:
- forEach(BiConsumer action):遍历键值对
- replace(Object key, Object value):替换key对应的value,若不存在key,就返回false
//测试forEach方法实现函数式接口BiComsumer
HashMap<String, String> hashMap = new HashMap<String, String>();
hashMap.put("1", "你好啊");
hashMap.put("2", "你");
hashMap.put("3", "你好");
hashMap.put("4", "你好啊!");
hashMap.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String t, String u) {
// TODO Auto-generated method stub
System.out.println("键:" + t + "\t值:" + u);
}
});
结果:
键:1 值:你好啊
键:2 值:你
键:3 值:你好
键:4 值:你好啊!- HashMap和Hashtable的异同:
- 相同之处:都采用哈希算法,key通过equals和hashCode方法作为键是否相同的标准,value直接通过equals比较相等
- 不同之处:Hashtable是线程安全的(太老,不推荐使用),HashMap是线程不安全的(可以通过Collections工具类手动调整为线程安全),所以性能HashMap高一些。Hashtable不允许key和value为null,HashMap允许key和value为null,但key为null最多一个。
- LinkedHashMap:双向链表,排序按照插入顺序,和LinkedHashSet类似
- Hashtable的子类Properties(属性类):用于处理存储Map对象的属性文件,key和value都是String类型。Properties方法:
- String getProperty(String key):获取属性值
- String getProperty(String key, String defaultValue):获取属性值,不存在就返回默认值
- Object setProperty(String key, String defaultValue):设置键值对,类似于添加属性
- void load(InputStream i):把输入流的键值对加载到Propertities中
- void store(OutputStream o, String comments):将Properties中的键值对输出到指定的属性文件中(comments是注释内容)
- 下面测试Properties类和属性文件:
- 初始文件内容:
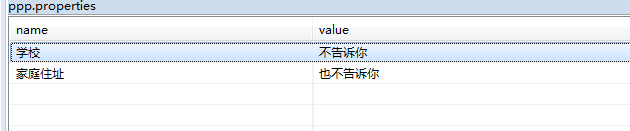
 (源文件为十六进制)
(源文件为十六进制)
开始测试代码:
//先加载属性文件内容到Properties,在加新的属性,最后将Properties输出到指定的文件
Properties p = new Properties();
try {
p.load(new FileInputStream("ppp.properties"));
} catch (FileNotFoundException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
p.setProperty("姓名", "大傻");
p.setProperty("性别", "中");
p.setProperty("年龄", "-100");
try {
p.store(new FileOutputStream("ppp.properties"), "我是注释");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println(p);
控制台结果:
{性别=中, 家庭住址=也不告诉你, 姓名=大傻, 学校=不告诉你, 年龄=-100}- 属性文件内容:
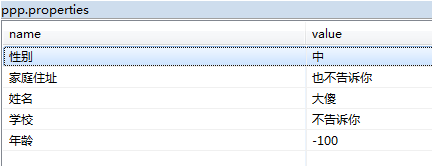
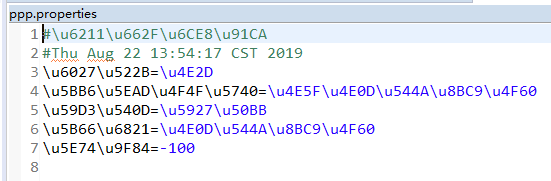
- TreeMap:
- TreeMap是一个红黑树的数据结构
- TreeMap和TreeSet方法很相似
- 两种排序方式:自然排序,定制排序
- Map接口实现类性能分析:
- HashMap,Hashtable性能比TreeMap好,一般都使用HashMap
- TreeMap的好处就是有序
- LinkedHashMap也是有序,不过是添加顺序,都比HashMap性能要低
- HashSet和HashMap性能选项:
- 都是Hash算法决定存储位置,存储元素的位置称为“桶”,单个“桶”只存放一个元素为最好性能,一个以上就会“hash冲突”(添加链式存储解决,前面已经说过)。
- 容量:桶的数量
- 初始化容量:创建hash表时,桶的数量
- 尺寸:hash表中的存在记录数量
- 负载因子:等于尺寸/容量,0表示空的hash表,0.5表示半空,以此类推。轻负载的hash表冲突少,适宜插入和查询,但迭代器迭代较慢
- 负载极限:“负载极限”是0~1的数值,决定了hash表的最大填满程度,当负载因子达到负载极限时,hash表自动成倍增加容量。HashSet,HashMap,Hashtable默认负载极限是0.75(这是考虑时间和空间的折中值)。很明显,负载极限升高,空间占用相对减少,但数据查询时间增加。
- 都是Hash算法决定存储位置,存储元素的位置称为“桶”,单个“桶”只存放一个元素为最好性能,一个以上就会“hash冲突”(添加链式存储解决,前面已经说过)。
五.操作集合的工具类 Collections:
Collections提供了排序,查询,修改操作,还有设置集合对象不可变,对集合对象实现同步控制等。
- List集合排序操作:
-
static voidreverse(List<?> list)反转指定列表中元素的顺序。
static voidrotate(List<?> list, int distance)将指定列表中的元素旋转指定的距离。
static voidshuffle(List<?> list)使用默认的随机源随机排列指定的列表。
static voidshuffle(List<?> list, Random rnd)使用指定的随机源随机排列指定的列表。
static <T extends Comparable<? super T>>
voidsort(List<T> list)根据其元素的natural ordering对指定的列表进行排序。自然排序
static <T> voidsort(List<T> list, Comparator<? super T> c)根据指定的比较器引起的顺序对指定的列表进行排序。定制排序
static voidswap(List<?> list, int i, int j)交换指定列表中指定位置的元素。
-
//测试List集合的各种排序
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("456");
arrayList.add("123");
arrayList.add("12");
arrayList.add("4");
System.out.println(arrayList);
Collections.reverse(arrayList);
System.out.println(arrayList);
Collections.sort(arrayList);
System.out.println(arrayList);
Collections.shuffle(arrayList);
System.out.println(arrayList);
Collections.swap(arrayList,1,2);
System.out.println(arrayList);
Collections.rotate(arrayList,-2);
System.out.println(arrayList);
结果:
[456, 123, 12, 4]
[4, 12, 123, 456]
[12, 123, 4, 456]
[12, 4, 456, 123]
[12, 456, 4, 123]
[4, 123, 12, 456]- 查找,替换操作:
-
static <T> intbinarySearch(List<? extends Comparable<? super T>> list, T key)使用二叉搜索算法搜索指定对象的指定列表。二分法搜索List集合元素
static <T> intbinarySearch(List<? extends T> list, T key, Comparator<? super T> c)使用二叉搜索算法搜索指定对象的指定列表。
static <T> voidfill(List<? super T> list, T obj)用指定的元素替换指定列表的所有元素。
static intfrequency(Collection<?> c, Object o)返回指定元素出现次数。
static intindexOfSubList(List<?> source, List<?> target)返回指定源列表中指定目标列表的第一次出现的起始位置,如果没有此类事件,则返回-1。
static intlastIndexOfSubList(List<?> source, List<?> target)返回指定源列表中指定目标列表的最后一次出现的起始位置,如果没有此类事件则返回-1。
static <T extends Object & Comparable<? super T>>
Tmax(Collection<? extends T> coll)根据其元素的 自然顺序返回给定集合的最大元素。
static <T> Tmax(Collection<? extends T> coll, Comparator<? super T> comp)根据指定的比较器引发的顺序返回给定集合的最大元素。
static <T extends Object & Comparable<? super T>>
Tmin(Collection<? extends T> coll)根据其元素的 自然顺序返回给定集合的最小元素。
static <T> Tmin(Collection<? extends T> coll, Comparator<? super T> comp)根据指定的比较器引发的顺序返回给定集合的最小元素。
static <T> booleanreplaceAll(List<T> list, T oldVal, T newVal)将列表中一个指定值的所有出现替换为另一个。
-
//测试查找,替换操作
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("456");
arrayList.add("123");
arrayList.add("12");
arrayList.add("4");
Collections.sort(arrayList);
System.out.println(arrayList);
System.out.println("List集合中456的位置" + Collections.binarySearch(arrayList,"456"));
System.out.println("集合最大值:" + Collections.max(arrayList));
System.out.println("集合最小值:" + Collections.min(arrayList));
Collections.replaceAll(arrayList,"12","33333");
System.out.println(arrayList);
System.out.println("集合中‘123’出现次数:" + Collections.frequency(arrayList, "123"));
Collections.fill(arrayList, "玩完");
System.out.println("集合元素全体替换成:" + arrayList);
结果:
[12, 123, 4, 456]
List集合中456的位置3
集合最大值:456
集合最小值:12
[33333, 123, 4, 456]
集合中‘123’出现次数:1
集合元素全体替换成:[玩完, 玩完, 玩完, 玩完]- synchronizedXXX()方法多线程线程同步控制:
//4个线程安全同步控制举例
Collection<String> c = Collections.synchronizedCollection(new ArrayList<>());
List<String> l = Collections.synchronizedList(new ArrayList<>());
Set<String> s = Collections.synchronizedSet(new HashSet<>());
Map<String, String> m = Collections.synchronizedMap(new HashMap<>()); - 设置不可变集合:
- emptyXxx():返回空的不可变集合对象
- singleonXxx():返回只包含一个元素的不可变集合对象
- ummodifiableXxx():返回不可变集合对象
//测试不可变集合对象
List l = Collections.emptyList();
//l.add("123"); //添加抛异常
System.out.println(l);
List ll = Collections.singletonList("456");
//ll.add("222"); //添加抛异常
System.out.println(ll);
ArrayList<String> arrayList = new ArrayList<>();
arrayList.add("777");
List lll = Collections.unmodifiableList(arrayList);
//lll.add("999"); //添加抛异常
System.out.println(lll);
结果:
[]
[456]
[777]















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









