






英特尔实验个人分享-2301210407
英特尔
在今天的讲座中,我们深入探索了深度学习模型优化技术,这对于任何想要提升AI模型在硬件上运行效率的同学来说,都是极其宝贵的知识。讲座主要围绕两大类优化技术展开:通用优化和针对大型语言模型(LLM)的特定优化。
通用优化技术
-
量化:这是一种减少模型大小和加速推理的有效手段。其中,静态量化需要预先在样本数据集上进行校准,收集张量信息,随后根据这些信息对输入和权重张量进行量化。动态量化则更加灵活,无需校准,直接在运行时按批次收集张量信息。特别是权重仅量化,在LLM领域非常流行,它保持输入不变,仅将权重压缩并打包为低比特(如INT4),常用算法有GPTQ和AWQ。
-
混合精度:利用bfloat16和float16这样的数据类型,在保证精度的同时减少内存和计算资源消耗。
-
剪枝/稀疏性:通过移除对模型预测贡献较小的权重来减小模型大小,支持多种算法,如基本幅度、梯度敏感性和模式锁定。
-
蒸馏:通过知识转移,使小型模型学习大型模型的行为,达到模型压缩的目的。
针对大型语言模型的优化
-
平滑量化(SmoothQuant):针对LLM特有的激活值异常问题,通过将异常值转移到权重上来改善量化效果,提高了量化模型的准确性。
-
FP8:介绍了一种新的数据类型,FP8,拥有两种格式(E4M3和E5M2),旨在进一步降低模型存储需求和计算成本,同时尽量保持模型性能。
实践操作
讲座还展示了如何实际操作,比如使用PyTorch API进行静态量化,以及如何利用Intel的AutoRound和WOQ算法进行优化。
通过代码示例,我们学习了如何启用SmoothQuant以及如何配置不同类型的量化方案,例如静态量化配置、GPTQ配置、AWQ配置和FP8量化配置,这些都能在诸如Hugging Face和Microsoft Olive这样的平台上应用。
思考与挑战
最后,讲座还提到了量化面临的挑战,特别是在LLM中,如何处理激活值中的极端值成为关键问题。此外,对行业趋势的思考,如FP8的发展,让我们对未来的优化方向有了前瞻性的认识。
整体而言,这次讲座不仅提供了理论基础,还通过实例让我们理解了如何将这些优化技术应用于实际项目中,对我们提升模型性能和效率大有裨益。
个人实验部分
跟随老师脚步, 我完成了本次实验, 截图如下所示:
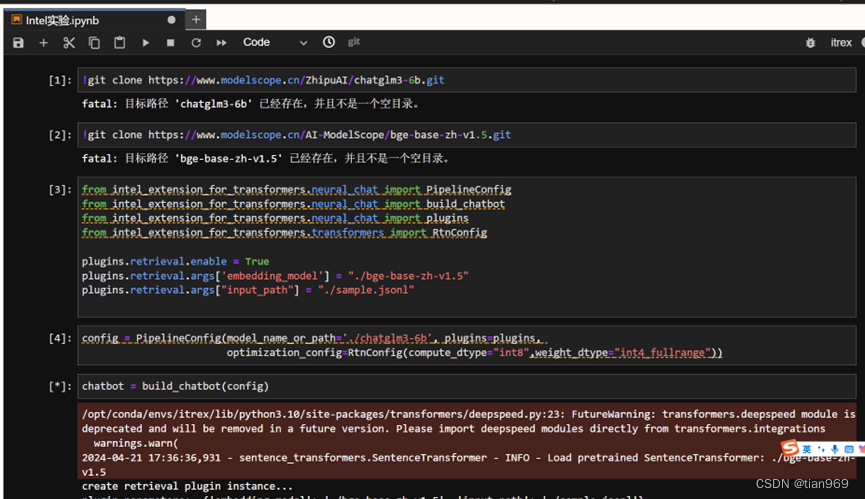
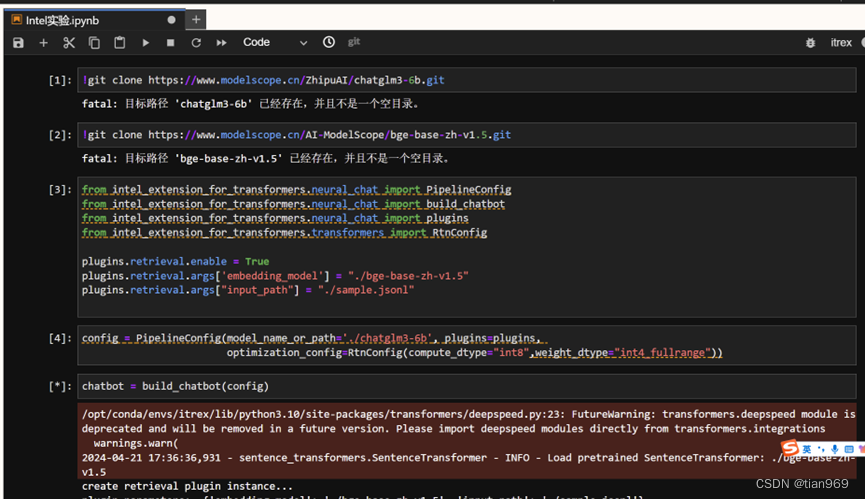
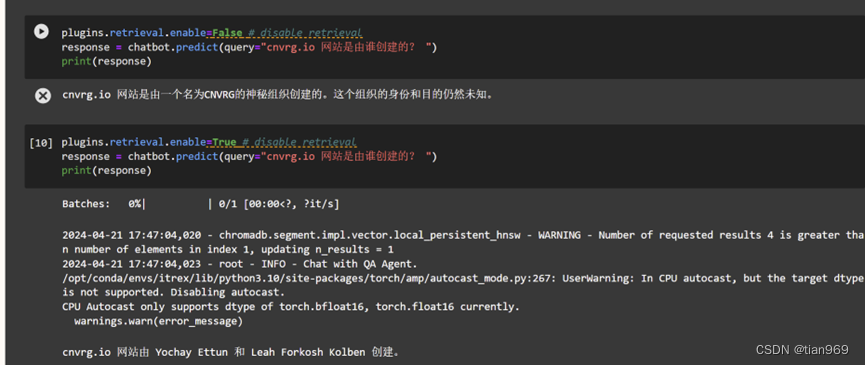
个人心得
-
量化技术是提高模型效率的核心手段,分为静态量化、动态量化以及权重仅量化(Weight-Only Quantization, WOQ),其中WOQ在大型语言模型(LLMs)领域特别受欢迎,能显著降低内存需求,例如将7B参数模型的内存占用从16GB减少到4-5GB,这对于内存有限的硬件如Intel Arc GPU尤为重要。
-
混合精度训练利用bfloat16等数据类型,在保持模型精度的同时减少计算和存储需求,bfloat16相比float16有更宽的数值范围和对超参数影响小的优势。
-
**平滑量化(SmoothQuant)**是针对LLMs激活值中的显著异常值问题提出的方法,通过将激活值的离群点转移到权重上,配合自动操作级别的平滑系数调整,有效提升了INT8量化后的模型精度。
-
Intel AutoRound和**Advanced Weight Quantization (AWQ)**等算法进一步优化了量化过程,AutoRound用于自动调整舍入策略以优化量化结果,而AWQ是提升量化准确率的一种方法,通常比其他量化技术表现更好。
-
剪枝/稀疏性和知识蒸馏也是重要的模型压缩技术,通过移除不重要权重或用小型模型学习大型模型的知识来减少模型复杂度。
-
在实现这些优化时,利用如Intel Neural Compressor和Intel Extension for Transformers等工具可以简化在PyTorch、TensorFlow、ONNX Runtime等框架上的性能优化工作流程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









