







写在前面:
本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。
一、介绍
字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序;在内存中,数据是以字节(8bit)存储的,当存储 16bit或者 32bit时,就面临着大端 (Big-Endian)存储, 还是小端 (Little-Endian) 存储的问题。
二、由来
先来讲一个故事:从前,有一个国王的儿子,在吃鸡蛋的时候,被蛋壳割破了手指;之所以发生这种情况是因为这个国家有一个传统,那就是在吃鸡蛋前从鸡蛋的较大一端开始打破。因为这次事件,国王非常焦虑,决定禁止所有臣民在鸡蛋较大的一端敲蛋;但是该政权的反对者躲了起来,他们想要保持传统,继续从较大的一边打开鸡蛋;为了这一区区争端,导致了小人国的内战,甚至殃及邻国,于是此举也使得这两个岛屿爆发了一场关于鸡蛋的血腥战争… ——《格列佛游记》
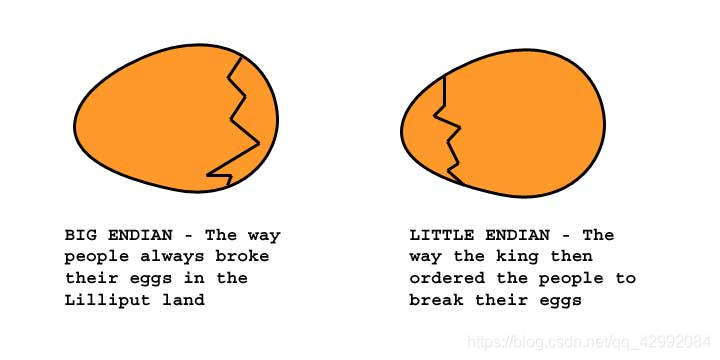
当然了,实际上并不是这样的,其实是因为 IBM、Intel等大公司不愿合作,自搞自的,而且当时也没有发布固定的标准,所以就一直沿用,才导致有大小端之分;说到底还是历史遗留问题。
然后就牵涉出两大 CPU派系:
- Motorola 6800,PowerPC 970,SPARC(除V9外)等处理器采用 Big Endian方式存储数据
- x86系列,VAX,PDP-11等处理器采用 Little Endian方式存储数据
因此,字节序只和处理器架构有关
三、大端序和小端序
鸡蛋有两个末端,一个较窄的末端(小端)和一个较宽的末端(大端)

1、大端(big-endian)
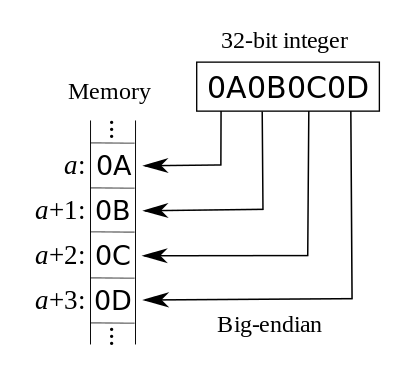
大端存储:高字节存储在低地址中,即高位先存
- 数据以 8bit为单位:
| 地址增长方向 → | |||||
|---|---|---|---|---|---|
... | 0x0A | 0x0B | 0x0C | 0x0D | ... |
示例中,最高位字节是 0x0A 存储在最低的内存地址处。下一个字节 0x0B存在后面的地址处。正类似于十六进制字节从左到右的阅读顺序。
- 数据以 16bit为单位:
| 地址增长方向 → | |||
|---|---|---|---|
... | 0x0A0B | 0x0C0D | ... |
最高的16bit单元 0x0A0B存储在低位。
- 32bit排列图示:
2、小端(little-endian)
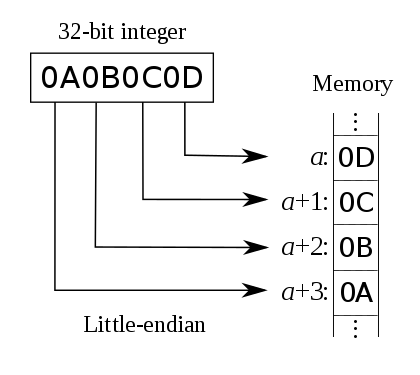
小端存储:低字节存储在低地址中,即低位先存
- 数据以 8bit为单位:
| 地址增长方向 → | |||||
|---|---|---|---|---|---|
... | 0x0D | 0x0C | 0x0B | 0x0A | ... |
最低位字节是 0x0D 存储在最低的内存地址处。后面字节依次存在后面的地址处。
- 数据以 16bit为单位:
| 地址增长方向 → | |||
|---|---|---|---|
... | 0x0C0D | 0x0A0B | ... |
最低的16bit单元 0x0C0D存储在低位。
- 更改地址的增长方向:
当更改地址的增长方向,使之由右至左时,表格更具有可阅读性。
| ← 地址增长方向 | |||||
|---|---|---|---|---|---|
... | 0x0A | 0x0B | 0x0C | 0x0D | ... |
最低有效位(LSB)是 0x0D 存储在最低的内存地址处。后面字节依次存在后面的地址处。
| ← 地址增长方向 | |||
|---|---|---|---|
... | 0x0A0B | 0x0C0D | ... |
最低的16bit单元 0x0C0D存储在低位。
- 32bit排列图示:
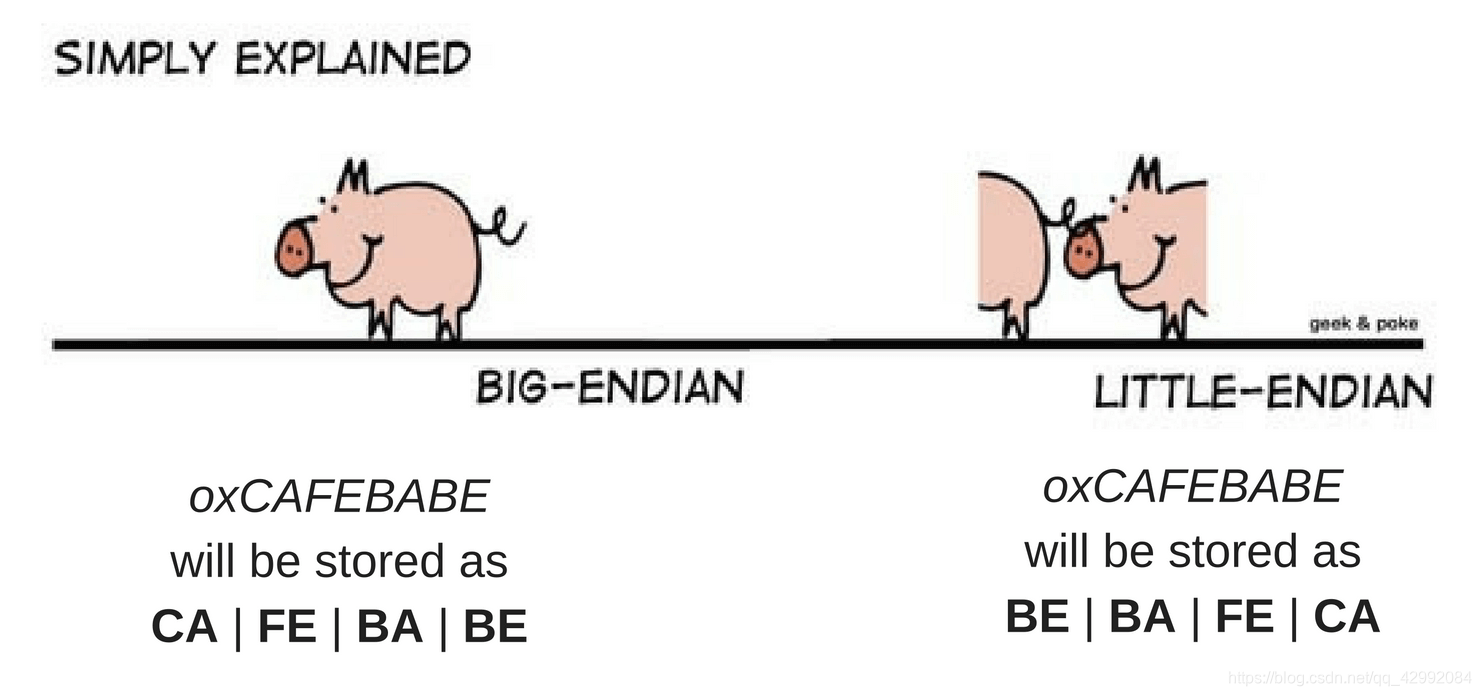
若是你还理解不了或者记不住他们所对应的关系,可以看下图:
四、为什么要注意字节序
如果你写的程序只在单机环境下面运行,而不需要与别人交互,那么你完全可以忽略字节序的存在;若是存在交互,那么就得注意了
eg:
1、在 ARM内核的 stm32f4xx中:

2、在 C8051内核的 51单片机里:

根据上面所说的,因为这两款单片机的字节序(也就是他们存储的方式)不一样,若是实现通讯交互,那么,他们彼此得到的数据将会出现颠倒现象;试想,如果 stm32f4xx单片机将变量 a = 0x12345678 的首地址传递给了 51单片机,由于 51单片机采取 Big Endian 方式存储数据,若是不做处理,那么很自然的它会将你的数据翻译为 0x78563412。显然,问题就出现了!!!
五、字节序的判断
/*
原理:
联合体 union的存放顺序是所有成员都从低地址
开始存放,而且所有成员共享存储空间
*/
void Endianness(void)
{
union temp
{
short int a;
char b;
}temp;
temp.a = 0x1234;
if( temp.b == 0x12 )//低字节存的是数据的高字节数据
{
printf("big-endian\n");//是大端模式
}
else
{
printf("little-endian\n");//是小端模式
}
}
六、位序(一般用于描述串行设备的传输顺序)
小端序(先传低位)的串行协议
- RS-232
- RS-422
- RS-485
- USB
- 以太网(虽然高字节先传,但每一字节内低位先传)
大端序(先传高位)的串行协议
- I2C协议
- SPI协议
- 摩尔斯电码
七、大小端转换
#define ReverseBytes_uint16(A) ((A & 0x00FFU) << 8 | (A & 0xFF00U) >> 8)
#define ReverseBytes_uint32(A) (A & 0x000000FFU) << 24 | (A & 0x0000FF00U) << 8 \
| (A & 0x00FF0000U) >> 8 | (A & 0xFF000000U) >> 24)
八、例子实验
猜一下以下程序输出什么:
// 假设硬件平台是intel x86(little endian)
typedef unsigned int uint32_t;
#define UC(b) (((int)b)&0xff) //byte转换为无符号int型
void inet_ntoa(uint32_t in){
char b[18];
register char *p;
p = (char *)∈
sprintf(b, "%d.%d.%d.%d\n", UC(p[0]), UC(p[1]), UC(p[2]), UC(p[3]));
printf(b);
}
int main(void){
inet_ntoa(0x12345678);
inet_ntoa(0x87654321);
return 0;
}
先来看以下的函数:
int main(void){
int a = 0x12345678;
char *p = (char *)&a;
char str[20];
sprintf(str,"%d.%d.%d.%d\n", p[0], p[1], p[2], p[3]);
printf(str);
return 0;
}
按照小字节序的规则,变量a在计算机中存储方式为:
| 高地址方向 | 0x12 | 0x34 | 0x56 | 0x78 | 低地址方向 |
| p[3] | p[2] | p[1] | p[0] |
注意,p并不是指向 0x12345678的开头 0x12,而是指向 0x78。p[0]到 p[1]的操作是 &p[0]+1,因此 p[1]地址比 p[0]地址大。输出结果为 120.86.52.18。
反过来的话,令 int a = 0x87654321,则输出结果为 33.67.101.-121。
为什么有负值呢?因为系统默认的 char是有符号的,本来是 0x87也就是 135,大于 127因此就减去 256得到 -121。
那么,最后结果为:120.86.52.18和 33.67.101.135
九、结尾
参考:
https://zh.wikipedia.org/wiki/%E5%AD%97%E8%8A%82%E5%BA%8F
https://www.errorediridondanzaciclico.com/Endianness.html
https://blog.erratasec.com/2016/11/how-to-teach-endian.html#.XnITCyIzapo


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









