






1.RDD概述
1.1 定义
RDD(弹性分布式数据集),Spark数据集的一个基本抽象。它是跨集群节点划分的元素的集合,可以并行操作。
用户可以要求Spark将RDD保留在内存中,以使其能够在并行操作中有效地重用。
RDD可以自动从节点故障中恢复。
ARRAY VS RDD : array是针对单机而言,RDD来源于分布式服务器,比如worker1,worker2…
1.2 创建RDD的方式(以官网为例)
1.2.1 使用SparkContext创建
val data = Array(1,2,3,4,5)
val disData = sc.parallelize(data)

1.2.2 读取外部数据集
val rdd = sc.textFile("/textfile/wc.txt")

2.算子(RDD的函数或方法)
2.1 Transformation:不会触发计算,延时加载(Scala lazy)
2.1.1 textFile
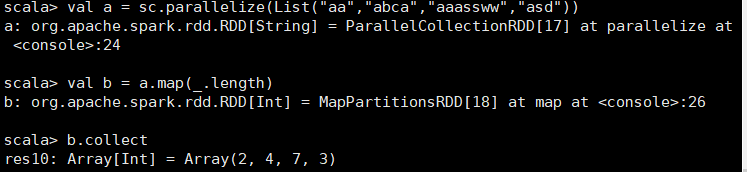
2.1.2 map(func)
val a = sc.parallelize(List("aa","abca","aaassww","asd"))
val b = a.map(_.length)
b.collect
2.1.3 flatMap
先将每个元素对应执行func函数,,然后将其扁平化
val a = sc.parallelize(1 to 10,3)
val b = a.flatMap(1 to _).collect

2.1.4 filter
过滤,选择满足条件的元素
val b = a.filter(_ % 2 == 0).collect

2.1.5 union
并集

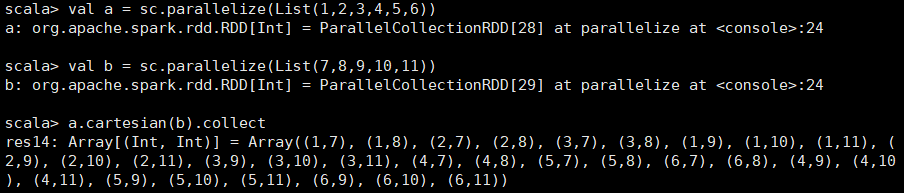
2.1.6 cartesian (笛卡儿积)
2.1.7 intersection (交集)
2.1.8 distinct
去重

2.1.9 groupBy
分组

2.1.10 mapValues

2.2 Action :会触发计算
2.2.1 collect
2.2.2 count:求个数
2.2.3 first:求第一个元素
2.2.4 take(n):求前n个元素
2.2.5 saveAsTextFile : 保存文件
2.2.6 foreach(func) : 对原来RDD的每个元素,执行func
与map的区别是,foreach没有返回值
3.Spark的高级算子
3.1 mapParatitions
mapPartitions可以认为是map的变种,它们都可以进行分区的并行处理,两者的主要区别是调用的力度不同。
map的输入函数是应用于RDD的每个元素,而mapPartitions的输入函数是应用于每个分区。
val a = sc.parallelize(1 to 10 ,3)
def mapFunc(x:Int):Int={
println("x="+x)
x*2
}
def mapFuncPart(iter:Iterator[Int]):Iterator[Int]={
println("run in partition")
var res = for(x <- iter) yield x * 2
res
}
val b = a.map(mapFunc).collect
val c = a.mapPartitions(mapFuncPart).collect

根据上图可以看出,map是针对rdd中的每个元素进行操作("x="输出10次)
mapPartitions则是对每个分区的迭代器进行操作(“run in partition” 输出3次)
在一些情况下,比如在上例中,如果进行数据库连接,mapFuncPart只需要初始化三个资源,而mapFunc需要初始化10个资源,在大数据集的情况下,mapFuncPart的开销要小的多,也便于进行批处理操作。
再比如一个RDD中有1万条数据,通过map,func会执行1万次,但是通过mapPartitions,
一个task只会执行一次func,func一次性接收所有的partition数据,性能会比较高。
但是由于mapPartitions是一次传入整个partition的,可能会导致OOM。
3.2 mapPartitionsWithIndex
mapPartitionsWithIndex也是对RDD的每个分区进行操作(带有分区号)
一次获取到一个分区,同时将分区对应的编号拿出来。
通过这个方法,可以知道每个分区有哪些内容。
val a = sc.parallelize(1 to 10 ,3)
val func = (index:Int,iter:Iterator[Int]) => iter.map(s"index:$index,res:"+_)
a.mapPartitionsWithIndex(func).collect

3.3 aggregate(聚合)
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U = withScope {
// Clone the zero value since we will also be serializing it as part of tasks
var jobResult = Utils.clone(zeroValue, sc.env.serializer.newInstance())
val cleanSeqOp = sc.clean(seqOp)
val cleanCombOp = sc.clean(combOp)
val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)
val mergeResult = (index: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)
sc.runJob(this, aggregatePartition, mergeResult)
jobResult
}
共有两次聚合:局部聚合
全局聚合
参数:zeroValue: U 初始值 (同时作用于局部操作和全局操作)
seqOp: (U, T) => U 局部操作
combOp: (U, U) => U 全局操作
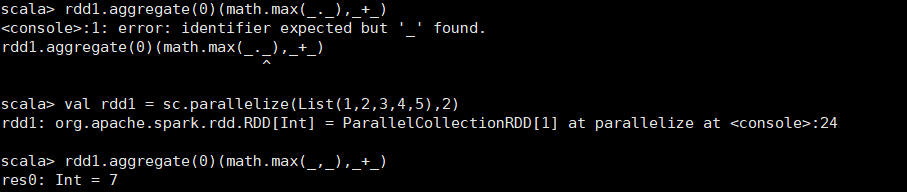
3.3.1 举例1
val rdd1 = sc.parallelize(List(1,2,3,4,5),2)
rdd1.aggregate(0)(math.max(_._),_+_)
def func1(index:Int,iter:Iterator[Int]):Iterator[String]={
| iter.toList.map(x=>"Partition ID:" + index +",value="+x).iterator
| }
rdd1.mapPartitionsWithIndex(func1).collect

解析:
rdd1.aggregate(0)(math.max(_._),_+_) 7
第一个分区最大值:2
第二个分区最大值:5
result:7
3.3.2 举例2
rdd1.aggregate(0)(_+_,_+_)

3.3.3 举例3
rdd1.aggregate(10)(_+_,_+_)

解析:分区1:10+1+2
分区2:10+3+4+5
result: 10+13+22(前文提到的初始值会同时作用于局部和全局,相当于+30)
3.3.4 举例4
rdd1.aggregate(10)(math.max(_,_),_+_)

解析:分区1:10
分区2:10
result:10+10+10
3.3.5 举例5
val rdd2 = sc.parallelize(List("a","b","c","d","e","f"),2)
def func2(index:Int,it:Iterator[String]):Iterator[String]={
| it.toList.map(x => "Partition ID:" + index + ",value = " + x).iterator
| }
rdd2.aggregate("#")(_+_,_+_)

result:##abc#def

多执行几次,会发现有不同的结果,是因为有两个分区,两个task,执行快的task在前面显示。
3.4 aggregateByKey
针对的是<key,value>数据类型,先对局部进行操作,再对全局进行操作
和aggregate类似,都是聚合,aggregateByKey是根据key进行聚合
val pairRDD = sc.parallelize(List(("cat",4),("dog",2),("snake",3),("elephant",5),("dog",3),("elephant",6),("snake",8)),2)
def func3(index:Int,it:Iterator[(String,Int)]):Iterator[String] = {
| it.toList.map(x=>"Partition ID:" + index +",value="+x).iterator
| }
pairRDD.mapPartitionsWithIndex(func3).collect

pairRDD.reduceByKey(_+_).collect
pairRDD.aggregateByKey(0)(_+_,_+_).collect
pairRDD.aggregateByKey(100)(_+_,_+_).collect

解析:根据上文的分区信息
Array[String] = Array(
Partition ID:0,value=(cat,4),
Partition ID:0,value=(dog,2),
Partition ID:0,value=(snake,3),
Partition ID:1,value=(elephant,5),
Partition ID:1,value=(dog,3),
Partition ID:1,value=(elephant,6),
Partition ID:1,value=(snake,8))
先局部聚合,再全局聚合
分区0 分区1
cat: (100 + 4) = 104
dog: (100 + 2)+ (100 + 3)= 205
snake:(100 + 3)+ (100 + 8)= 211
elephant: (100 + 5 + 6) = 111
4.RDD高级方法
4.1 collectAsMap
val rdd = sc.parallelize(List(("a",1),("b",2)))
rdd.collect
rdd.collectAsMap

val rdd = sc.parallelize(List(("a",1),("b",2),("b",12),("a",21)))
rdd.collectAsMap

从结果可以看出,如果RDD中同一个key存在多个value,后面的value将会把前面的value覆盖,最终得到的结果就是唯一的key对应一个value。
4.2 countByKey
统计相同key出现的次数

4.3 countByValue
val rdd = sc.parallelize(List(("a",1),("b",2),("b",12),("b",22),("c",11)))
rdd.countByValue

val rdd = sc.parallelize(List(("a",1),("a",1),("b",2),("b",12),("b",12),("b",22),("c",11),("c",11)))
rdd.countByValue

可以看出countByValue是统计相同的key+value出现的次数

4.3 flatMapValues
val rdd1 = sc.parallelize(List(("a","1 2"),("b","3 4")))
rdd1.flatMapValues(_.split(" ")).collect
















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









