










注:Kriging+任意多目标优化算法+Topsis我都可以现做
懒人救星版:
1.任意多输入多输出都可以用(采用三套数据集)
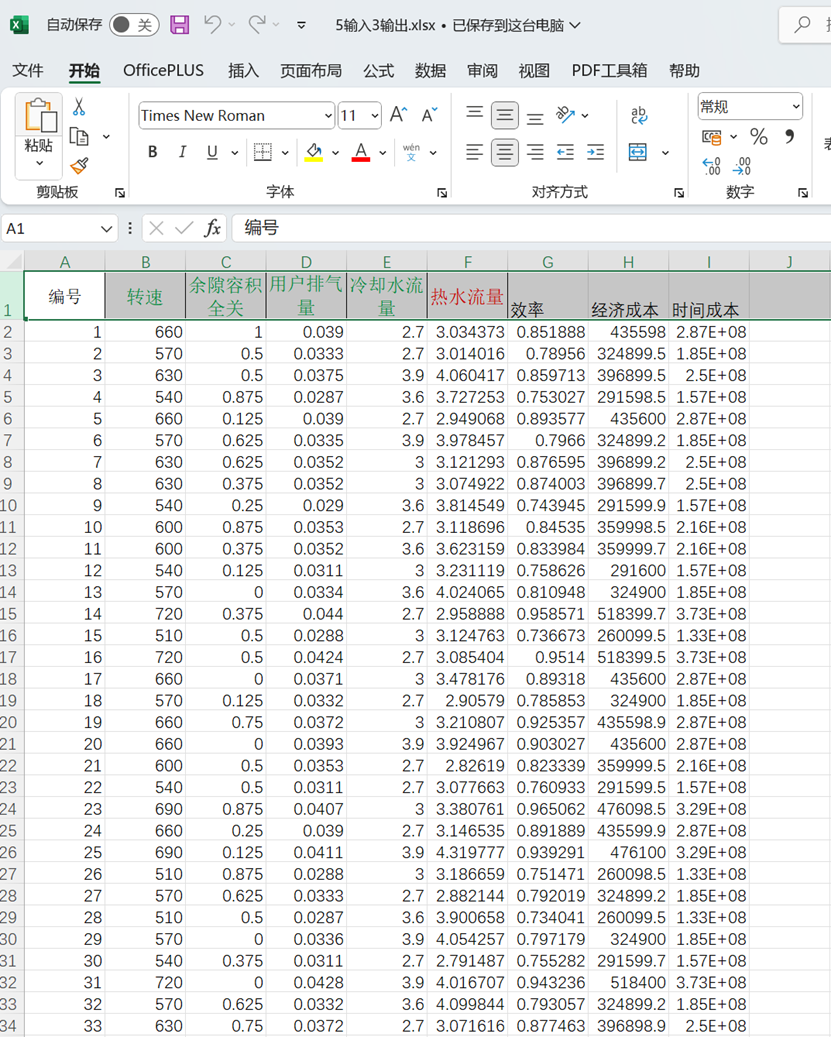
4输入2输出.xlsx 4输入3输出.xlsx 5输入3输出.xlsx
2.加入数据拟合散点图
数据特点:(多元化的数据)
包含0-1数据、大于1的数据和极大的数据(10的8次方)
每个代码压缩文件包改动代码处不超过3处
如下图代码中:(改动点总计3处代码即可运行)
Kriging_NSGA2克里金做代理预测模型目标遗传NSGA2的帕累托前沿图:
三目标为例图(支持任意多目标,这里只展示二目标和三目标)
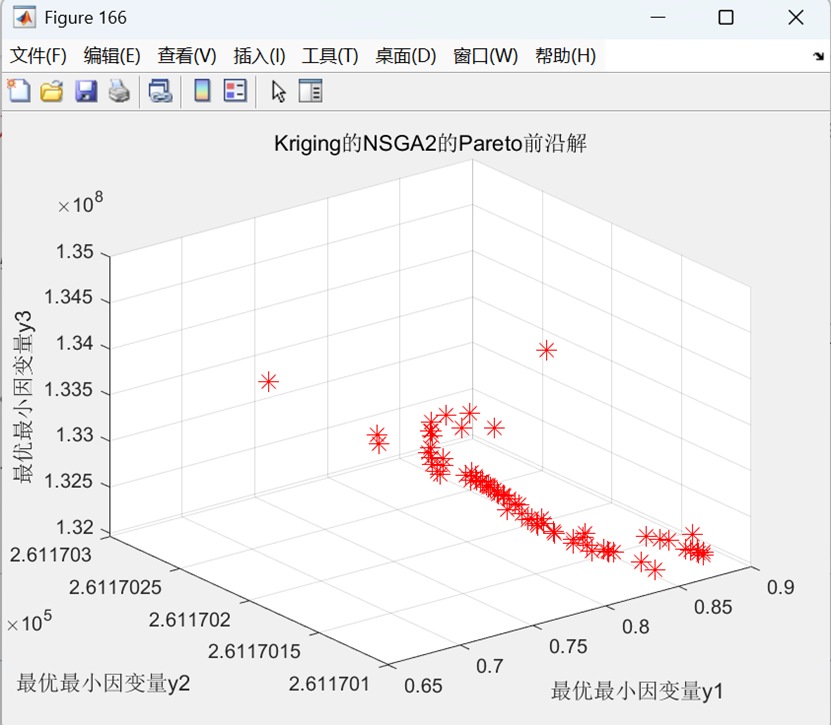
三目标为例图(支持任意多目标,这里只展示二目标和三目标)
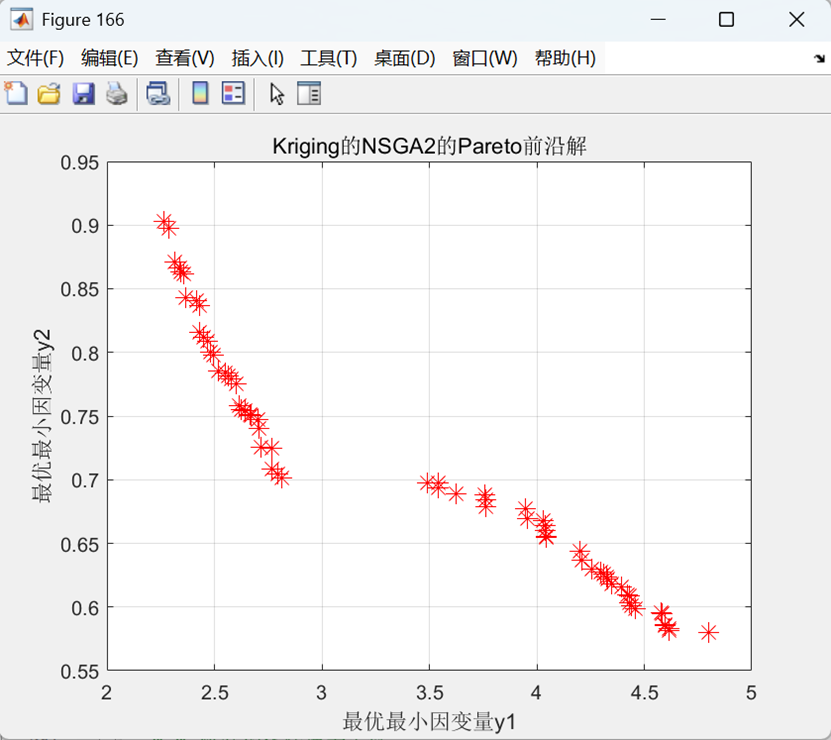
代码整体运行效果如下图:
以二目标为例效果图:
以三目标为例效果图:
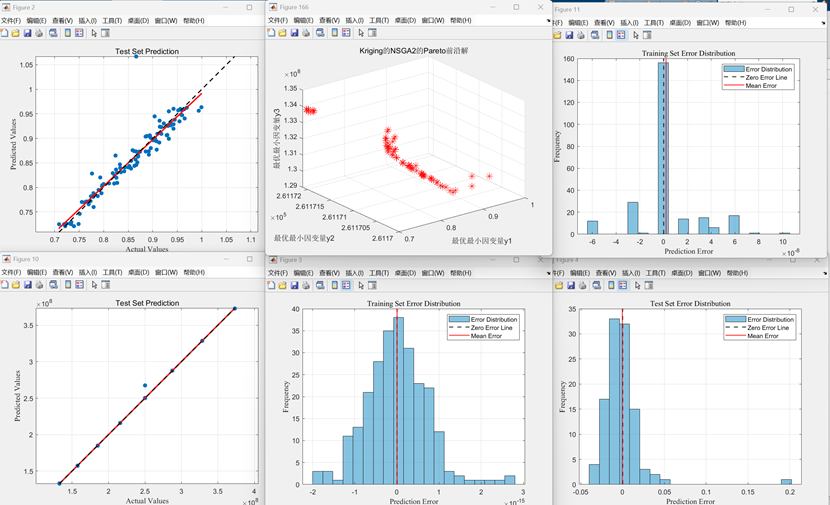
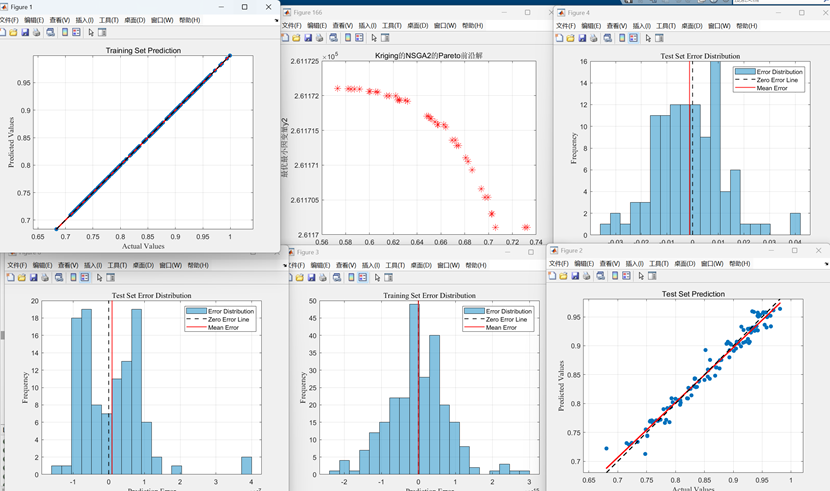
Kriging运行的误差指标如下图:(含mae,mse,rmse,mape和R2)

Kriging的运行效果图如下:
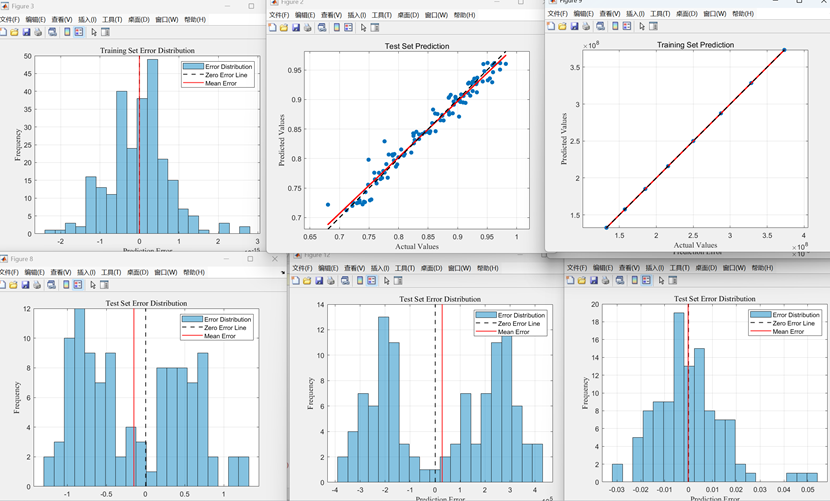
NSGA2-Topsis结合后求解的结果图:

熵权法Topsis求解帕累托前沿解各解的接近度如下:

采用的数据集如下:
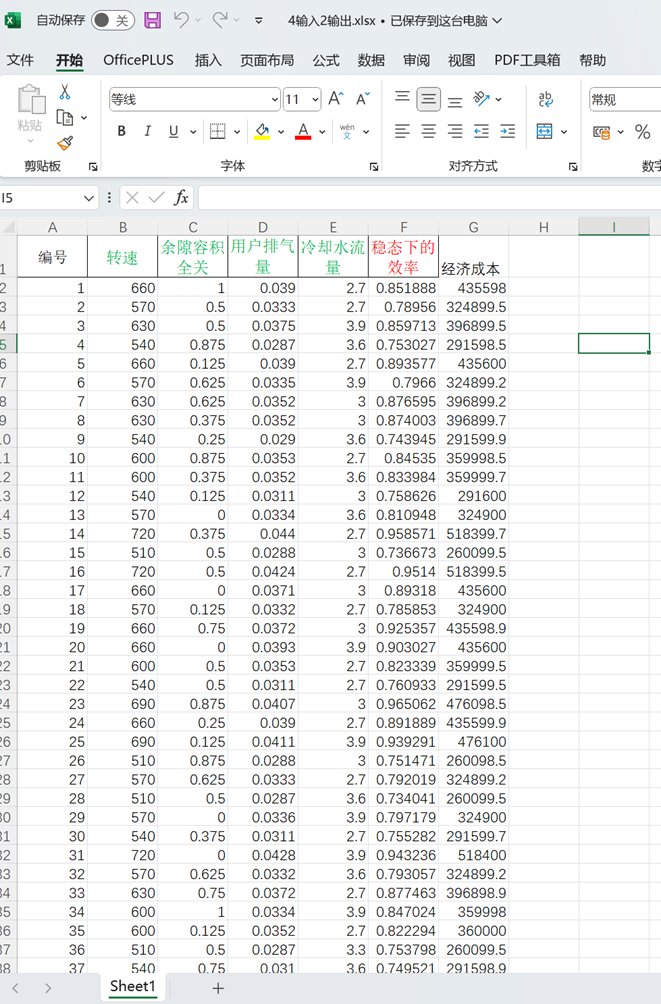
4输入2输出.xlsx如下:
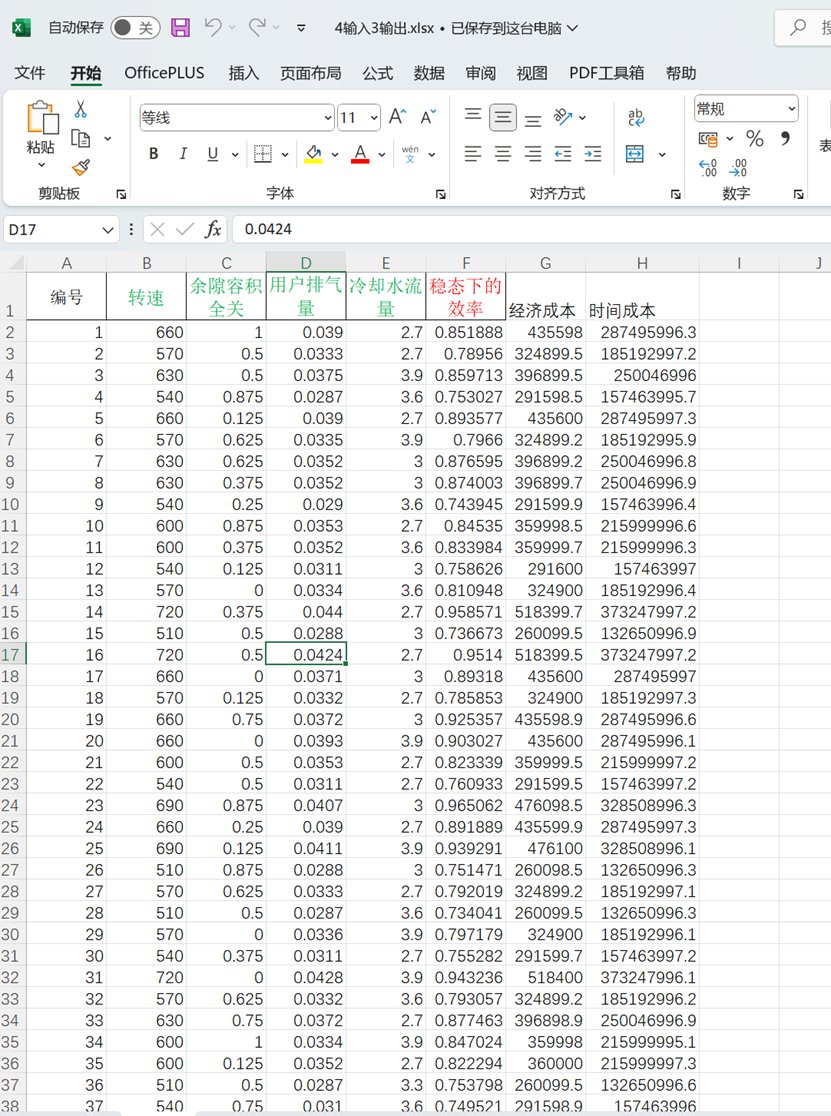
4输入3输出.xlsx如下:
5输入3输出如下:

![]() 编辑
编辑
克里金模型Kriging模型原理说明文档
克里金模型,也称为空间插值法,是一种在空间数据分析中常用的方法,用于估计未知点的值,基于已知点的观测数据和它们之间的空间相关性。
克里金模型的目标是无偏估计,即估计值的期望值等于真实值,这涉及到无偏性条件的数学表达。同时,最小化估计方差的条件,这需要用到拉格朗日乘数法来求解权重系数。
基本假设、变异函数、克里金估计公式、权重求解、不同类型克里金、应用
克里金模型(Kriging)是一种基于空间相关性的插值方法,广泛应用于地质统计学、环境科学等领域。其核心思想是通过已知样本点的观测值,结合空间自相关性,对未知点进行最优无偏估计。以下是其数学原理的核心内容:




克里金(Kriging)与多目标优化的结合是一种在复杂系统建模与决策中常用的方法,其核心是通过克里金模型近似多目标函数的空间分布,并利用多目标优化算法寻找最优解集
克里金与多目标优化的结合通过替代模型降低计算成本,利用空间相关性捕捉目标函数的分布特征,并通过多目标算法寻找帕累托最优解集。其数学原理融合了克里金的插值理论、多变量统计建模和多目标优化技术,是复杂系统决策的重要工具。

首先,Topsis,也就是逼近理想解排序法,是一种多准则决策分析方法。它的基本思想是通过计算各方案与理想解(正理想解)和负理想解之间的距离来进行排序。理想解是各指标的最优值,负理想解是各指标的最劣值。然后根据相对接近度来排序,相对接近度越高,方案越优。
然后是熵权法,这是一种客观赋权方法,用于确定各指标的权重。熵原本是热力学中的概念,后来在信息论中用于衡量信息的不确定性。熵权法通过计算各指标的熵值来判断该指标的离散程度,离散程度越大,熵值越小,信息量越大,权重也就越高。反之,离散程度越小,熵值越大,权重越低。
Topsis 熵权法是指在 Topsis 中使用熵权法来确定各指标的权重,而不是主观赋权。这样可以让权重的确定更客观,减少主观因素的影响。
Topsis 熵权法是一种结合了逼近理想解排序法(Topsis)和熵权法的多准则决策分析方法,主要用于解决多指标评价问题。其核心思想是通过熵权法客观确定指标权重,再利用 Topsis 对方案进行排序。
原理如下:
包括数据标准化、熵权计算、加权矩阵构建、理想解确定、距离计算和排序
1. 数据标准化

2. 熵权法计算指标权重
熵权法通过指标的信息量客观确定权重,步骤如下:


3. 构建加权标准化矩阵

4. 确定正理想解和负理想解


NSGA-2 和 NSGA-3 主要有以下区别:
- 提出时间与背景1
- NSGA-2:1992 年由 Deb 等人提出,是经典多目标优化算法,旨在改进 NSGA 算法,解决其在非支配排序时间复杂度高、不支持精英策略和需指定共享参数等问题。
- NSGA-3:2013 年由 Deb 提出,是基于 NSGA-2 针对高维多目标优化问题改进的算法。因为 NSGA-2 处理三个及以下目标问题表现良好,但处理高维问题时性能会下降。
- 非支配排序策略3
- NSGA-2:将个体按支配关系划分到不同层级,然后按层级从前往后排序。例如,在一个双目标优化问题中,通过比较每个个体在两个目标上的表现,确定其是否被其他个体支配,从而划分层级。
- NSGA-3:通过将个体按照参考点所在的超平面划分到不同集合中,然后按照集合的优先级从前往后排序。先寻找理想点,构建超平面并进行目标归一化,再根据个体与参考点的关系进行划分。
- 选择机制
- NSGA-2:使用拥挤度距离作为衡量标准之一,在同一非支配等级里更倾向于边界上的样本。通过计算每个个体在目标空间中周围个体的密度,选择密度较小区域的个体,以保持种群的多样性。
- NSGA-33:借助预先设置的一系列理想化的目标组合,即 “参考点”,引导搜索路径趋向理想的帕累托前沿形状。计算个体与参考点之间的距离来选择出最优解集,使算法更好地探索前沿解集的不同部分。
- 适用场景3
- NSGA-2:适用于最多三个目标的多目标优化问题。在低维问题中,能够快速找到帕累托前沿,并保持较好的种群多样性。
- NSGA-3:更适合处理高维多目标优化问题,即四个及以上目标的优化问题。在面对高维复杂环境时,能更精准地逼近真实最优解集,在解集的分布性和多样性方面表现更优。
- 种群多样性维持方式
- NSGA - 212:在 NSGA-2 中用拥挤比较的方法替换了共享函数方法,根据每一目标函数计算个体两侧的两个点的平均距离,以最近邻居作为顶点的长方体周长的估计值作为拥挤系数,选择拥挤系数大的个体来维持多样性。
- NSGA - 31:采用种群的自适应标准化和关联操作。通过寻找理想点、计算极值点、构建超平面找到截距并进行目标归一化,让群体中的个体分别关联到相应的参考点,从而维持种群多样性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









