







从今天开始,我将开始跟随B站“黑马程序员”的爬虫项目来学习爬虫的相关知识。希望能坚持到学有所成。
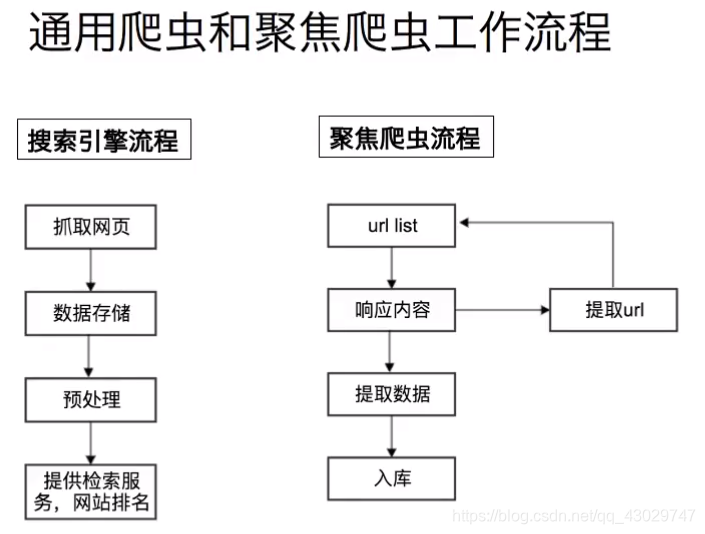
一、爬虫流程
爬虫的本质就是模拟浏览器发送请求,获取响应。
例如登陆https://www.baidu.com/,进入页面之后按F12或者右击鼠标点击检查:

上图右边出现的内容就是此网页的源码等内容。而爬虫的工作就是从网页上爬取关键信息。所以,此时,我们要做的就是获取右边的这一堆内容,并从内容中提取出来目标信息就可以达成目的了。
所以说爬虫需要学好前端和提取内容的方法(如正则表达式)
二、str 类型和 bytes 类型
- bytes 类型是二进制,在互联网上数据的传输都是以二进制传输的。
- str 字符串类型,使用各种编码格式来将其呈现出来,关于编码请看我的这篇文章《编码问题的故事》
编码方式必须与解码方式一样,不然会乱码
>>> a = "西北大学"
>>> type(a)
<class 'str'>
>>> b = a.encode()
>>> type(b)
<class 'bytes'>
>>> b
b'\xe8\xa5\xbf\xe5\x8c\x97\xe5\xa4\xa7\xe5\xad\xa6'
>>> b.encode("utf_8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'bytes' object has no attribute 'encode'
>>> b.decode("utf_8")
'西北大学'
>>> b.decode("UTF_8")
'西北大学'
>>> b.decode("gbk")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 10: illegal multibyte sequence
在上述demo中,encode是编码,decode是解码,当用错误的解码方式去解码时(decode(“gbk”))就会报错。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









