






语言模型
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为 T 的词的序列 w1,w2,…,wT ,语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
P(w1,w2,…,wT).
假设序列 w1,w2,…,wT 中的每个词是依次生成的,我们有
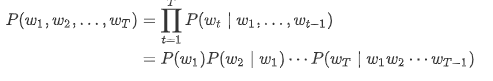
例如,一段含有4个词的文本序列的概率
P(w1,w2,w3,w4)=P(w1)P(w2∣w1)P(w3∣w1,w2)P(w4∣w1,w2,w3).
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如, w1 的概率可以计算为:
P^(w1)=n(w1)n
其中 n(w1) 为语料库中以 w1 作为第一个词的文本的数量, n 为语料库中文本的总数量。
类似的,给定 w1 情况下, w2 的条件概率可以计算为:
P^(w2∣w1)=n(w1,w2)n(w1)
其中 n(w1,w2) 为语料库中以 w1 作为第一个词, w2 作为第二个词的文本的数量。
n元语法
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。 n 元语法通过马尔可夫假设简化模型,马尔科夫假设是指一个词的出现只与前面 n 个词相关,即 n 阶马尔可夫链(Markov chain of order n ),如果 n=1 ,那么有 P(w3∣w1,w2)=P(w3∣w2) 。基于 n−1 阶马尔可夫链,我们可以将语言模型改写为
P(w1,w2,…,wT)=∏t=1TP(wt∣wt−(n−1),…,wt−1).
以上也叫 n 元语法( n -grams),它是基于 n−1 阶马尔可夫链的概率语言模型。例如,当 n=2 时,含有4个词的文本序列的概率就可以改写为:
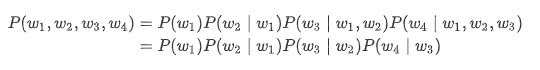
当 n 分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。例如,长度为4的序列 w1,w2,w3,w4 在一元语法、二元语法和三元语法中的概率分别为
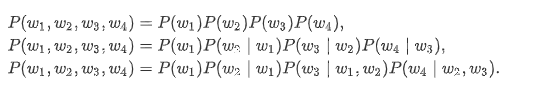
当 n 较小时, n 元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当 n 较大时, n 元语法需要计算并存储大量的词频和多词相邻频率。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









