






一、内存结构
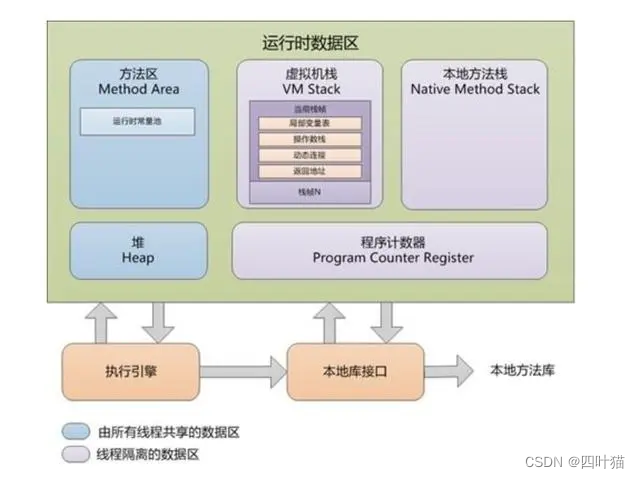
1.程序计数器
-
概念:
记住下一条jvm指令的执行地址(通过寄存器实现)。
JAVA的执行流程是这样的:JAVA语言首先被编译为字节码(.class)语言,字节码不能被计算机识别,所以还会由JVM中的解释器解释为机器码语言,最后交给计算机。
程序计数器在这个过程中,起到了“计数”的功能。解释器解释了第一行之后,会找计数器确认,下一个解释的是第二行还是第三行。 -
特点:
a.因为负责执行的执行顺序,所以程序计数器是线程私有的,这一点很好理解,因为线程是异步的,如果程序计数器不是私有的,那也不可能异步吧。
b.不存在内存溢出。
2.虚拟机栈
- 什么是栈?
栈是一种数据结构,好比手枪弹夹,子弹被一颗颗压入,开枪时最先射出的是最后压入的子弹,这就是栈的特性:先进后出。
在JVM中,虚拟机栈是线程运行需要的内存空间,与程序计数器相同,虚拟机栈也是线程私有的个人空间。 - 栈帧:每个方法运行时需要的内存。
一个方法独占一个栈帧,一个栈由多个栈帧组成,当然栈帧不是栈,只是栈内的元素。 - 活动栈帧
每个线程只能有一个活动栈帧,对应着正在执行的那个方法,也就是最顶部的栈帧(方法)。 - 问题
1.垃圾回收会不会回收栈内存?答案是否定的,因为出栈时会自动释放。
2.如何指定栈内存?使用Xss来指定,例如Xss1024kb。
3.方法内的局部变量是否是线程安全的?当然是,因为就算其他线程调用这个方法,也会在自己的栈里生成,而不是操作这个栈(当然前提是变量没有return出去)。 - 栈内存溢出(StackOverflowError)
情况一:栈帧过多(例如一直递归)
情况二:栈帧过大(操作的数据太多太大) - 线程运行诊断
可以使用top判断哪个进程占用资源过多,然后再用ps命令定位进程中的哪个线程出了问题(ps H -eo pid,tid,%cpu | grep 进程id)。
如果想要定位到具体哪一个类哪一行代码,可以使用jstack 进程id命令(不过这个命令显示的线程id是16进制的,需要换算一下)。
3.本地方法栈
在JAVA中一些方法是用了c/c++编写的底层函数或接口,分配给这些方法的虚拟机栈就叫做本地方法栈。
4.堆
-
什么是堆?
堆存放的是对象,通过new关键字创建的对象都存放在堆中。
-
特点:1.线程共享,2.有垃圾回收机制(虽然有GC,不过如果一个对象一直在使用,但是又不断膨胀直至超过堆内存限制的话,还是会内存溢出OutOfMememoryError的,可以使用Xmx指定大小)。
5.方法区
-
什么是方法区:
所有线程共享,存放跟类相关的数据,比如构造器、成员方法、成员变量等。1.6占用堆的空间(永久代),1.8后直接占用操作系统的内存(元空间)。
-
特点:1.因为1.8以后直接使用了操作系统的内存,所以很难看到方法区内存溢出(可以指定元空间大小XX:MaxMetaSpaceSize=8m)。
-
常量池
常量池就是一张表(HashTable),虚拟机指令根据这张表找到要执行的类名/方法名/参数类型/字面量等信息。
-
运行时常量池
class包含了类基本信息、常量池、类方法定义。当类被加载时,它的常量池信息就会被放入运行时常量池,并将里面的符号地址变为真正的内存地址。
-
StringTable(字符串常量池)
特性:1.常量池中的字符串仅是符号,第一次用到时才变为对象;2.利用串池的机制,来避免重复创建字符串对象;3.字符串变量拼接的原理是StringBuild(1.8);4.字符串常量拼接的原理是编译器优化;5.可以使用intern方法,主动将串池中还没有的字符串对象放入串池。
StringTable1.6是在永久代中,1.7、1.8在堆中。
调优:如果系统中字符串常量很多,可以调整-XX:StringTableSize(捅个数)的大小,理论上大一些的话效率会高一点。
-
直接内存
概念:操作系统使用的内存。
特性:常见于NIO操作时用于数据缓冲区;分配回收成本较高,但读写性能高;不受JVM内存回收管理。
分配和回收原理:直接内存使用unsafe对象完成分配与回收,并且回收需要调用freeMemory方法;ByteBuffer的底层使用了Cleaner(虚引用)来监测ByteBuffer对象,一旦对象被垃圾回收,那么就会通过Cleaner的clear方法调用freeMemory来释放内存。
二、垃圾回收
1.如何判断对象可以回收
-
(1)引用计数法(Python):如果有引用指向A对象,那么A对象就不会被垃圾回收,但是如果A引用指向B,B引用指向A呢(循环引用)?这不就产生垃圾了。
-
(2)可达性分析算法(JAVA):GC在垃圾回收时,扫描堆中的类,将绝对不可能当成垃圾回收的对象定义为根对象,如果有对象被根对象引用,那这个对象就不被回收,反之就可以回收。
-
(3)四种引用
-
1.强引用:对象和引用有直接的关系就属于强引用,有强引用基本不会被垃圾回收。
-
2.软引用:使用SoftReference作为引用就是软引用,在内存不足时软引用对象会被回收。
-
3.弱引用:使用WeakReference作为引用就是弱引用,垃圾回收时通常会把弱引用回收掉。
-
4.虚引用:任何时候都有可能被回收。
-
5.终结器引用。
注:使用方法,可以继承WekReference,或者直接new WekReference(对象),通过get方法获取。
-
2.垃圾回收算法
- 1.标记清除:先标记再清除,但是清除并不会在内存中删除对象,只是将地址记录下来进行再分配,所以会使内存不连续,造成内存碎片化。
- 2.标记整理:标记后会进行整理,避免了内存碎片,但是效率相对较低。
- 3.复制:划分两块区域,From和To,把From中未被标记的对象复制到To中,再交换From和To。也不会产生碎片,但是会占用双倍空间。
3.分代垃圾回收
-
1.新生代:存放生存时间较短的对象
新生代又划分为伊甸园、幸存区From、幸存区To三块。对象一般诞生在伊甸园,当伊甸园满了以后,会触发第一次新生代垃圾回收(MinorGC):GC通过可达性分析算法在伊甸园中标记非垃圾的对象,标记后使用复制算法,将对象复制到幸存区To中(寿命+1),幸存区To再和幸存存From交换位置(此时伊甸园中的对象被回收掉)。
如果伊甸园中再次满仓,会触发第二次新生代垃圾回收,同样进行标记,不被回收的放入To中,然后再交换To和From。
如果多次新生代垃圾回收后,某个对象都没有被回收掉,那它就会晋升到老年代。如果出现老年代也满仓的情况,并且MinorGC无法清理出可以用的内存,就会触发FullGC,清理新生代和老年代的对象。
*GC会触发stop the world,暂停其他用户线程,垃圾回收后再恢复。这是为了避免内存地址的改变造成线程混乱。
*如果有大对象已经超出了新生代的容纳极限,那就会直接放入老年代,如果老年代也放不下呢?那就会OOM。
-
2.老年代:存放长时间存活的对象
-
3.相关VM参数
1.堆初始大小:-Xms
2.堆最大大小:-Xmx或XX:MaxHeapSize=size
3.新生代大小:-Xmn或XX:NewSize=size + XX:MaxNewSize=size
4.幸存区比例(动态):-XX:InitialSurvivorRatio=ratio和-XX:+UseAdaptiveSizePolicy
5.幸存区比例:-XX:SurvivorRatio=ratio
6.晋升阈值:-XX:MaxTenuringThreshold=threshold
7.晋升详情:-XX:+PrintTenuringDistribution
8.GC详情:-XX:+PrintGCDetails -verbose:gc
9.FullGC前MionrGC:-XX:+ScavengeBeforeFullGC
4.垃圾回收器
-
1.Serial(串行):单线程,新生代采用标记复制,老年代采用标记整理,有长时间的STW,适合堆内存较小、个人电脑。
-
2.ParNew:Serial的多线程版本。
-
3.Parallel(1.8默认):多线程,着重关注CPU吞吐量,尽可能保证单位时间总STW时间最短。
-
3.CMS(ConcurrentMarkSweep):响应时间优先,多线程,使用标记清除算法,尽可能保证单词STW最短,第一次实现了垃圾回收线程和用户线程基本上同时工作。
运行过程:
a.初始标记:暂停其他线程,并记录直接与根对象相连的对象,速度很快。
b.并发标记:同时开启GC和用户线程,记录各种与根对象有关的对象,但是由于用户线程有可能改变引用,所以并不完全。
c.重新标记:暂停其他线程,查缺补漏。
d.并发清除:开启用户线程,同时GC开始回收垃圾。
-
4.Garbage first:JDK7官方支持,JDK9默认,面向服务器,同时注重吞吐量、低延迟,整体是标记整理算法,两个区域之间是复制算法。
G1垃圾回收阶段:YoungCollection,新生代回收→YoungCollection+ConcurrentMark,新生代回收+并发标记→MixedCollection,新生代+老年代回收。
因为切分区域的原因,从整体上看,G1用的是标记整理,从局部来看,用的是标记复制。
- 1.remark:G1将对象分为黑白灰三种,黑色是有引用,灰色是正在处理中(最终可能变成黑色、白色),白色是没有引用,最后会被回收。为了防止最后有改变,G1会将白色对象放入一个队列中,最后进行一次判断后再进行垃圾回收,这就是remark。
5.垃圾回收调优
-
1.最好的GC是不GC
如果数据量太大,考虑使用软引用、弱引用、分批次处理,甚至使用第三方中间件来实现。避免GC甚至是OOM。
三.类加载机制
- 1.类文件结构
- 2.字节码指令
- 3.编译期处理
- 4.类加载机制
- 5.类加载器
- 6.运行期优化















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









