






 本文介绍了如何使用Python脚本获取B站视频时长,统计视频总时长,以及计算不同观看速度下的时间节省情况。通过发送请求获取网页内容,解析正则表达式提取时长,然后进行统计分析,帮助用户更好地安排观看时间和选择合适的播放速度。
本文介绍了如何使用Python脚本获取B站视频时长,统计视频总时长,以及计算不同观看速度下的时间节省情况。通过发送请求获取网页内容,解析正则表达式提取时长,然后进行统计分析,帮助用户更好地安排观看时间和选择合适的播放速度。
在B站上,有许多吸引人的视频系列,但你是否好奇这些系列的总时长是多少?如果你想了解视频的时长并计算在不同观看速度下的时间节省情况,那么这篇文章就是为你准备的!本文将详细介绍如何使用Python脚本来分析B站视频的时长和观看速度,帮助你更好地安排观看时间并选择适合自己的观看速度。
可视化展示效果:
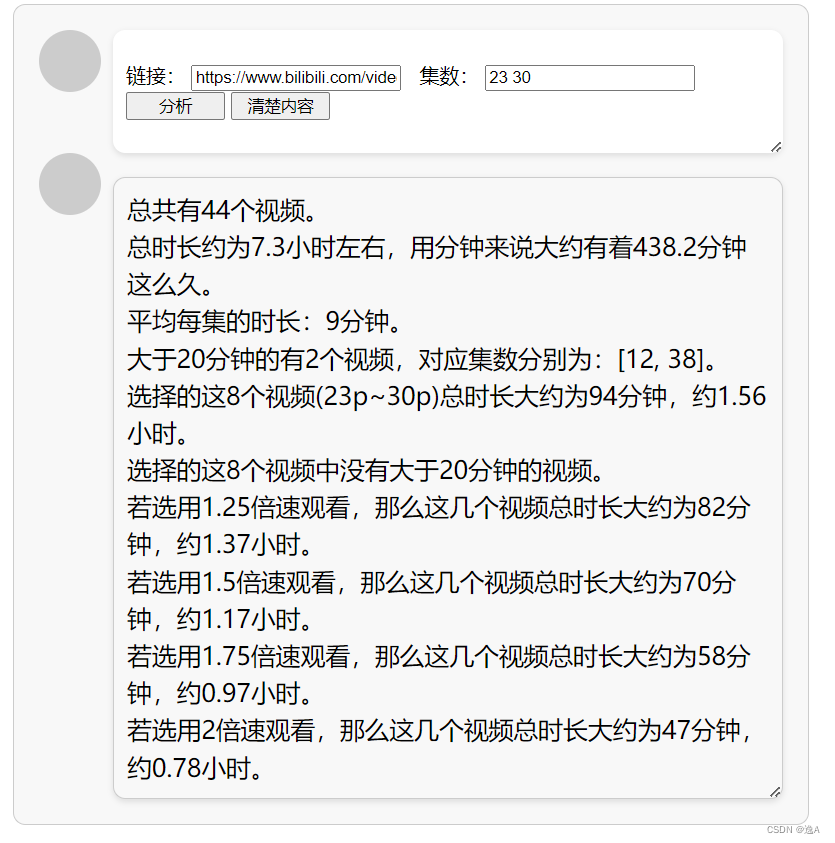
或者说自己在看些课程的时候,想要统计分析一下时长,来做一个安排,这个脚本或许可以满足你,完整代码在文末
第一步:发送请求获取视频网页内容
首先,我们需要使用Python中的requests库发送GET请求,以获取B站视频网页的内容。通过指定视频的网址,我们可以获取到视频的相关信息,包括时长等。
第二步:解析网页内容提取视频时长信息
获得网页内容后,我们需要对其进行解析。在这里,我们使用正则表达式来提取视频的时长信息。通过匹配特定的模式,我们可以成功地从网页内容中抓取视频的时长数据。
第三步:统计视频总时长和每集时长
在获取到视频的时长信息后,我们可以对这些数据进行统计和计算。我们可以计算视频系列的总时长,以及每集的平均时长。这些数据能够帮助我们更好地了解视频的长度,并且为观看时间的安排提供参考。
第四步:计算不同观看速度下的时间节省情况
接下来,我们将根据选择的视频段的总时长,计算在不同观看速度下的时长情况。通过设定不同的倍速,我们可以得出观看视频所需的时间。这样,你可以比较不同倍速观看的时间节省情况,并选择适合自己的观看速度。
第五步:输出统计结果并进行分析
最后,我们将输出统计结果,并进行详细的分析。我们将展示视频的总时长、平均每集时长以及选择的视频段的总时长。此外,我们还会提供不同倍速观看下的时长数据,让你能够更好地了解时间的变化和节省情况。
代码:
以下为编码形式的分析,本文开头的可视化分析为django方式,若有要的多的话,会出一期
import re
import requests
url = '' # 视频网址
resp = requests.get(url)
resp.encoding = 'utf-8'
z1 = re.compile(r'"duration":(?P<time>.*?),"vid"', re.S)
# 观察爬取到的数据,发现需要解译为utf-8
nr = resp.content.decode('utf-8')
result = z1.finditer(nr)
COUNT = 0 # 视频总个数
n_count = 0 # 某些个数
n2_count = 0
o_count = 0
a = 0 # 总秒数
o = 0 # 特殊秒数(现为选择的视频的秒数)
choice_start = 2 # 第几个视频开始(目前只支持从第二个开始)
choice_end = 73 # 第几个视频结束
amount = [] # 存放爬取到的数据
info = [] # 信息列表
info2 = []
# 每一个视频的秒数
for i in result:
amount.append(i.group('time'))
# 第一个下标位置的数据爬取的有点毛病,所以直接去掉
for i, j in enumerate(amount[1:]):
# 获取总视频个数
COUNT += 1
# 获取大于20分钟的视频个数
if int(j) >= 1200:
n_count += 1
info.append(COUNT + 1) # 大于20分钟视频对应的集数
# 指定视频大于20分钟的视频集数
if choice_start <= COUNT + 1 <= choice_end:
if int(j) >= 1200:
n2_count += 1
info2.append(COUNT + 1)
# 从第几个视频开始
if i == choice_start:
index = i - 1
for x in range((choice_end - choice_start) + 1):
o += int(amount[index]) # 自开始至结束的下标
index += 1
# 获取总秒数
a += int(j)
# 全部视频总时长(单位:分钟/小时/天)
Min = a / 60
hour = Min / 60
day = hour / 24
print('总共有' + str(COUNT + 1) + '个')
if hour < 24:
print("总时长约为%.1f小时左右,用分钟来说大约有着%.1f分钟这么久" % (hour, Min))
else:
print("总时长约为%.1f天的样子,也就是%.1f小时左右,用分钟来说大约有着%.1f分钟这么久" % (day, hour, Min))
# 平均每集的时长
print('平均每集的时长:' + str(Min // COUNT) + '分钟')
print('大于20分钟的有' + str(n_count) + '个,对应集数分别为:')
print(info)
print('选择的这' + str((choice_end - choice_start) + 1) + "个视频(" + str(choice_start) + "p~" + str(
choice_end) + 'p)总时长大约为%.2f分钟,约%.2f小时' % (
o // 60, (o // 60) / 60))
print('选择的这' + str((choice_end - choice_start) + 1) + '个视频其中大于20分钟的有' + str(n2_count) + '个,对应视频集数分别为:')
print(info2)
sp = ((o // 60) // 2)
spe = sp * 0.25
spe2 = sp * 0.5
spe3 = sp * 0.75
spe4 = sp
asp = sp + spe # 1.75倍速时长
asp2 = sp + spe2 # 1.5倍时长
asp3 = sp + spe3 # 1.25
asp4 = sp # 2
print('若选用1.25倍速观看,那么这几个视频总时长大约为%.2f分钟,约%.2f小时' % (asp3, asp3 / 60))
print('若选用1.5倍速观看,那么这几个视频总时长大约为%.2f分钟,约%.2f小时' % (asp2, asp2 / 60))
print('若选用1.75倍速观看,那么这几个视频总时长大约为%.2f分钟,约%.2f小时' % (asp, asp / 60))
print('若选用2倍速观看,那么这几个视频总时长大约为%.2f分钟,约%.2f小时' % (asp4, asp4 / 60))



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











