






DrissionPage框架应用
Scrapy框架可以自定义请求,我们经常使用的selenium,pypuppteer,playwight等模拟浏览器的环境执行网络的请求;但是以上都有被检测的风险,新晋浏览器防检测工具,不仅不需要繁琐的安装浏览器的内核,也不需要为浏览器升级后带来的版本不支持烦劳了。它可以自动调用我们本地的浏览器执行网络请求;他不仅支持浏览器的操作还支持类似requests的网络请求sessionpage,webpage,可以在模式之间相互切换,使用浏览器模式获取数据后,再使用requests的模式处理数据。在我们遇到一些不好处理的反爬虫的情况下,就可以使用这个工具帮助我们模拟人类的操作,达到获取数据的结果;下面我们介绍如何使用dp及如何与scrapy结合,最后我们部署远程浏览器,调用执行;
-
安装DrissionPage
pip install DrissionPage
-
使用dp运行接口案例
from DrissionPage import ChromiumPage,ChromiumOptions
co = ChromiumOptions()
co.headless(True)
# 1、设置无头模式:co.headless(True)
# 2、设置无痕模式:co.incognito(True)
# 3、设置访客模式:co.set_argument('--guest')
# 4、设置请求头user-agent:co.set_user_agent()
# 5、设置指定端口号:co.set_local_port(7890)
# 6、设置代理:co.set_proxy('http://localhost:2222')
page = ChromiumPage(co)
page.get(url)
# page.wait.ele_displayed("c:.price") 等待某一个css样式的出现
page.wait.load_start() # 等待页面加载完成
print(page.html)
dp同样支持css、xpath的数据提取语法格式,但是使用上和parsel库还有写差别;想学习的可以去看 官方文档
-
在scrapy中使用dp
scrapy的目录结构中有个middleware.py的文件,这个是scrapy的中间件,我们可以编写爬虫中间件、代理中间件、下载中间件等。本次我们使用下载中间件爬虫每次发起请求的结果都将被下载中间件拦截,并转发请求,将结果返回在转发回到爬虫。
from scrapy.http import HtmlResponse
from DrissionPage import ChromiumPage,ChromiumOptions
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
url = request.url
co = ChromiumOptions()
co.headless(True)
page = ChromiumPage(co)
try:
page.get(url)
# page.wait.ele_displayed("c:.price")
page.wait.load_start()
# page.listen.start('https://xxxb/ajax/price/') 监听接口
# res = page.listen.wait() # 等待并获取一个数据包
# print(res)
except Exception as e:
traceback.print_exc()
else:
return HtmlResponse(body=page.html,request=request,url=request.url,encoding="utf-8")
finally:
page.close()
这里编写好后就需要在settings.py的文件中启用中间件,格式为:
DOWNLOADER_MIDDLEWARES = {
# '项目名称.middlewares.ProxyMiddleware': 544,
'项目名称.middlewares.AladdinEDownloaderMiddleware': 543,
}
这样我们就配置好了scrapy中调用浏览器模拟请求了!但是我们在本地运行没有问题,线上就没办法运行,这是因为我们的dp会自动调用我们本地已有的浏览器执行网络请求,但是部署到线上服务器后,新的服务器没有安装浏览器,这个时候我就需要使用远程浏览器调用作为第三方的转发请求了。
-
安装部署远程浏览器
这里我们使用docker 安装:
docker pull selenium/standalone-chrome
线上的docker.io会拉去失败,需要换国内的源,不换的话,就在本地把镜下先pull下来再上传服务器创建容器:
docker save -o standalone-chrome.tar selenium/standalone-chrome
# 使用工具上传这个tar包解析
docker load < standalone-chrome.tar

完成之后运行
docker images

开始创建容器并测试:
docker run -d -p 4444:4444 selenium/standalone-chrome
浏览器输入:ip:port/wd/hub
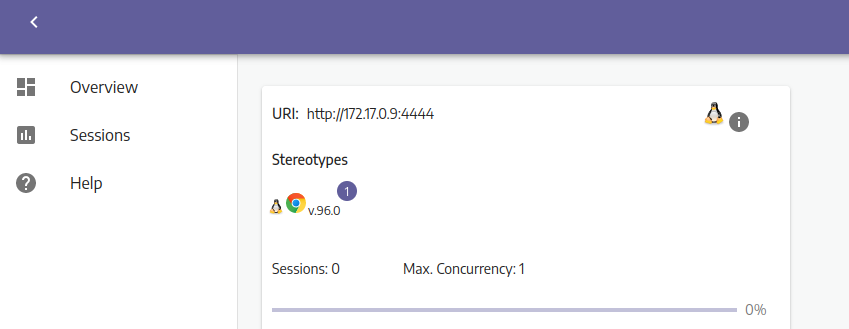
这样就安装成功了远程浏览器
把上面的代码稍微修改一下:
from scrapy.http import HtmlResponse
from DrissionPage import ChromiumPage,ChromiumOptions
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
url = request.url
co = ChromiumOptions()
co.headless(True)
co.set_argument('--no-sandbox')
co.set_argument('--incognito')
co.set_argument("addr_or_opts='192.168.2.144:4444/wd/hub'")
# page = ChromiumPage()
page = ChromiumPage(co)
try:
page.get(url)
# page.wait.ele_displayed("c:.price")
page.wait.load_start()
# page.listen.start('https://xxxb/ajax/price/') 监听接口
# res = page.listen.wait() # 等待并获取一个数据包
# print(res)
except Exception as e:
traceback.print_exc()
else:
return HtmlResponse(body=page.html,request=request,url=request.url,encoding="utf-8")
finally:
page.close()
就可以链接远程浏览器了
-
喜欢我的文章可以关注我并收藏:
博客站点
公众号搜索:爬虫与大模型开发
本文由 mdnice 多平台发布















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









