







Interactformer: Interactive Transformer and CNN for Hyperspectral Image Super-Resolution
论文地址
1、论文
【摘要】:
图像(HSIs)因其丰富的光谱信息而被广泛应用于各个领域。然而,受成像系统的限制,HSI 的低空间分辨率已成为一个重要问题。在这篇文章中,为了提高空间分辨率,Interactformer 被提议与 transformer 和 3-D 卷积神经网络 (CNN) 分支提取的全局和局部特征进行交互。在transformer分支中,设计了一个可分离的线性复杂度的self-attention模块,以解决传统self-attention机制由于二次复杂度而导致内存开销大的问题 。在 3-D CNN 分支中,联合应用光谱注意模块和 3-D 卷积,以更好地保护光谱波段之间的光谱相关性,促进 HSI 的局部特征提取。两个并行分支之间的交互注意单元旨在自适应地与局部和全局特征信息进行交互。与最先进的超分辨率 (SR) 方法相比,所提出的方法在模拟 SR 实验、真实 SR 实验和分类实验中重建了更好的 HSI,证明 Interactformer 可以在保留光谱的同时有效提高空间分辨率information.
Index Terms— 卷积神经网络 (CNN)、高光谱图像 (HSI) 超分辨率 (SR)、交互式注意单元 (IAU)、转换器。
I.简介
高光谱图像包含数百甚至数千个覆盖可见光和红外波长的连续光谱带[1],[2]。它们提供有关物体的丰富光谱信息,并反映细微的光谱特征。因此,高光谱图像(HSI)已成为遥感应用中重要且有价值的信息来源,例如土地覆盖分类[3],目标检测[4]和地质勘探[5]。但是,由于成像硬件的限制,HSI的空间分辨率通常较低 [6]。这限制了 HSI 在各个领域的实际应用。因此,提高 HSI 的空间分辨率非常重要。
超分辨率 (SR) [7] 通过软件算法提高空间分辨率来解决这个问题。从低分辨率(LR)图像获得高分辨率(HR)图像的过程是SR重建。研究人员已经为 HSI SR 提出了许多算法。它们可以分为多图像超分辨率 (MISR) [8]、[9] 和单图像超分辨率 (SISR) [10]、[11]。
第一类(MISR)是基于融合的方法,它通过合并 LR HSI 和 HR 辅助图像(例如全色图像(PAN)[12]、[13]或多光谱图像(MSI)[14]、[15])来生成 HR HSI ].董等。 [16] 将迭代 SR 算法展开到一个新的模型引导的深度卷积网络中,用于融合 LR HSI 和 HR PAN。新型结构保色网络[17]旨在处理LR HSIs丰富的光谱信息和HR MSIs复杂的结构特征,以获得SR HSIs。然而,这些基于融合的方法需要具有高空间分辨率的辅助图像(MSI 和 PAN),这些图像可能不容易获得。即使使用 HR 辅助图像,这些方法也需要对 LR HSI 和辅助图像进行精确的几何配准。这些缺点限制了基于融合的SR方法的应用。
第二类(SISR)由于不受辅助图像的限制而被广泛使用。主要的 SISR 方法包括插值、低秩张量近似 [18]、稀疏表示 [19] 和深度学习 [20]。插值方法通过简单地根据相邻像素值估计未知像素来调整图像大小或重新采样,这很难重建丢失的高频细节并导致边缘模糊。为了探索 HSI 的内在特征,提出了一种新的基于张量的方法 [18] 来实现 HSI 的空间 SR。黄等。 [19] 提出了一种通过基于多字典的稀疏表示的 SR 方法来解决 HSI 恢复问题。然而,这些方法效率低下,因为它们通常被表述为复杂的优化问题并且必须迭代求解。最近,基于深度学习的 SR 方法获得了良好的性能并且正在被越来越多的研究。基于深度学习的SR方法的主要思想是学习LR图像和对应的HR图像之间的非线性映射函数。董等。 [21]首先提出了一种用于自然图像超分辨率(SRCNN)的三层卷积神经网络。为了为了获得更好的性能,Kim 等人提出了一种非常深的超分辨率卷积网络 (VDSR)。 [22]。它通过增加网络深度显示出准确性的显着提高。
基于深度学习的方法由于其强大的学习能力,已经实现了自然图像的最先进的 SR 性能。然而,这些方法适用于具有三个波段(R、G 和 B)的自然图像,并不直接适用于 HSI。他们通常单独处理每个波段以实现 HSI SR,这很难保护 HSI 数据立方体的光谱特征。因此,特别需要一些用于 HSI SR 的算法。李等。 [23] 设计了一个分组的深度递归残差网络(GDRRN)来同时超分辨 HSI 的所有波段,它利用了递归结构和二维卷积。通过将输入图像分成几组以减少网络参数,为 HSI SR 开发了差分曲率多维网络 [24]。然而,二维卷积仅关注HSI的空间信息,固定的分组方式破坏了光谱相关性,从而导致光谱无序。为了缓解光谱无序问题,在[25]中引入了用于 HSI SR 的 3-D 全卷积神经网络 (3D-FCNN)。 3-D 卷积可以同时提取空间-光谱特征。胡等。 [26] 提出了一种 3-D 多尺度特征融合网络,并将光谱损失集成到训练中,以充分保护光谱相关性。为了进一步提高重建 HSI 的纹理质量,提出了两个对抗性学习网络 [27]、[28]。利用对抗损失来引导生成器有效地产生更精细的纹理细节。
然而,3-D 网络通常伴随着大量的参数和高计算复杂性。为了缓解 3-D 网络中的问题,提出了混合 2-D/3-D 卷积网络 (MCNet) [29]。与仅使用 3-D 卷积相比,它减少了网络操作的参数和浮点数。为了减少所需的硬件内存,Wang 等人。 [30] 通过聚合来自相邻光谱带的语义信息提出了一种单波段高光谱 SR 方法。为了同时提高空间和光谱分辨率,提出了空间-光谱联合 SR 方法 [31]。这些方法侧重于探索局部空间-光谱信息。 HSI 的全局特征很难提取。因此,提出了一种混合本地和非本地 3-D 注意力 CNN (HLNnet) [32] 来首先提取 HSI 的全局特征。
最近,自然语言处理 (NLP) 模型 transformer [33] 获得了越来越多的关注在图像分类 [34]、分割 [35] 和检测 [36] 等计算机视觉 (CV) 领域很受欢迎。 transformer的核心是self-attention,可以探索long-range dependencies。自注意力机制占用大量内存,限制了变压器在低级图像处理任务中的发展。因此,需要探索低计算资源的自注意力。 GCnet [37] 基于独立于查询的公式创建了一个简化的自我注意网络,这限制了查询像素的自适应性。最近,Liang 等人。 [39] 使用 Swin Transformer [38] 进行自然图像复原(SwinIR),取得了满意的效果。但是,它不适用于 HSI 数据立方体,因为光谱相关性被破坏了。此外,CNN 风格和 Transformer 风格的特征是互补的。结合的 CNN 和 Transformer 网络可以有效地提取图像特征。 STransFuse [40] 融合 CNN 和 Swin Transformer [38] 以提取局部特征,同时捕获远程依赖性。尽管如此,局部和全局特征只是简单地融合并且缺乏适当的交互。
为了解决这些缺点,提出了交互式转换器和 CNN(Interactformer)来捕获远程依赖并提取 HSI 的局部特征,同时自适应地交互。具体来说,通过将变换器和局部特征提取与频谱保留模块(LFESM)相结合,提出了一种具有两个并行分支的网络结构。 Transformer 由多层感知器 (MLP)、跳跃连接和可分离自注意力组成,可有效提取全局空间特征。廉价地挖掘全球空间结构信息很重要。 separable self-attention 模块的设计具有线性复杂度,同时更好地建模全局上下文。 LFESM 被构造为提取局部特征,同时保留光谱相关性。 LFESM 中应用了光谱注意力,以更好地保留光谱特征。此外,交互式注意单元(IAU)被提议连续耦合两个并行分支之间的互补特征。交互方式可以大幅提炼transformer分支中全局特征的局部细节,增强3-D CNN分支中局部特征的全局感知能力。
总之,这项工作的主要贡献如下:
1) 为 HSI SR 提出了一个称为 Interactformer 的并行网络。 Transformer 分支用于捕获远程依赖以获得全局特征,3-D CNN 分支用于提取局部特征,同时保留 HSI 的光谱相关性。
2)IAU 旨在与从中提取的局部和全局特征进行交互两个并行分支。
3)在transformer模块中设计了具有线性复杂度的可分离self-attention模块。解决了传统self-attention机制中二次复杂度导致的高内存问题。
4)在CNN分支中应用具有3-D卷积的光谱注意模块来保护光谱相关性并提取空间 - 光谱特征effectively.
本文的其余部分分为三个部分。
在第二节中,详细描述了提议的Interactformer。
第三节专门介绍实验和结果。在第四节中,给出了结论。
II. 方法论
本节中,所提出的网络分为四个部分:整体网络、IAU、带可分离自我注意模块的变压器和 LFESM.
A. 整体网络
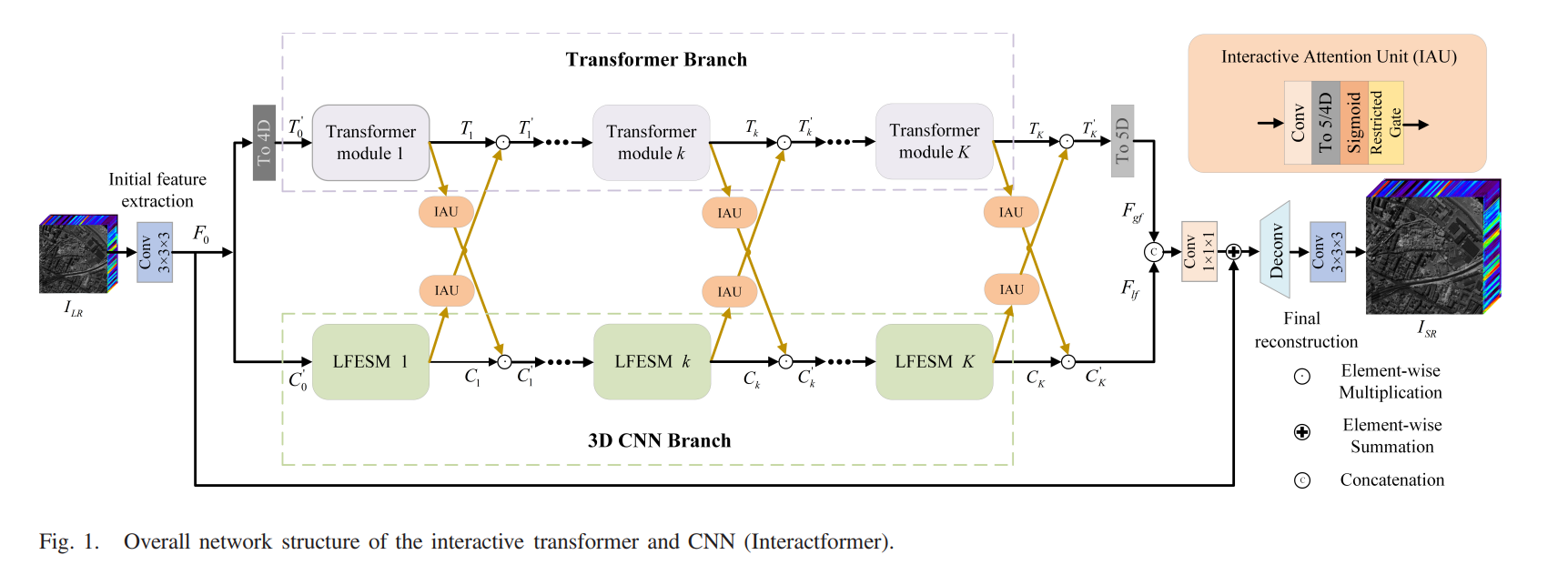
本节给出了所提出的交互者的整体网络结构。如图1所示。
建议网络主要由两个平行的网络分支组成。
• 首先,通过 3-D 卷积提取输入图像的初始特征。
• 然后,将初始特征图发送到两个并行分支以提取全局和局部特征。
特征图的长程依赖被transformer分支捕获。 3-D CNN 分支中的 LFESM 提取局部特征并保留光谱相关性。
• 此外,建议使用 IAU 与两个并行分支之间的全局和局部特征信息进行交互。
• 最后通过反卷积上采样进行重构得到SR HSI。
令 ILR∈R 1×B×(H/r)×(W/r) 和 ISR∈R 1×B×H×W 表示输入LR HSI和输出SR HSI,分别是其中H和W分别是每个band的高度和宽度,B代表band的数量,r代表比例因子,1是feature map的通道数。内核大小为 3 × 3 × 3 的 3-D 卷积用于从 ILR 中初始提取特征
接下来,F0通过freshape 4D(·)重塑为4D数据,然后发送到变压器分支。在变压器分支的末端,输出通过 freshape5D(·) 重塑为 5-D 数据。
freshape4D(·) 表示从 N×C×B×H×W 到 (N × B) × C × H × W 的双倍变换,C 是通道数,N 表示批量大小。
freshape5D(·) 表示从 (N × B) × C × H × W 到 N×C×B×H×W 的维度变换,同时通过 3-D CNN 分支提取局部特征。
两个分支包含 K transformer modules和 K LFESM。第k个变压器模块的输出Tk和第k个LFESM模块的输出Ck可由下式获得
其中 fkT(·)表示kth变压器模块的操作,fkL(·) 表示第 k 个 LFESM 的操作,Tk−1 和 Ck−1 分别表示第 k 个变压器模块和 LFESM 的输入。
由于两个分支之间存在互补特征,将变压器和3-DCNN分支提取的全局和局部特征连接起来,表示为Fg f、Fl f,后跟1×1×1卷积,可以获得具有长程依赖关系和局部信息的特征图。最终的重建可以表示如下:
其中fup(·)和fconv3×3×3(·)是反卷积层和卷积层。
损失函数用于测量重建误差。常用的损失函数包括L2损失(均方误差)和L1损失(平均绝对误差),用于测量SR图像与地面真实值之间的像素差异。因为与L2损耗相比,L1损耗不会过度惩罚大误差,并且表现出更好的收敛性能[41]。我们采用L1损耗来测量重建精度。L1 损耗如下:
其中 IGT 和 ISR 分别表示地面真实值和 SR 图像。
同时,为了保护HSI的光谱相关性,利用光谱梯度损失[22]进一步保存光谱信息。光谱梯度损失如下:
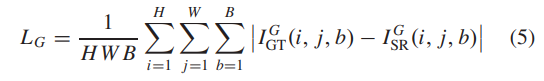
其中 I G GT 和 I G SR 表示地面实况和 SR 图像的光谱梯度。全损函数可以表示为
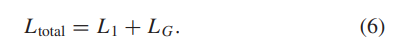
B.交互式注意力单元
在以前的方法中,局部和全局特征的交互通常被忽略。在本文中,IAU 是旨在以自适应的方式与局部和全局特征进行交互。
具体而言,如图1所示,IAU可以为全局和局部特征生成权重,以通过逐元素乘法进行交互。 3-D CNN分支中特征图的大小为N×C×B×H×W,transformer分支中特征图的大小为(N×B)×C×H×W。考虑互补性two-style features,3-D CNN分支的特征信息通过IAU传递给transformer分支。首先,1 × 1 × 1 卷积可以实现特征图的跨通道交互。然后,通过 freshape4D(·) 将特征图重塑为 (N × B) × C × H × W。为了从 3-D CNN 分支生成包含局部特征和光谱信息的权重,使用 sigmoid 函数 σ 将特征信息投影到权重。由于局部特征和全局特征之间存在一些差异,简单直接的传输方式可能会导致不良结果。为了进一步增强两个分支的交互,我们将可学习系数λ设置为限制门,可以自适应地调整从CNN分支到transformer分支的权重信息。同时,来自 transformer 的全局空间信息以类似的方式传输到 CNN 分支。不同之处在于,transformer 分支的特征图需要通过 freshape5D(·) 重塑为 N × C × B × H × W。两个分支间IAU的具体操作表示为
其中 λCT 和 λTC 是在第 k 个 LFESM 和变压器模块之后 IAU kk 的可学习系数。
C.带可分离自注意模块的变压器图。
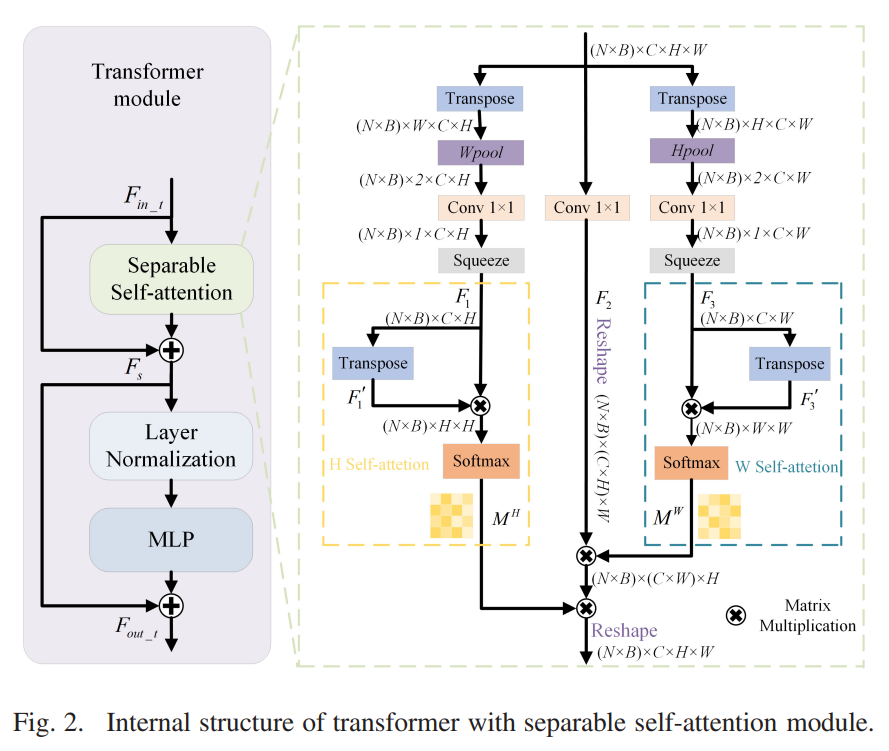
图2示出了所提出的变压器模块,该模块由可分离的自注意力模块、层归一化和MLP组成。最近的CV变压器[42],[43]使用自我注意来捕获两者之间的长期依赖关系所有令牌。自注意力可以直接捕获像素之间的长距离关系,以动态方式处理空间信息。我们在训练阶段重点学习长程依赖的捕获过程,这种动态的方式可以帮助网络在推理阶段获得长程空间依赖。然而,self-attention 的矩阵乘法会产生巨大的注意力图,这会导致与特征图大小相关的二次计算成本。不适合在低级图像处理上使用原始的自注意力模块,这是将 transformer 应用于 HSI SR 的主要问题。
为了解决这个问题,通过在 H 和 W 维度上分离地获取全局特征,设计了一个具有线性复杂度的可分离自注意力模块。它被应用于SR以获得更好的结果。
正如我们所看到的,可分离的自注意力模块分为三个路径。
首先,F1 ∈ RC×H 是通过依次执行以下操作得到的:W 和 C 维度的转置,W 维度的 Wpool(·) 池化,1×1 卷积降维,挤压操作。 Wpool(·) 可以表示为
其中最大和平均池化操作构成了 W pool(·) 。通过Wpool(·)将张量的形状从W×C×H变为2×C×H。
其次,F1’∈RH×C通过转置F1∈RC×H得到,与F1进行矩阵乘法。
然后,通过 softmax 操作获得 H 维度上的注意力图 M H ∈ RH × H。这可以具体表达如下:
其中 MH 衡量第 i 个位置对第 ij 个位置对 H 维度的影响。使用类似的操作来获得注意力图 M W ∈ RW × W 以衡量第 i 个位置对第 j 个位置在 W 维度上的影响。注意图 M H 和 M W 是相对较小维度的矩阵。
具体来说,原始self-attention的计算复杂度为(HW)2C,separable self-attention的计算复杂度为H 2 W C + W 2 H C 。由于 H , W H W ,separable self-attention 模块的复杂度是线性的。最后,将得到的attention maps依次矩阵乘以F2的高宽维度。 F2是1×1卷积线性运算得到的feature map。 separable self-attention模块可以沿着高度和宽度维度分别获取空间信息。之后,通过skip connection得到Fs,可以表示为
其中Fin_t表示transformer模块的输入,Fs是separable self-attention模块fSSA(·)的输出。所提出的变压器模块的输出 Fout_t 可按如下方式获得:
其中fLN(·)表示层归一化,fMLP(·)是沿通道维度的全连接层。
D. Local Feature Extraction With Spectral-Preserving Module
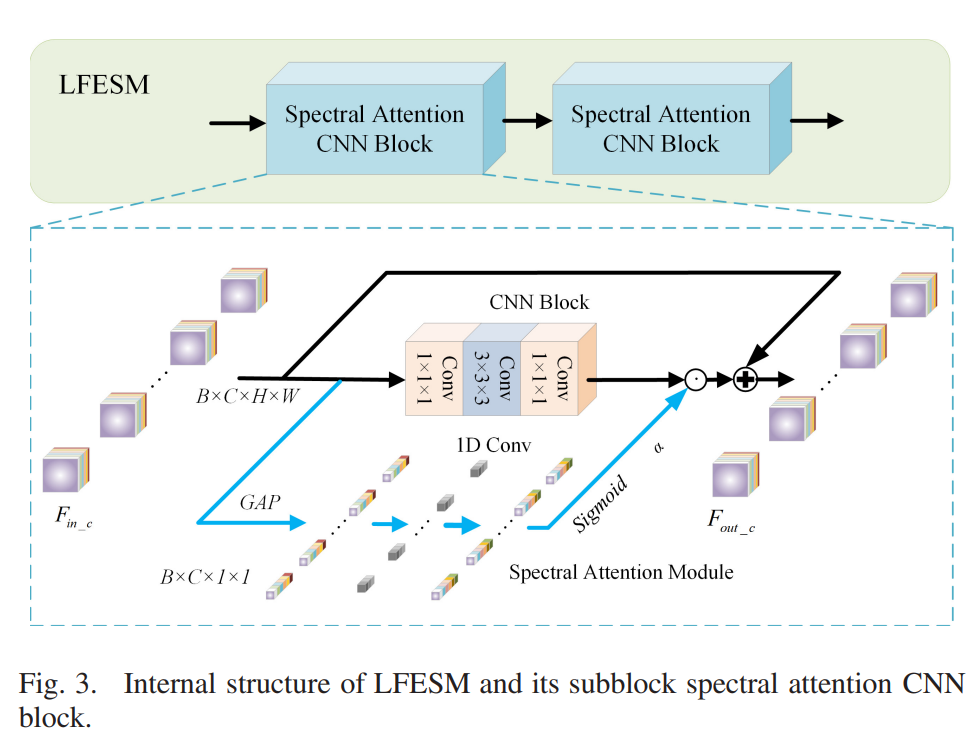
与2-D网络相比,3-D网络可以更好地保留HSI的光谱特征。
所提出网络的 3-D CNN 分支用于保留 HSI 的光谱特征并同时提取局部特征信息。为了进一步保留光谱特征,将光谱注意模块应用于 CNN 块。
LFESM 包含两个光谱注意 CNN 块,由两个 1×1×1 卷积、一个 3×3×3 卷积和一个光谱注意模块,如图3所示。1×1×1卷积用于增维和降维,3×3×3卷积用于空间-光谱特征提取。此外,全局平均池用于通过聚合跨空间维度 (H × W) 的特征图来生成谱带描述符。接下来,一维卷积实现了光谱关系的学习,以充分保留复杂的光谱相关性。特征图的不同通道中的波段被视为处理不同的光谱特征。与压缩和激励网络(SENet)[44]的全连接结构相比,通过一维卷积学习光谱关系不会降维,同时获得更好的性能和效率。高效通道注意力网络(ECANet)[45]通过一维卷积实现通道交互并获得良好的性能。
因此,我们设置大小为 1 × 3 的 1-D 卷积以保留光谱注意模块中的光谱相关性。 sigmoid 函数用于生成谱注意力权重 α。然后,α用于重新校准光谱特征。 spectral attention CNN block可以表示如下:
其中fCNN(·)是CNN block,Fin_c和Fout_c分别代表spectral attention CNN block的输入和输出.
三、实验
在本节中,进行了大量实验以评估所提出的 Interactformer 的性能。我们首先介绍三个公共高光谱遥感数据集。然后,描述了评估指标和实施细节。接下来,构建消融实验以充分证明所提出方法的有效性。最后,通过与最先进的方法的比较,验证了所提出方法的优势。
数据集
- Pavia Center 数据集 [46]:Pavia Center HSI 是在意大利帕维亚上空的一次飞行活动中由 ROSIS 传感器获取的。 Pavia Centre 的光谱波段数为 102,这是一张 1096 × 1096 像素的图像。但是,图像的某些区域不包含任何信息,因此必须丢弃。我们去除了两个噪声带并将图像划分为 70% 的训练区域 (1096 × 515 × 100) 和 30% 的测试区域 (1096 × 200 × 100)。训练数据经过水平翻转、旋转(90°、180°、270°),切割成7770个样本,大小为32×32×100。测试数据集由8张大小为128×128的图像组成× 100.
- Chikusei 数据集 [47]:Chikusei 高光谱数据集在 363 到 1018 nm 的光谱范围内有 128 个波段。场景由 2517×2335 像素组成,地面采样范围为 2.5 m。我们提取了 8 个 128 × 128 × 128 像素的非重叠区域来形成测试数据。剩余区域用作训练数据,被切割成 8160 个样本,大小为 32×32×128.
- Houston Dataset [48]:Houston 高光谱数据集由 380 至 1050 nm 光谱范围内的 144 个光谱波段组成。休斯顿数据集是一个大小为 349 × 1905 像素的图像。我们将图像分为训练区域(170×1900×144)和测试区域(170×1900×144)。然后,训练区域被切割成7470个样本,样本大小为32×32×144。测试数据集由14张大小为128×128×144的图像组成。
以上图像用作ground truth,而LR HSIs 是通过高斯下采样模拟的,具有三个比例因子,即 2、4 和 8。由于 HSIs 的巨大内存需求和硬件限制,我们没有在更大的 HSIs 上训练网络,并且训练集小图像可以减少训练时间。
B Evaluation Metrics and Implementation Details
1)评估指标:为了定性地衡量所提出的Interactformer,使用了四个评估指标来验证所提出方法在模拟和真实实验中的有效性。具体来说,平均峰值信噪比 (MPSNR) [49] 和平均结构相似度 (MSSIM) [50] 是图像质量评估的通用评估指标。前者表示ground truth与生成的SR结果之间基于MSE的相似度,而后者描述的是结构一致性。它们在所有光谱带上的平均值被用作空间的度量视觉质量。更高的 MPSNR 和 MSSIM 值意味着更好的质量。光谱角度映射器 (SAM) [51] 评估光谱保真度,SAM 的最佳值为零。在真实的HSIs实验中,测试图像是没有参考图像的原始HSI。 Q-metric [52] 不需要参考图像,用于评估 SR 性能。更高的 Q 度量值意味着更好的 SR 性能。
2)实现细节:在提出的 Interactformer 中,每个变压器模块和 LFESM 的通道数为 64。变压器模块和 LFESM 的数量设置为 4。在频谱注意 CNN 中block,feature map的通道数通过1×1×1卷积增加到128。 CNN 块的卷积层内核大小为 3×3×3,光谱注意模块的卷积层内核大小为 1×3。权重由 Kaiming 初始化 [53] 初始化。网络使用默认设置的 ADAM [54] 进行优化。初始学习率设置为 0.0005,每 30 个 epoch 减半。由于 GPU 内存的限制,批量大小设置为 16。所提出的方法使用 Pytorch 框架在 NVIDIA GTX 1080Ti GPU 上执行。
C.Ablation Study
为了验证所提方法的有效性,在比例因子为4的Pavia Center数据集上进行了一系列的消融实验。
首先,并行分支的模块数设置为2~5,对参数进行分析。 K. 表 I 给出了评估指标的结果,这表明当 K 小于 5 时,较大的 K 表现出更好的性能。更深的网络允许更好的 SR 重建。然而,当 K 设置为 5 时,评估指标开始下降。造成这种现象的主要原因是网络越深,越难训练。因此,在我们的方法中将参数 K 设置为 4。
然后,进行了一系列实验以说明可分离的自注意和光谱注意模块的优点。 GCNet [37] 是一种简化的自注意力网络,计算量更少。 Swin Transformer [39] 的跨窗口自注意力(CSA)使用局部自注意力和跨窗口交互来降低计算复杂度。 SENet [44] 对通道之间的依赖关系进行建模并重新校准通道特征。 GCnet和CSA的global context block(GCB)被用来替代separable self-attention模块来验证Interactformer中的global feature extraction能力。 SENet 的挤压和激发块 (SEB) 用于替换光谱注意模块以比较光谱保存性能。实验结果见表二。从三个评估指标的值,我们可以观察到可分离自注意力模块的性能优于 GCB。同时,separable self-attention优于CSA,限制了局部邻域的上下文聚合。与SEB相比,所提出的光谱注意模块可以显着降低重建图像的SAM值并取得良好的效果。同时,单个transformer分支、单个CNN分支、并行transformer分支、并行CNN的评价指标分支也在表二中给出。我们可以观察到他们的评估指标比 Interactformer 差。单个transformer分支缺乏局部特征提取和光谱特征保护,单个CNN分支缺乏全局特征提取,导致性能下降。并行transformer分支和并行CNN分支呈现出比Interactformer更差的评估指标值,因为全局和局部特征没有同时提取。和光谱注意力。
实验结果在表III中给出。结果表明,去除 IAU 后 MPSNR 显着降低。 CNN分支中频谱注意模块的移除导致SAM值的增加,这可以推导为频谱保护能力的降低。当同时移除 IAU 和频谱注意力模块时,评估指标值变差,网络性能下降。因此,这些组件可以有效地提高SR性能。
D 模拟 HSI SR 实验
E.真实HSI SR实验
G.计算成本
为了分析所有比较算法的计算成本,表 IX 给出了所有方法的参数数量 (Params) 和推理时间。具体来说,我们获得了比例因子为 4 的帕维亚中心数据集中所有方法的参数和推理时间。所有方法均由 Pytorch 实现,计算成本是在 GeForce GTX 1080Ti GPU 上测量的。尽可能从表 IX 可以看出,预上采样方法(即 GDRRN、3D-FCNN 和 VDSR)的推理时间更长。二维网络需要更多的通道才能获得良好的性能,从而导致大量参数(即 SwinIR 和 SSPSR)。所提出的方法可以在略微增加计算成本的情况下获得更好的性能。
结论
在本文中,Interactformer 被提出用于 HSI SR 以与局部和全局特征进行交互。在 Interactformer 中,我们利用 transformer 模块来捕获全局特征,并利用 LFESM 来提取局部特征。在transformer模块中,separable self-attention模块被设计用来解决传统self-attention机制中的二次复杂度问题。在 LFESM 中,3-D 卷积和光谱注意模块可以提取局部特征,同时更好地保留光谱特征。并行网络之间的IAU旨在融合局部和全局特征,以交互方式增强两个并行分支的互补性。三个 HSI 遥感数据集的实验结果表明,与其他 SR 方法相比,所提出的 Interactformer 实现了不同评估指标的最佳值,并获得了更好的重建图像。此外,我们方法的SR结果比其他方法获得了更高的分类精度,这显示了实际应用的潜力。在未来的工作中,我们将探索将所提出的方法扩展到其他图像恢复应用程序,例如 HSI 去噪。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









