






1 Flink架构与集群安装
现实世界中,许多系统数据是作为连续的事件流进行的,例如汽车GPS定位信号、金融交易记录、手机信号塔与智能手机用户之间的信号交换、网络流量、服务器日志、工业传感器和可穿戴设备的测量等。如果用户能够及时有效地大规模分析这些流数据,就能够更好地理解这些系统,并及时地进行分析。
实时数据分析一直是个热门话题,需要实时数据分析的场景也越来越多,如金融支付中的风控、基础运维中的监控告警、实时大盘等,此外,AI模型也需要依据更为实时的聚合结果来达到很好的预测效果。
Apache Flink是下一代开源大数据处理引擎。它是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算;可部署在各种集群环境,对各种大小的数据规模进行快速计算。

1.1 Flink简介
Flink起源于Stratosphere项目,这是2010—2014年由三所柏林大学和其他欧洲大学共同开展的一项研究项目。2014年4月,Stratosphere代码的一个分支被捐赠给了Apache软件基金会作为一个孵化项目,其初始提交者由系统的核心开发人员组成。此后不久,许多创始人离开大学,创办了一家名叫Data Artisans的公司,用于将Flink商业化。在孵化期间,为了防止与其他不相关的项目混淆,对项目名称进行了更改,选择Flink作为该项目的新名称。
Flink是Apache软件基金会最大的5个大数据项目之一,在全球拥有超过200名开发人员的社区。作为公认的新一代大数据计算引擎,Flink已成为阿里巴巴、腾讯、滴滴、美团、字节跳动、Netflix、Lyft等国内外知名公司建设流计算平台的首选。
1.2 Flink特性
Flink支持流和批处理、复杂的状态管理、事件时间处理语义,以及对状态的一次一致性保证。此外,Flink可以部署在各种资源提供者(如YARN、Apache Mesos和Kubernetes)上,也可以作为独立集群部署在裸机硬件上。可以将Flink集群配置为高可用的以避免单点故障。
Flink设计用于在任何规模上运行有状态流应用程序。应用程序可能被并行化为数千个任务,这些任务分布在集群中并且并行执行,因此,一个应用程序可以利用几乎无限数量的CPU、主内存、磁盘和网络IO。此外,Flink很容易维护非常大的应用程序状态。它的异步和增量检查点算法在保证精确一次性的状态一致性的同时,确保对处理时延的影响最小。
Apache Flink为用户提供了更强大的计算能力和更易用的编程接口:
(1)批流统一。Flink在Runtime和SQL层批流统一,提供高吞吐低延时计算能力和更强大的SQL支持。
(2)生态兼容。Flink能与Hadoop YARN/Apache Mesos/Kubernetes集成,并且支持单机模式运行。
(3)性能卓越。Flink提供了性能卓越的批处理与流处理支持。
(4)规模计算。Flink的作业可被分解成上千个任务,分布在集群中并行执行。
1.3 Flink应用场景
(1)事件驱动类型,例如信用卡交易、刷单、监控等。
(2)数据分析类型,例如库存分析、“双11”数据分析等。
(3)数据管道类型,也就是ETL场景,例如一些日志的解析等。
Apache Flink支持流及批处理分析应用程序
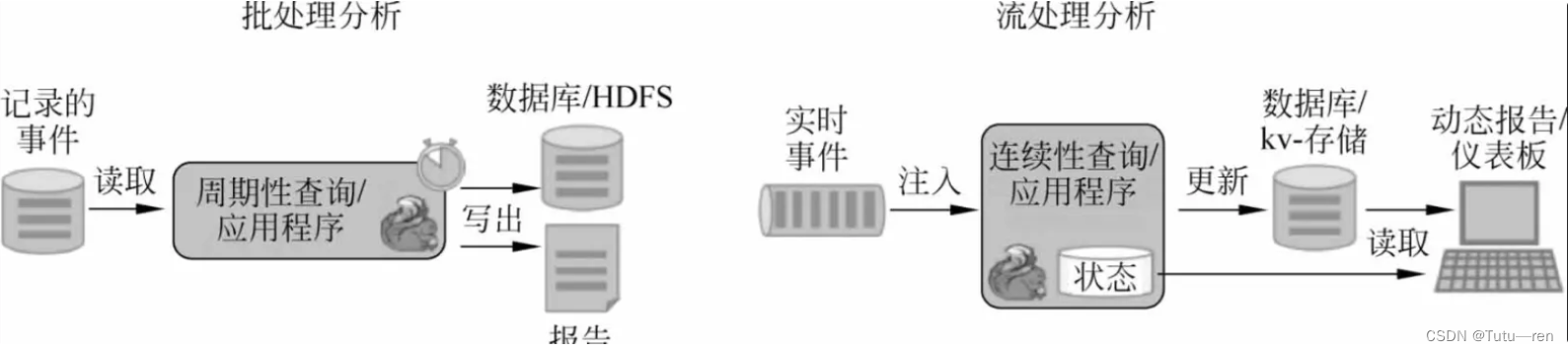
Flink为连续流和批处理分析提供了非常好的支持。具体来讲,它具有一个符合ANSI的SQL接口,具有用于批处理和流查询的统一语义。无论SQL查询是在记录事件的静态数据集上运行,还是在实时事件流上运行,它们都会计算出相同的结果。对用户定义函数的丰富支持确保可以在SQL查询中执行定制代码。如果需要更多的定制逻辑,Flink的DataStream API或DataSet API提供了更多的底层控制。此外,Flink的Gelly库为批量数据集的大规模和高性能图分析提供了算法和构建块。
典型的数据分析应用程序包括:
(1)电信网络质量监控。
(2)移动应用程序中的产品更新及用户体验分析。
(3)消费者技术中实时数据的即时(Ad Hoc)分析。
(4)大规模图分析。
1.4 Flink体系架构
Apache Storm支持低时延,但目前不支持高吞吐量,也不支持在发生故障时正确处理状态。Apache Spark Streaming的微批处理方法实现了高吞吐量的容错性,但是难以实现真正的低延时和实时处理,并且表达能力方面也不是特别丰富;而Apache Flink兼顾了低时延和高吞吐量,是企业部署流计算时的首选。

1.5 Flink运行时架构
Flink运行时是Flink的核心计算结构,这是一个分布式系统,它接受流数据处理程序,并在一台或多台机器上以容错的方式执行这些数据流程序。这个运行时可以作为YARN的应用程序在集群中运行,也可以在Mesos集群中运行,或者在一台机器中运行(通常用于调试Flink应用程序)。Flink运行时层的整个架构采用了标准Master-Slave的结构,即总是由一个Flink Master(JobManager)和一个或多个Flink Slave(TaskManager)组成。
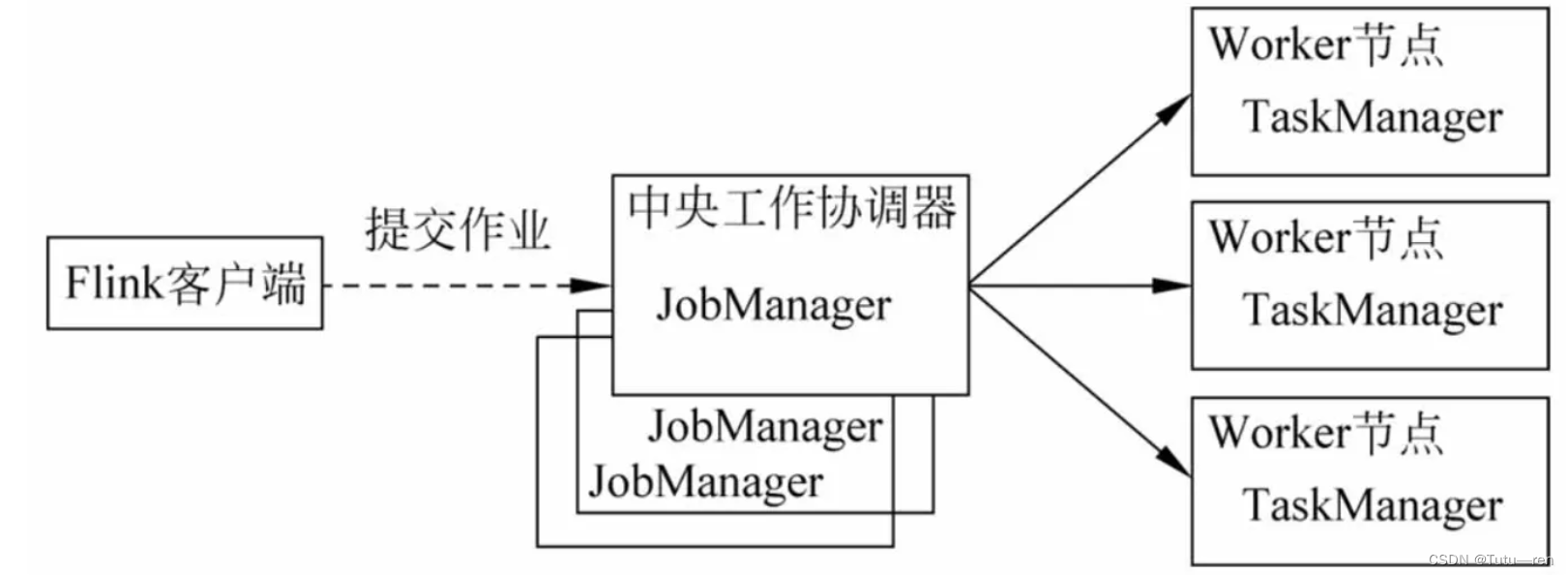
Flink运行时由两种类型的进程组成:一个JobManager和一个或多个TaskManager。客户端不是运行时和程序执行的一部分,而是用于准备数据流并将数据流发送到JobManager。在此之后,客户端可以断开连接(分离模式),或者保持连接以接收进度报告(附加模式)。客户端可以作为触发执行的Java/Scala程序的一部分运行,也可以在命令行进程(./bin/flink run)中运行。
2 独立集群安装测试
2.1 安装
安装前要确定好安装的版本和Java版本
使用Flink版本是flink-1.13.2-bin-scala_2.12.gz,需要Java版本是Java8或11
java -version
然后把安装包上传至虚拟机中,并解压
tar -zxvf flink-1.13.2-bin-scala_2.12.gz
解压后目录为flink-1.13.2
切换到该目录,可以看到以下目录和文件
cd flink-1.13.2 && ls -l
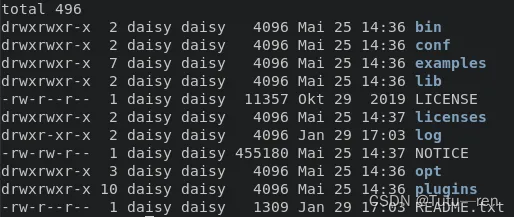
- bin/ 目录包含二进制文件以及几个管理各种作业和任务的 bash 脚本
flink
- conf/ 目录包含配置文件,包括
flink-conf.yaml
- examples/ 目录包含可以按原样使用 Flink 的示例应用程序
2.2 启动和停止本地群集
./bin/start-cluster.sh

使用jps命令查看进程

可以在浏览器访问,但是前提是虚拟机防火墙允许程序通过,这里我们直接关闭防火墙,实际工作中不可以关闭防火墙
systemctl status firewalld
systemctl stop firewalld
systemctl disable firewalld
2.3 运行Flink自带的实时单词计数流程序
Flink安装包自带了一个以Socket作为数据源的实时统计单词计数的流程序,位于Flink下的example/streaming/SocketWindowWordCount.jar包中。可以通过运行这个流程序来测试Flink集群的使用方法。
- 首先,启动netcat服务器,运行在9000端口,使用的命令
# 因为没有netcat服务,我们首先需要安装
yum -y install nc
nc -l 9000
2. 打开另一个终端,启动Flink集群
cd flink
./bin/start-cluster.sh # 如果已经启动了Flink,那么最好重新启动
3. 启动Flink示例程序,监听netcat服务器的输入
./bin/flink run ./examples/streaming/SocketWindowWordCount.jar --hostname localhost --port 9000
4. 切换回第一个终端,在netcat控制台,键入一些单词,Flink将会处理这些单词
5. 启动第3个终端窗口,并在该窗口中执行以下命令,查看日志中的输出
tail -f flink-root-taskexecutor-0-localhost.localdomain.out
cat flink-root-taskexecutor-0-localhost.localdomain.out
还可以检查Flink Web UI来查看Job是怎样执行
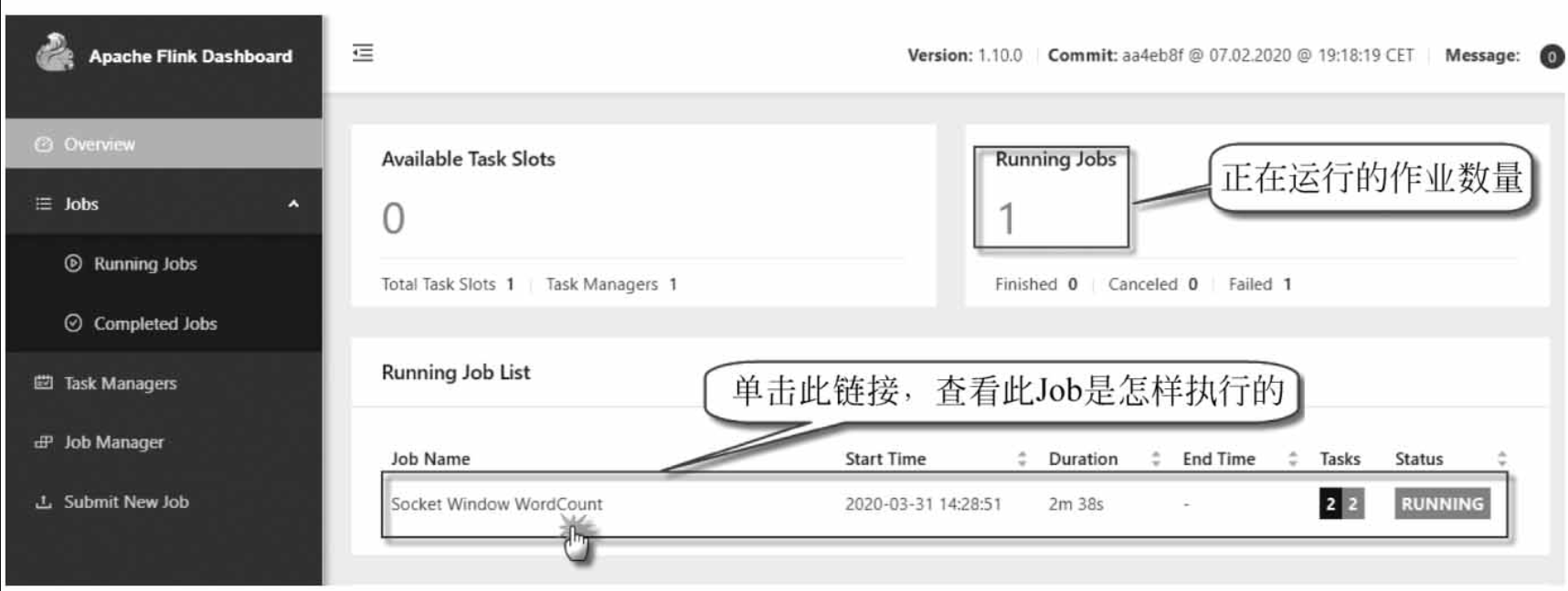
3 Flink开发环境准备
环境要求:
●Java 8以上
●Maven 3.X
●Java、Scala
●IDEA
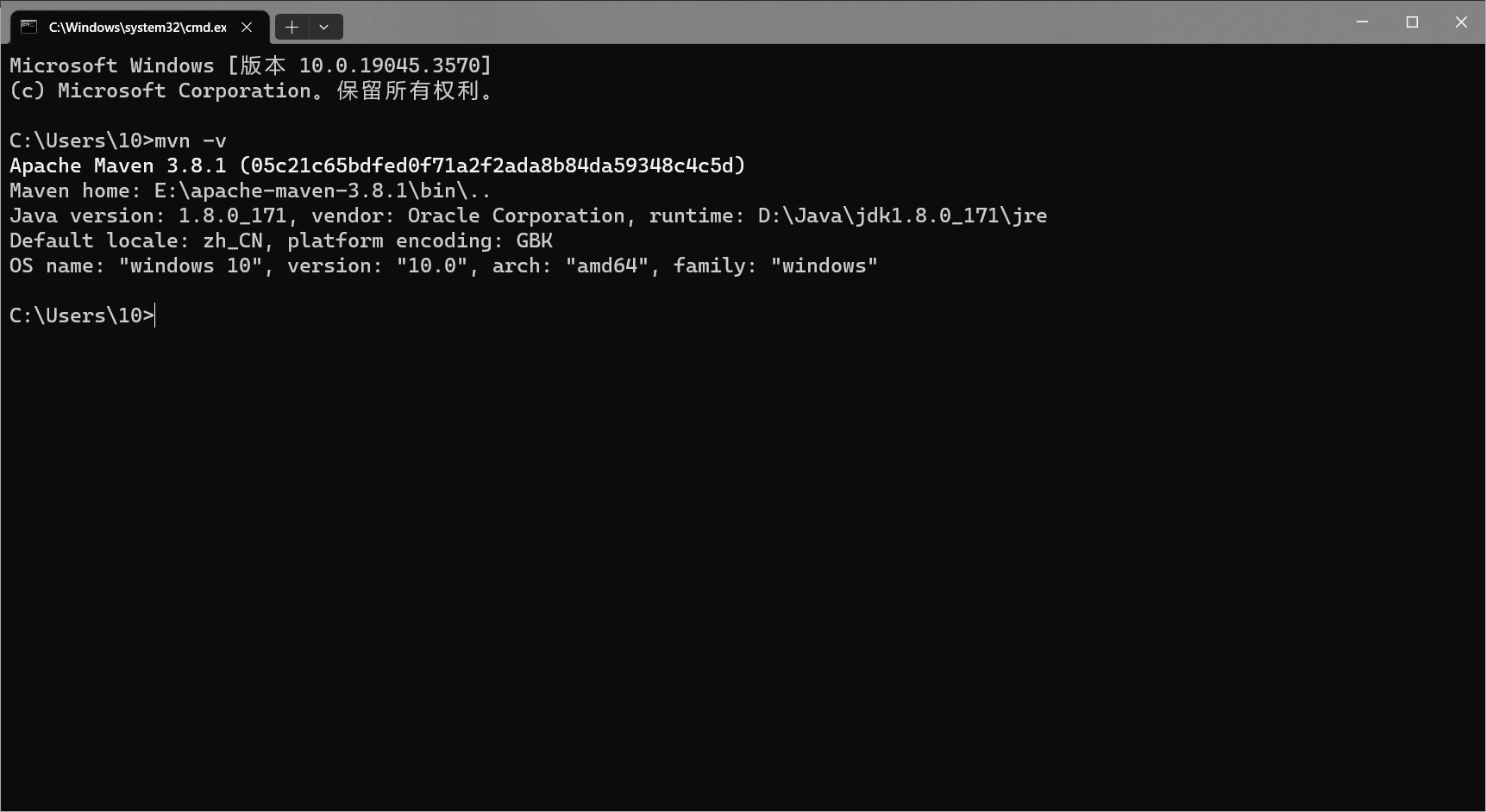
3.1 安装Maven
1 下载:https://mirrors.huaweicloud.com/apache/maven/maven-3/3.6.2/binaries/apache-maven-3.6.2-bin.zip,需要解压到磁盘的根目录
2 配置环境变量

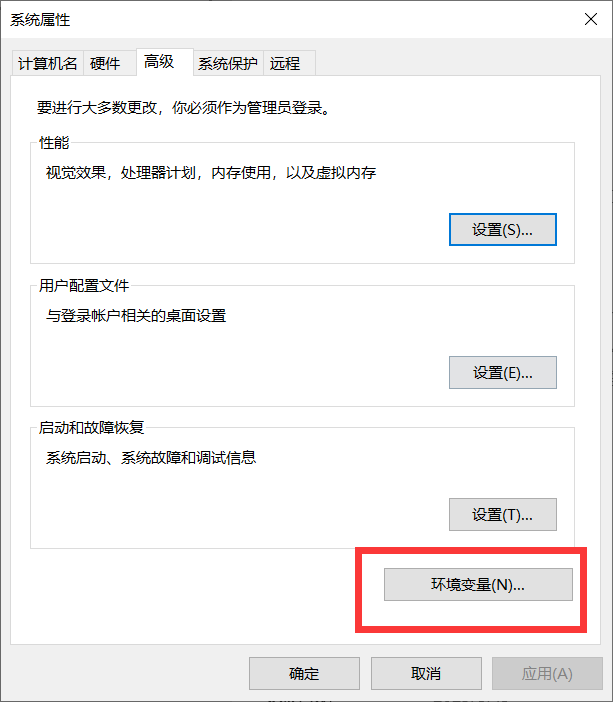
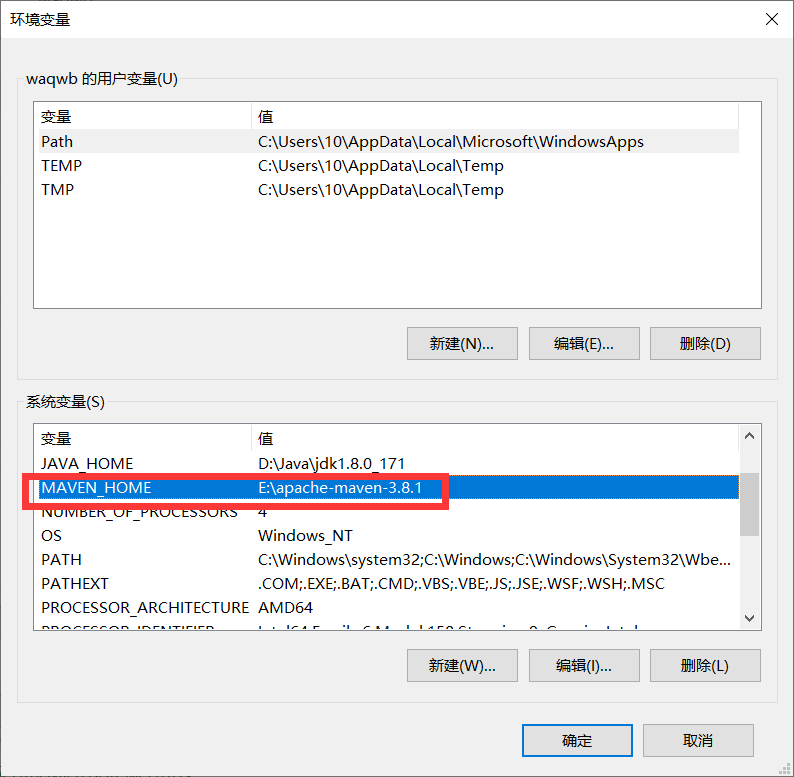
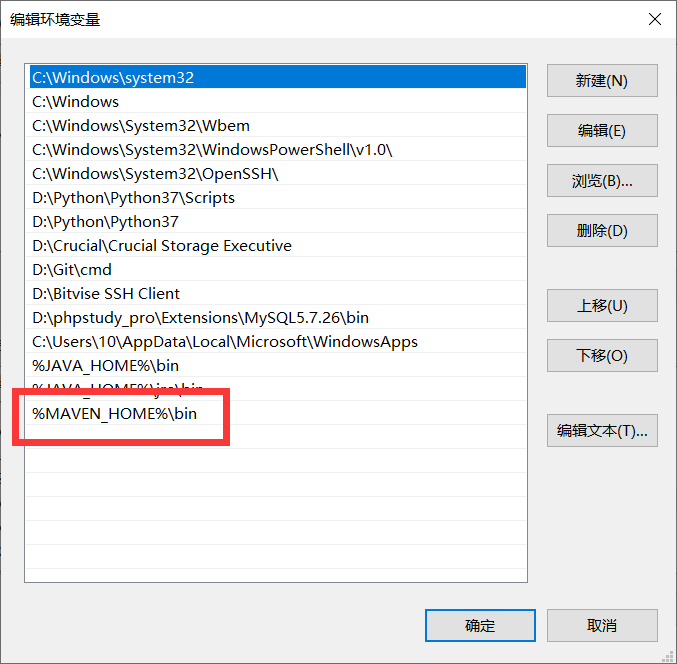
3 修改settings文件
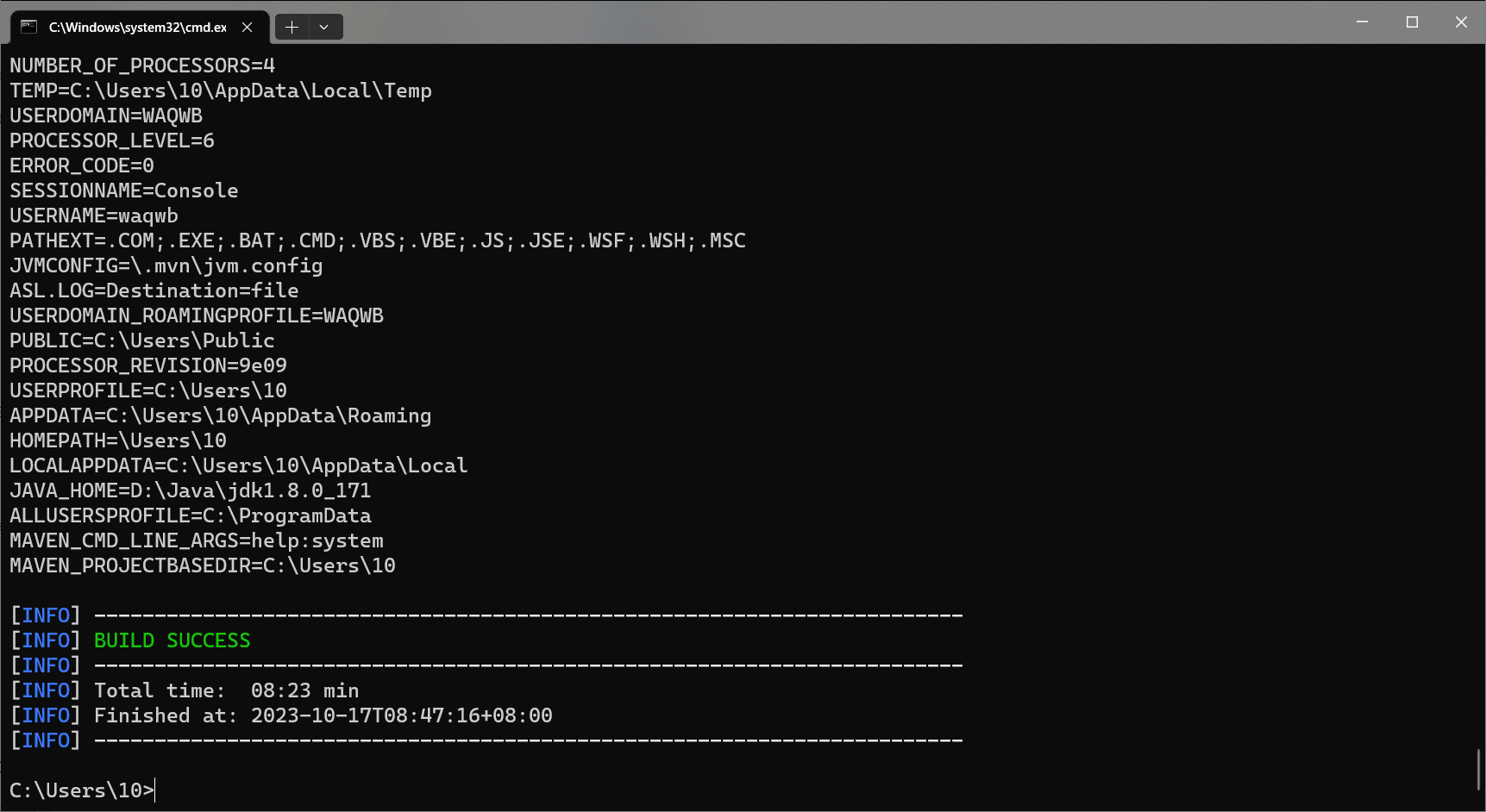
4 验证修改是否生效
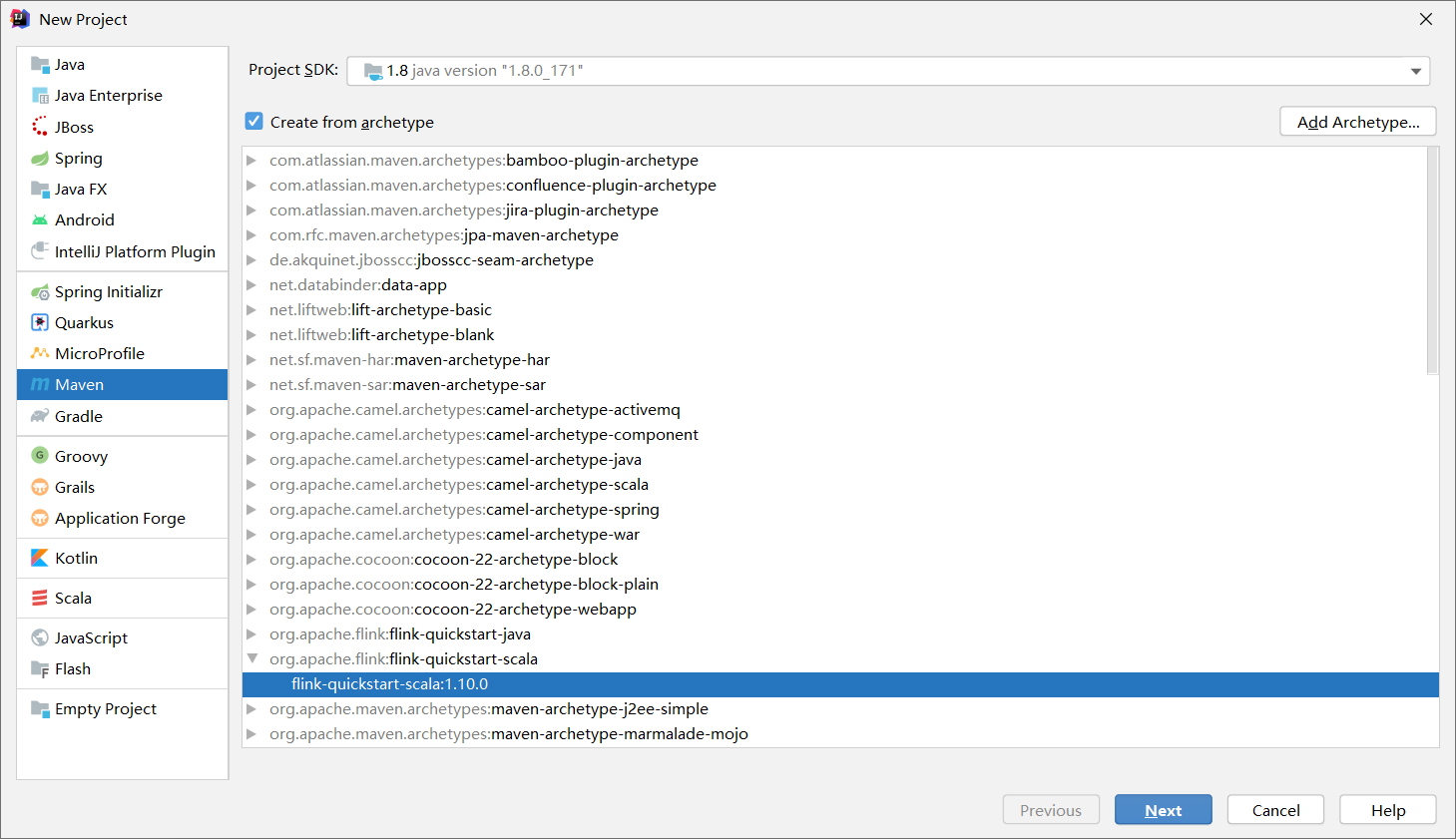
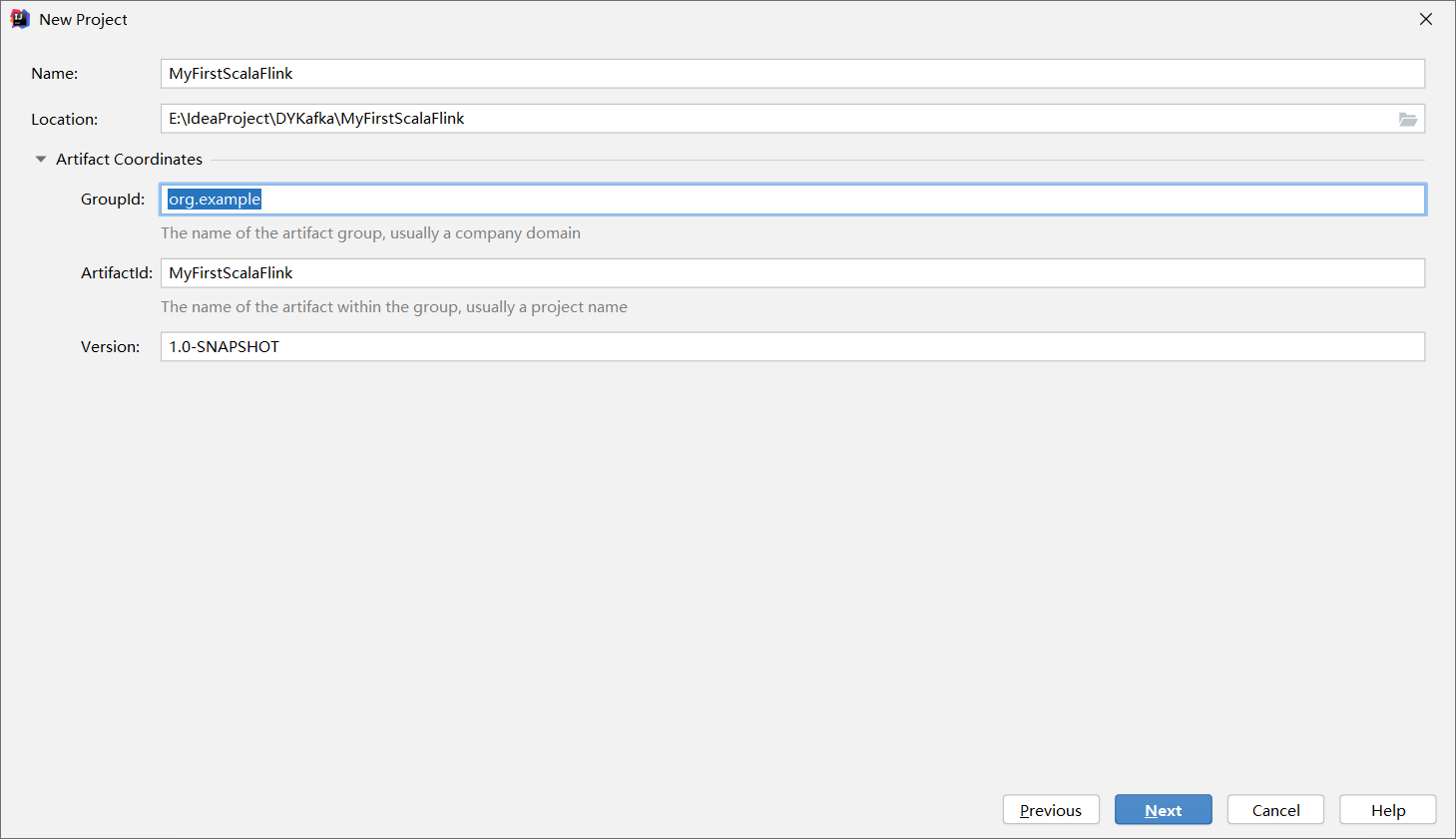
3.2 创建初始模板项目
●groupid:cn.highstrong
●artifactid:FlinkBlankJava
●package:cn.highstrong
剩下的可以自行设置或者直接回车
如果要创建一个Scala语言的空白Flink模板,只需要把flink-quickstart-java中的java替换成scala,其他操作都一样 mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-scala -DarchetypeCatalog=local -DarchetypeVersion=1.10.0
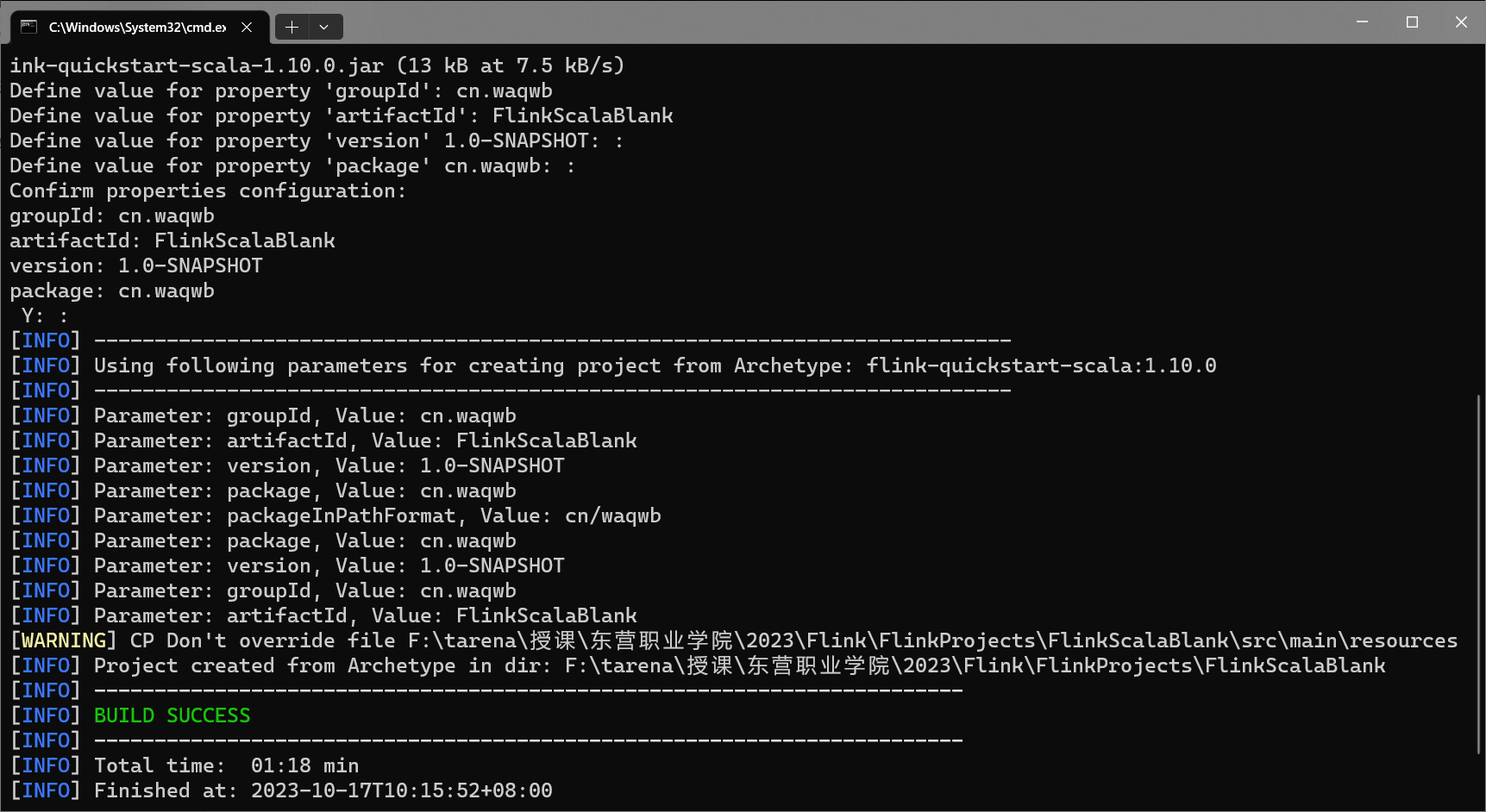
3.3 构建打包项目
切换到项目路径,然后执行mvn命令对该项目进行打包
打包项目后,会在项目路径下生成一个target目录,打包的结果就在这个目录中(是一个jar文件)
3.4 使用IDEA+Maven开发Flink项目
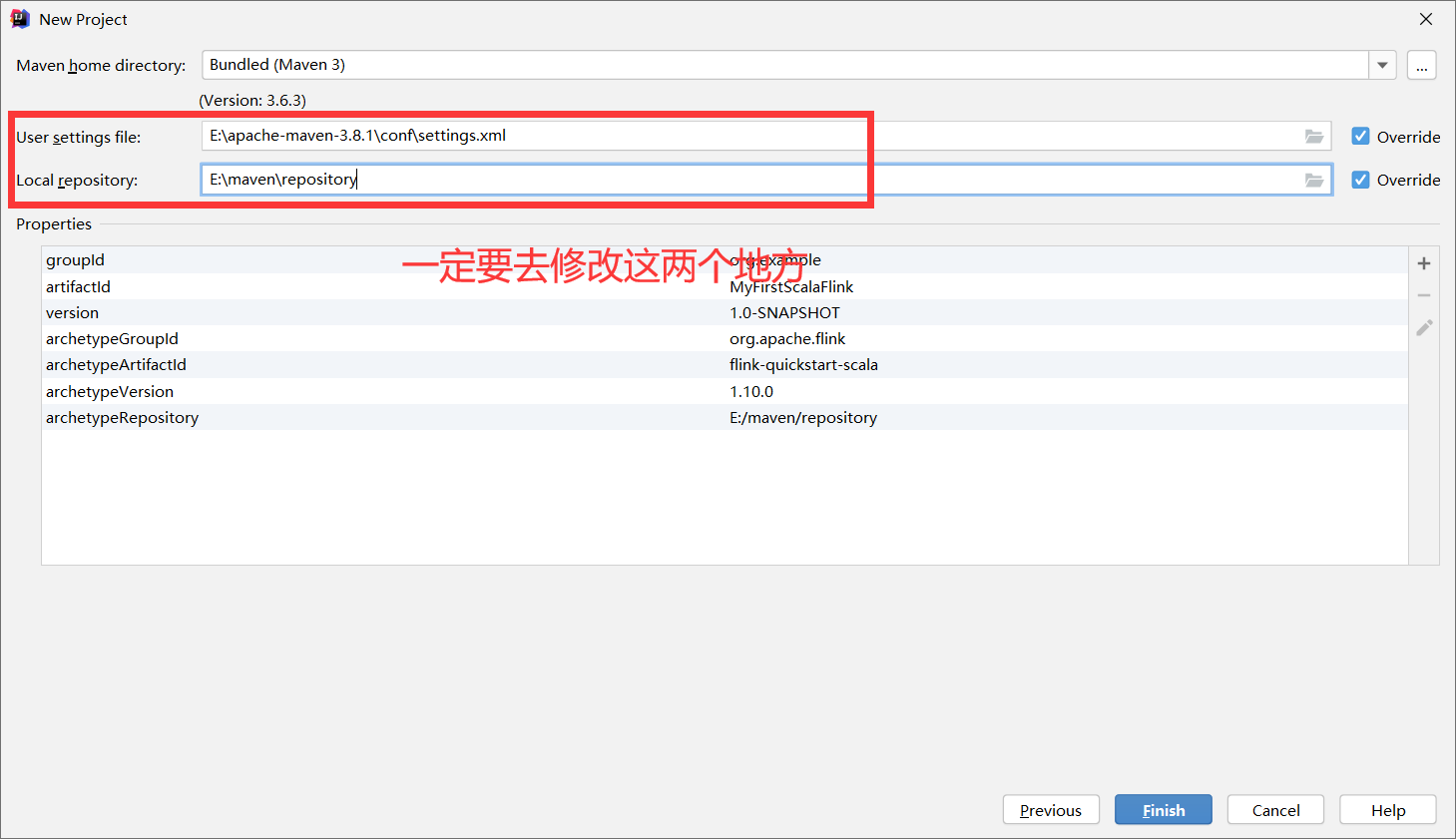
在IDEA中创建项目,但是maven的骨架中是没有flink相关的,我们需要手动去添加
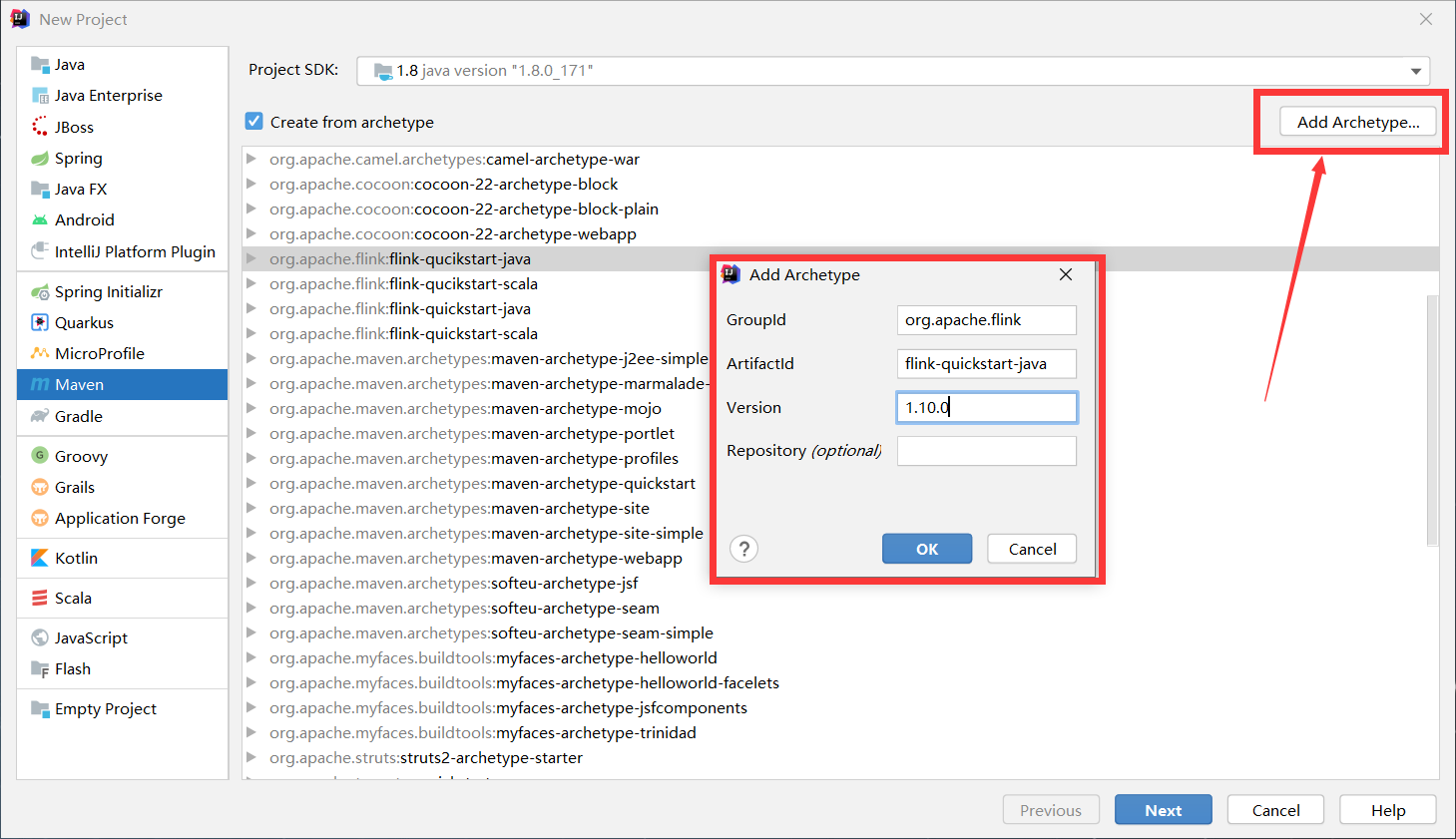
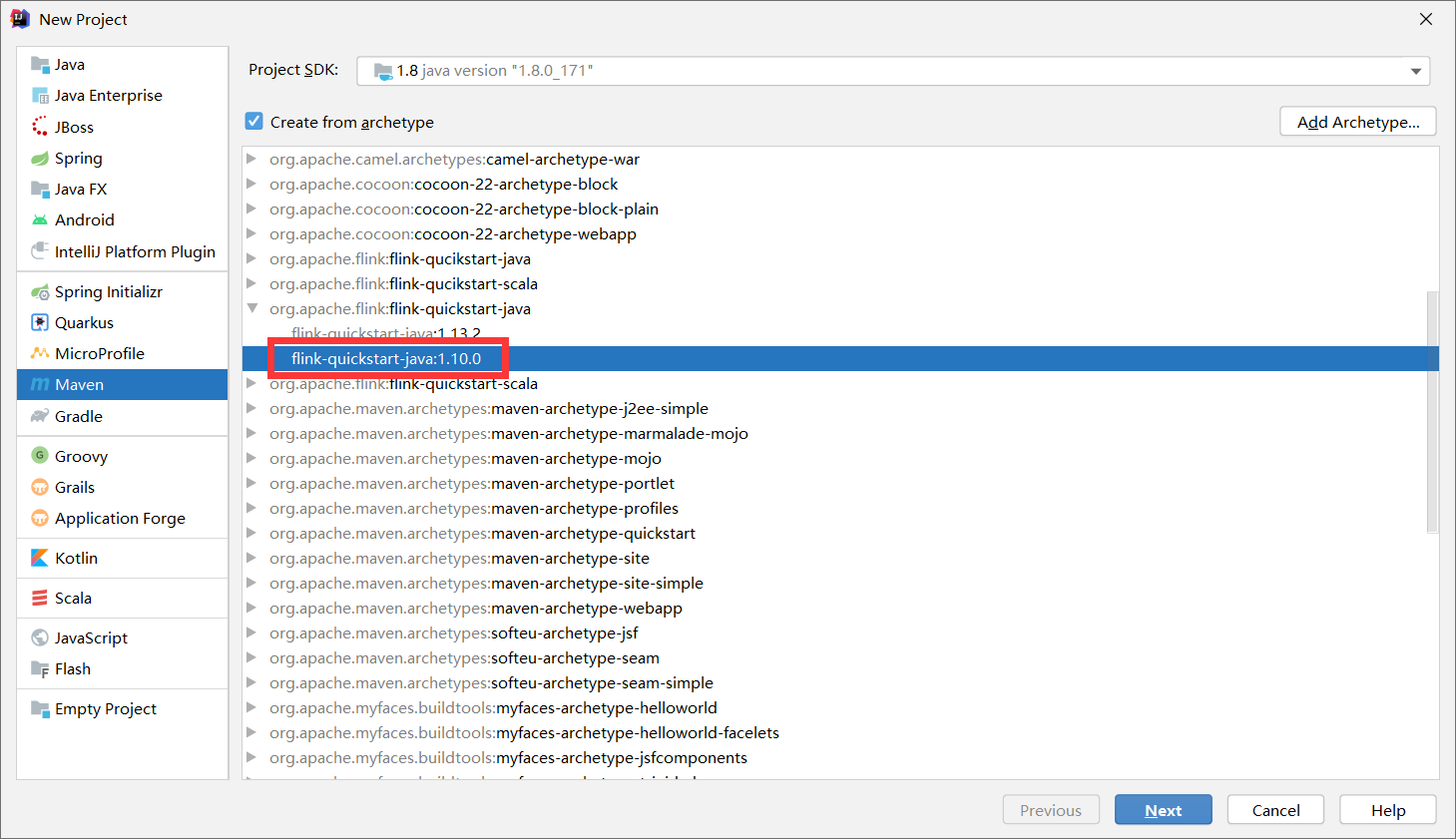
修改maven配置
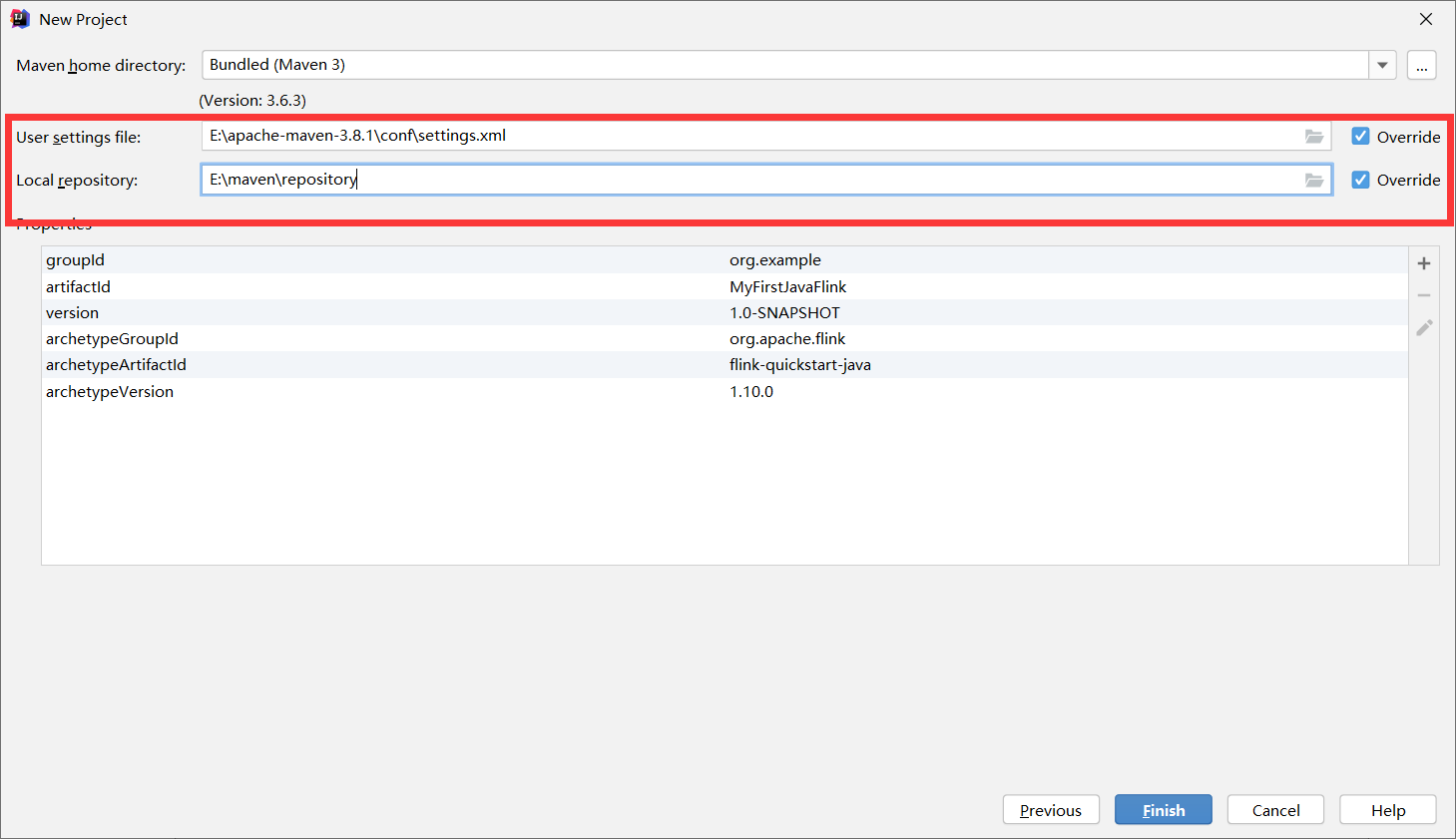
打开项目,如果项目构建速度较慢,可以在较慢的那个jar包停止,然后手动下载jar包,复制到我们指定的本地repository中,然后再次构建项目
3.5 编写批处理代码并测试
如果直接运行,可能会发生以下错误
这个错误需要我们在pom.xml中的依赖去掉<scope>provided</scope>

3.6 项目打包并提交到Flink执行
执行命令
然后把jar文件上传至flink

启动flink
执行命令
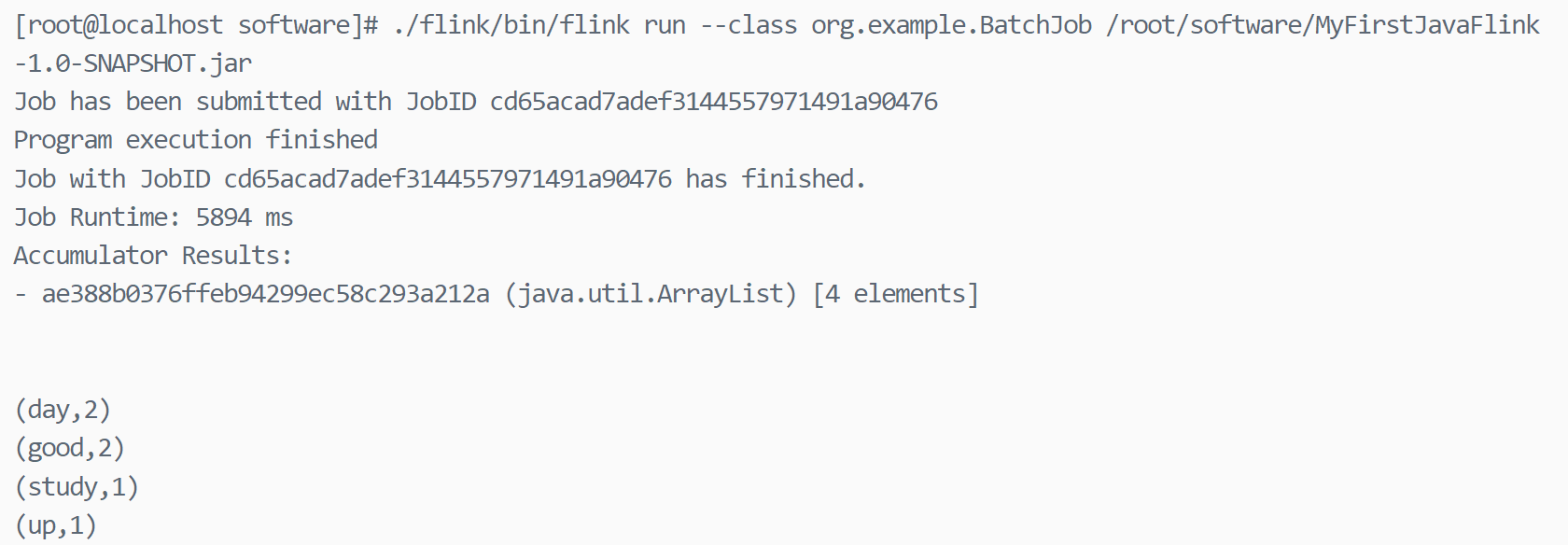
如果以下错误
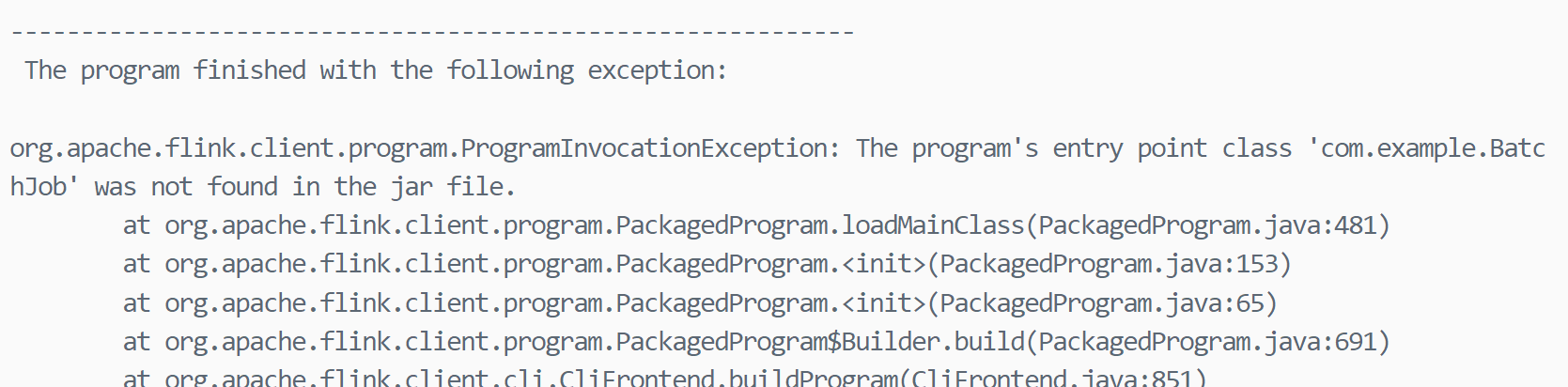
说明pom.xml中的mainClass没有修改
3.7 Scala代码
如果没有scala
运行时,如果报错
说明在pom.xml中有<scope>provided</scope>,注释掉,并更新下maven即可
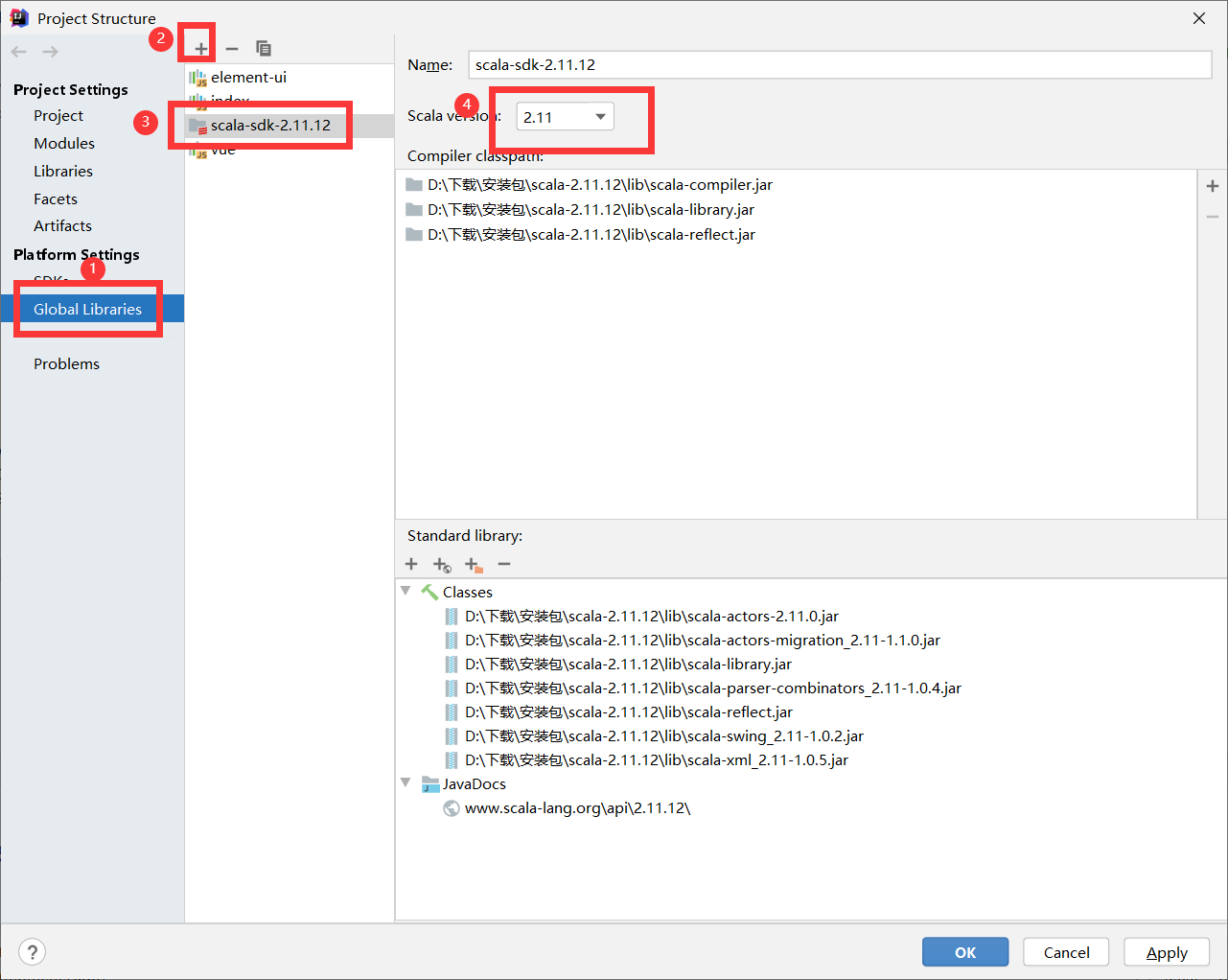
需要添加scala
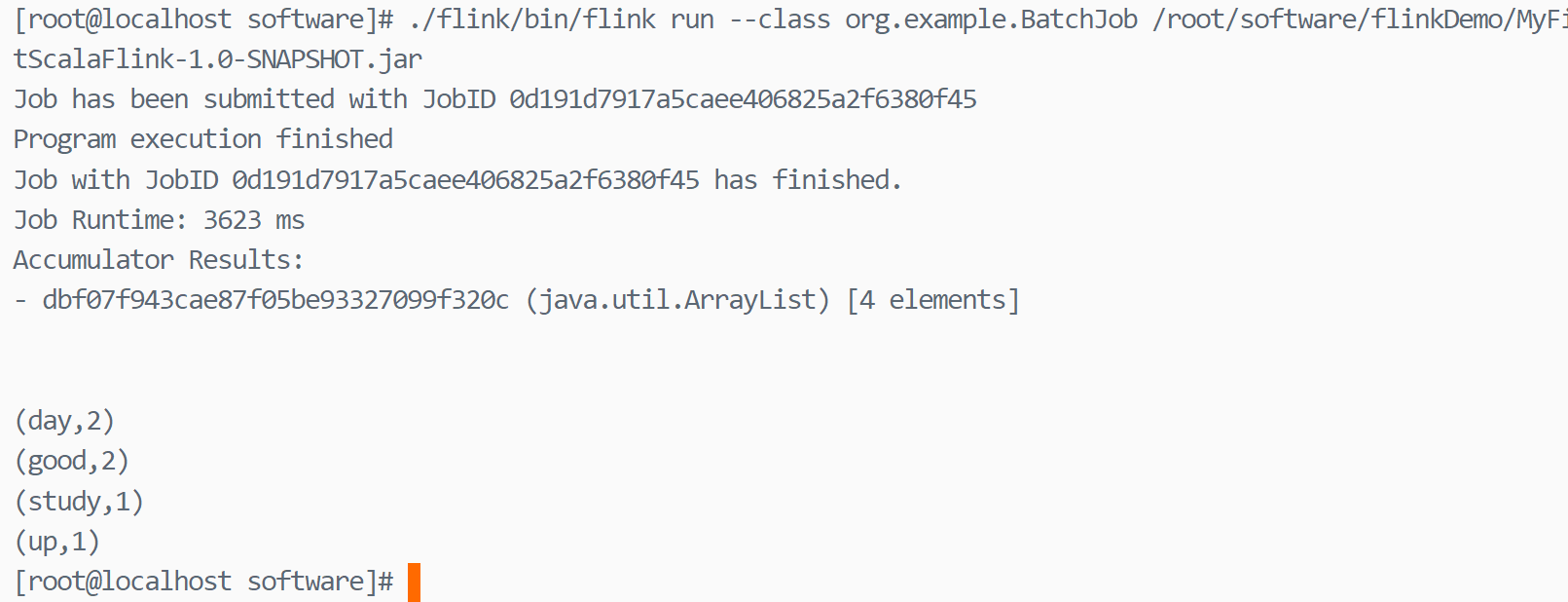
打开web监控网站
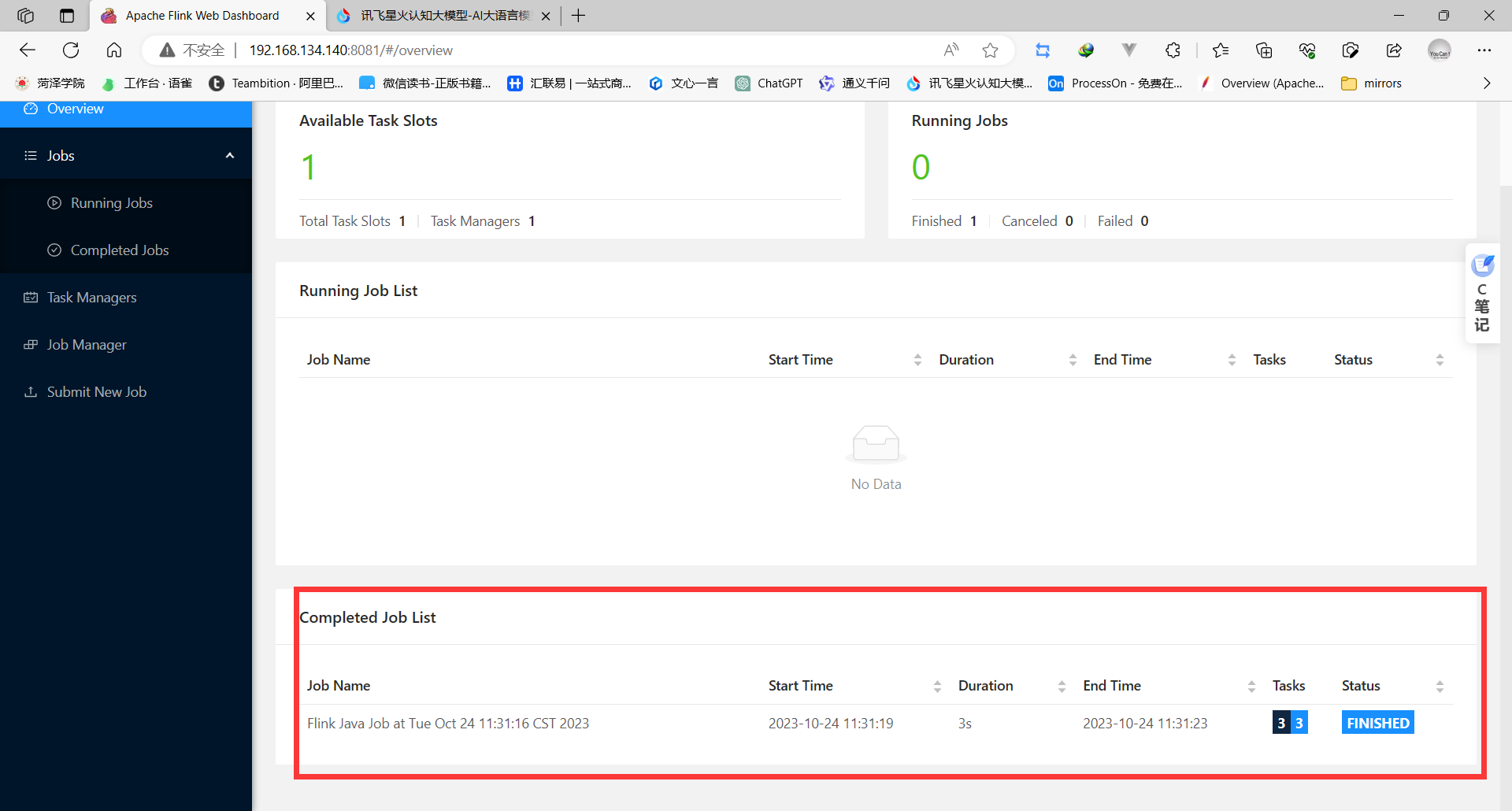
4 开发Flink实时数据处理程序
实时分析是当前非常重要的一个问题。许多不同的领域需要实时处理数据。例如,来自物联网(IoT)的应用程序需要实时或近实时地存储、处理和分析数据。
为了满足对实时数据处理的需求,Apache Flink提供了一个名为DataStream API的流数据处理API,用于构建健壮的、有状态的流应用程序。它提供了对状态和时间的细粒度控制,允许实现高级事件驱动系统。
Apache Flink的流处理API(DataStream API)位于org.apache.flink.streaming.api.scala包(Scala语言)或org.apache.flink.streaming.api包(Java语言)中。
4.1 Flink流处理程序编程模型
4.1.1 流数据类型
基于Java和Scala语言,Flink实现了一套自己的类型系统,它支持很多类型,包括:
(1)基本类型。
(2)数组类型。
(3)复合类型。
(4)辅助类型。
(5)通用类型。
Flink针对Java和Scala的DataStream API要求流数据的内容必须是可序列化的。Flink内置了以下类型数据的序列化器。

(1)基本数据类型:String、Long、Integer、Boolean、Array。
(2)复合数据类型:Tuple、POJO、Scala case class。
对于其他类型,Flink会返回Kryo。也可以在Flink中使用其他序列化器。Avro尤其得到了很好的支持。
4.1.2 Java DataStream API使用的流数据类型
对于Java API,Flink定义了自己的Tuple1~Tuple25类型来表示元组类型
在Java中,POJO(Plain Old Java Object)是这样的Java类:
(1)有一个无参的默认构造器。
(2)所有的字段要么是public的,要么有一个默认的getter和setter。
4.1.3 Scala DataStream API使用的流数据类型
对于元组,可以使用Scala自己的Tuple类型
对于对象类型,使用case class(相当于Java中的JavaBean)
4.1.4 Flink类型系统
对于创建的任意一个POJO类型,看起来它是一个普通的Java Bean,在Java中,可以使用Class来描述该类型,但其实在Flink引擎中,它被描述为PojoTypeInfo,而PojoTypeInfo是TypeInformation的子类。
TypeInformation是Flink类型系统的核心类。Flink使用TypeInformation来描述所有Flink支持的数据类型,就像Java中的Class类型一样。每种Flink支持的数据类型都对应于TypeInformation的子类。例如POJO类型对应的是PojoTypeInfo、基础数据类型数组对应的是BasicArrayTypeInfo、Map类型对应的是MapTypeInfo、值类型对应的是ValueTypeInfo。
除了对类型的描述,TypeInformation还提供了对序列化的支持。在TypeInformation中有一种方法:createSerializer方法,它用来创建序列化器,在序列化器中定义了一系列的方法,其中,通过serialize和deserialize方法可以将指定类型进行序列化,并且Flink的这些序列化器会以稠密的方式将对象写入内存中。Flink中也提供了非常丰富的序列化器。在基于Flink类型系统支持的数据类型进行编程时,Flink在运行时会推断出数据类型的信息,程序员在基于Flink编程时,几乎不需要关心类型和序列化。
4.1.5 类型与Lambda表达式支持
在编译时,编译器能够从Java源代码中读取完整的类型信息,并强制执行类型的约束,但在生成class字节码时会将参数化类型信息删除,这就是类型擦除。类型擦除可以确保不会为泛型创建新的Java类,泛型是不会产生额外的开销的。也就是说,泛型只是在编译器编译时能够理解该类型,但编译后在执行时泛型会被擦除。
以上是一段Java的泛型方法,但在编译后,编译器会将未绑定类型的T擦除,替换为Object
编译之后的代码
泛型只能防止在运行时出现类型错误,但运行时会出现以下异常,而且Flink以非常友好的方式提示:
因为Java编译器可将类型擦除,所以Flink根本无法推断算子(例如flatMap)要输出的类型是什么,所以在Flink中使用Lambda表达式时,为了防止因类型擦除而出现运行时错误,需要指定TypeInformation或者TypeHint。
创建TypeInformation
创建TypeHint
4.2 流应用程序实现
Flink程序的基本构建块是stream和transformation(流和转换)。从概念上讲,stream是数据记录的流(可能永远不会结束),transformation是一个运算,它接收一个或多个流作为输入,经过处理/计算后生成一个或多个输出流。
将有关人员的记录流作为输入,并从中筛选出未成年人信息。
Scala
(1)在IntelliJ IDEA中创建一个Flink项目,使用flink-quickstart-scala项目模板
(2)设置依赖。
(3)创建主程序StreamingJobDemo1
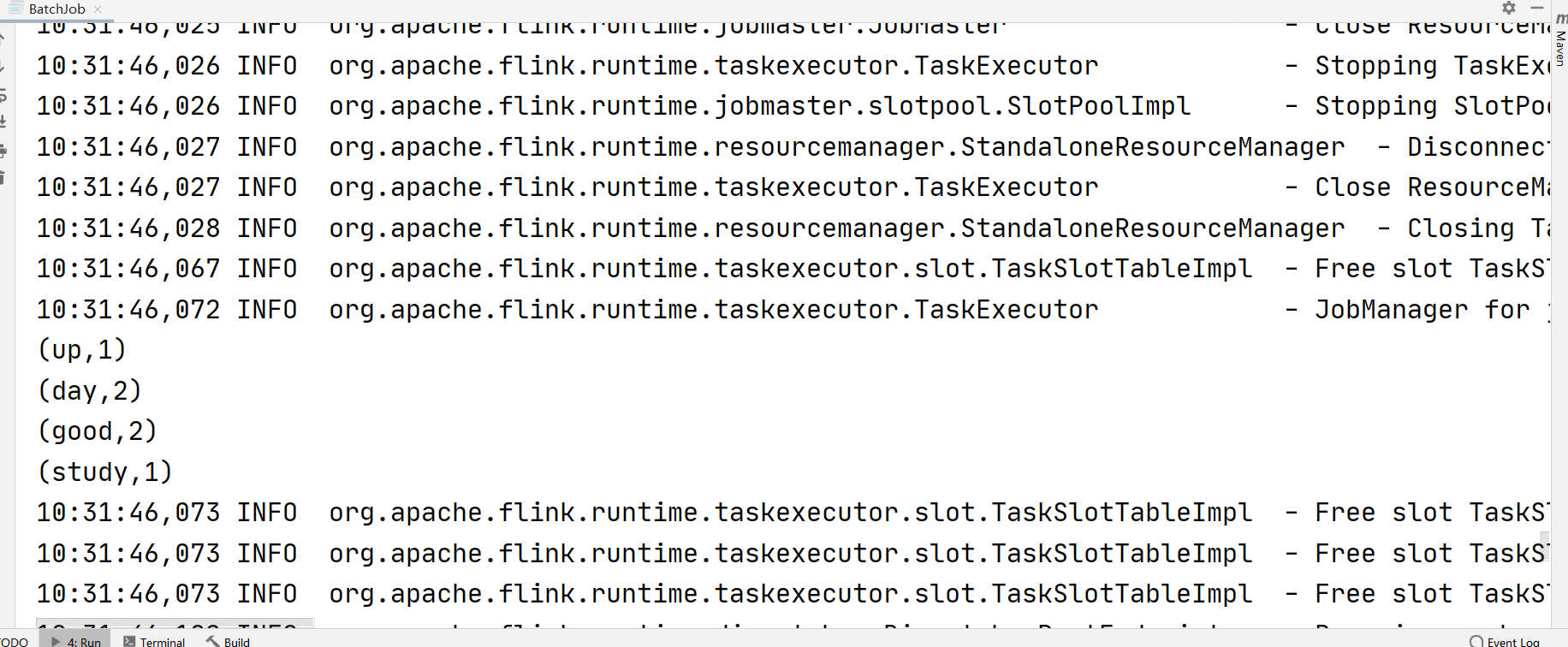
执行以上代码,输出结果如下:

Java
(1)在IntelliJ IDEA中创建一个Flink项目,使用flink-quickstart-Java项目模板
(2)设置依赖
(3)创建一个POJO类,用来表示流中的数据
(4)打开项目中的StreamingJob对象文件,编辑流处理代码如下:
(5)执行以上程序,输出结果如下。

注意:
Flink将批处理程序作为流程序的一种特殊情况执行,其中流是有界的(有限数量的元素)。
DataSet在内部被视为数据流,因此,上述概念同样适用于批处理程序,也适用于流程序,只有少数例外:
(1)批处理程序的容错不使用检查点。错误恢复是通过完全重放流实现的,这使恢复的成本更高,但是因为它避免了检查点,所以使常规处理更轻量。
(2)DataSet API中的有状态运算使用简化的in-memory/out-of-核数据结构,而不是key-value索引。
(3)DataSet API引入了特殊的同步(基于superstep)迭代,这只可能在有界流上实现。
4.3 Flink支持的数据源
数据源是Flink程序获取数据的地方。
●Kafka
●CSV
●文件
●其他数据源
4.3.1 基于Socket的数据源
Data Stream API支持从Socket套接字读取数据。只需要指定从其中读取数据的主机和端口。
读取套接字的数据源函数:
●socketTextStream(hostName,port)
Scala
步骤:
1 启动一个netcat服务器,端口是9999 nc -lk 9999
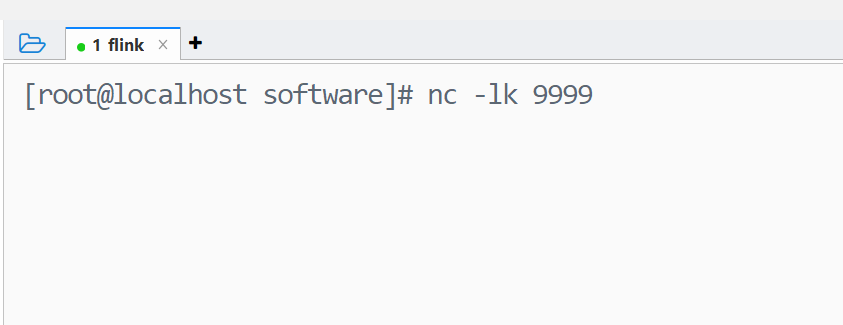
2 运行流程序应用
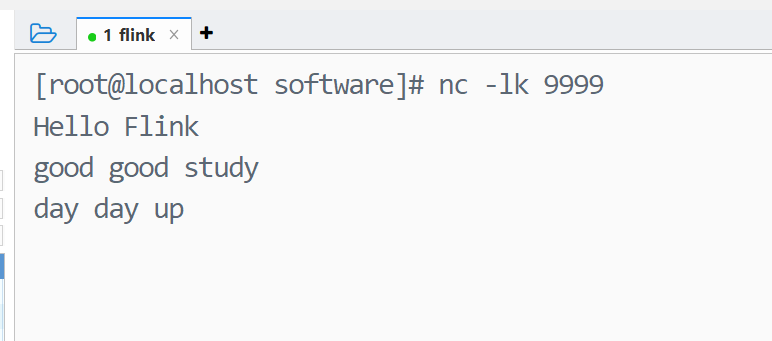
3 在netcat的窗口,输入想要发送的内容,并按回车发送
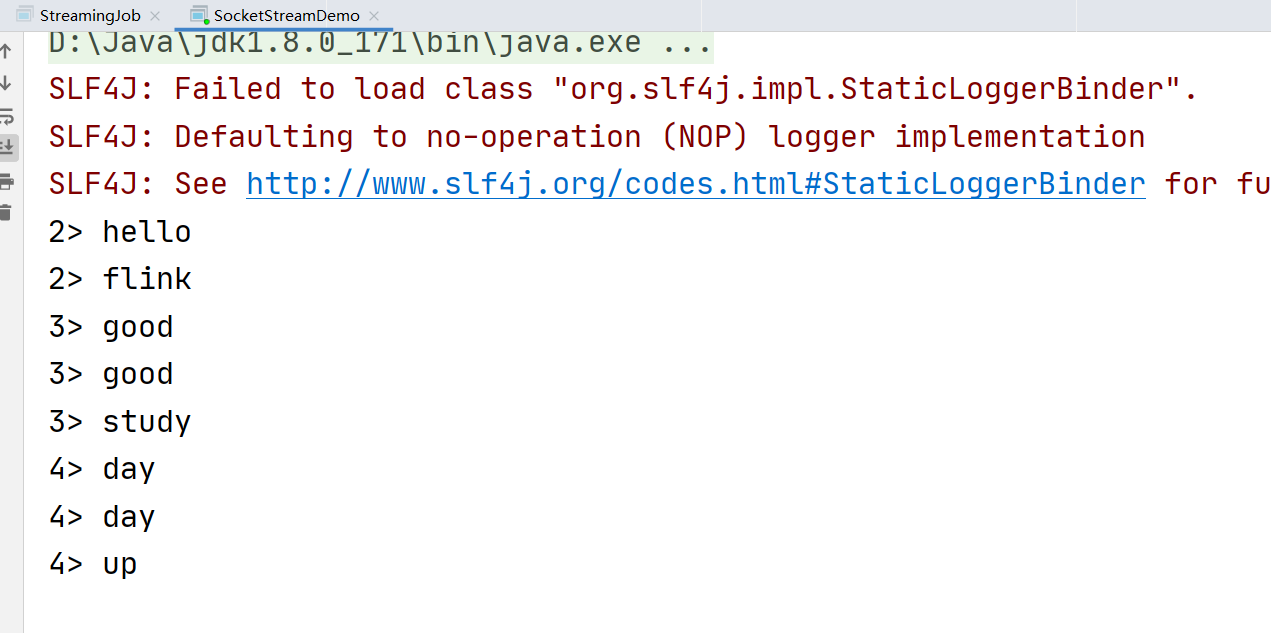
Java
4.3.2 基于文件的数据源
从文件源读取数据的源函数定义有多个,包括
●readTextFile(Stringpath):逐行读取路径指定的文本文件,即符合TextInputFormat规范的文本文件,并以字符串的形式返回。
●readFile(FileInputFormat inputFormat,String path):根据指定的文件输入格式读取(一次)文件。
●readFile(fileInputFormat,path,watchType,interval,pathFilter):这是前两种方法在内部调用的方法。它根据给定的fileInputFormat读取路径中的文件。根据所提供的watchType,此源可以定期(FileProcessingMode.PROCESS_CONTINUOUSLY,每隔interval毫秒)监视新数据的路径,或处理一次(FileProcessingMode.PROCESS_ONCE)当前路径中的数据并退出。使用pathFilter进一步排除正在处理的文件。
对于第3种方法,在底层,Flink将文件读取过程分成两个子任务,即目录监视和数据读取。每个子任务都由一个单独的实体实现。监视文件路径的子任务是由单个非并行(并行度=1)任务实现的,而文件读取则由多个并行运行的任务执行,并行度等于作业并行度。单个监视任务的作用是扫描目录(定期或仅扫描一次,这取决于watchType),查找要处理的文件,将它们划分为分段,并将这些分段分配给下游的读取器
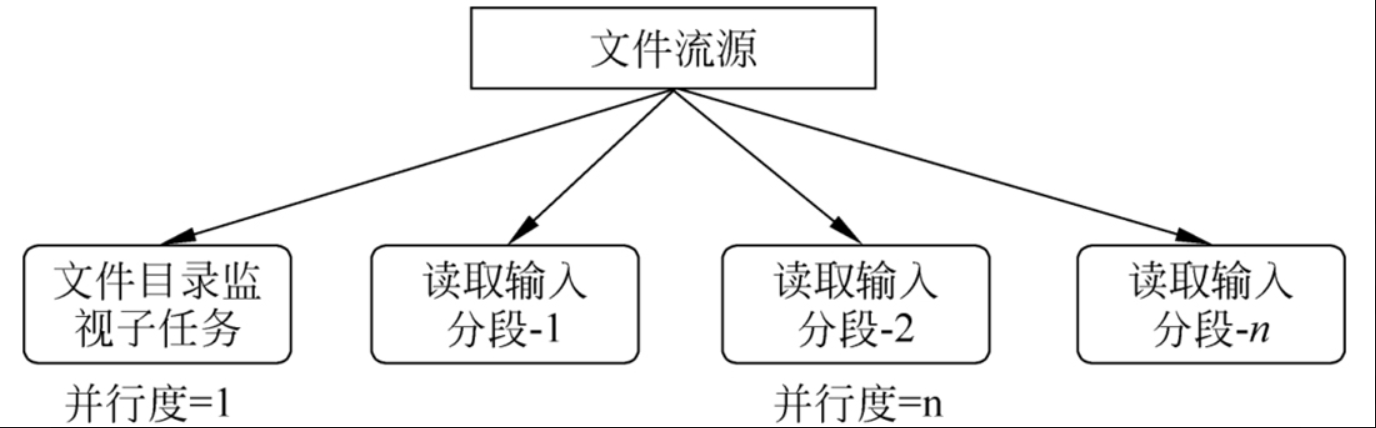
读取器将读取实际数据。每个分段只由一个读取器读取,而一个读取器可以逐个读取多个分段。
示例:编写Flink流应用程序,读取文件,并实时统计文件内的单词数量。
1在IDEA中创建Flink项目。
2在项目的src上右击,创建一个名为wc.txt的文本文件
3流处理代码实现
aScala
bJava
4.3.3 基于集合的数据源
也可以直接在内存中将一个数据集合读取为DataStream。
Flink提供了以下几种方法:
1fromCollection(Seq):从Java Java.util.collection创建一个数据流。集合中的所有元素必须具有相同的类型。
2fromCollection(Iterator):从迭代器创建数据流。该类用于指定迭代器返回的元素的数据类型。
3fromElements(elements:_ *):根据给定的对象序列创建数据流。所有对象必须具有相同的类型。
4fromParallelCollection(SplittableIterator):并行地从迭代器创建数据流。该类用于指定迭代器返回的元素的数据类型。
5generateSequence(from,to):并行地生成给定区间内的数字序列。
注意:目前,集合数据源要求数据类型和迭代器实现Serializable。此外,集合数据源不能并行执行(并行度=1)。
示例:使用集合数据源,实时找出年龄超过18岁的人员。
1在IntelliJ IDEA中创建一个Flink项目,使用flink-quickstart-scala/flink-quickstart-Java项目模板。
2打开项目中的StreamingJob对象文件,编辑流处理代码。
aScala
bJava
4.3.4 自定义数据源
对于非并行数据源,实现SourceFunction(所有流数据源的基本接口)
对于并行数据源,实现ParallelSourceFunction接口或者继承自RichParallelSourceFunction
案例:模拟信用卡交易流数据生成器
首先,创建POJO
然后,自定义数据源
最后,做一个测试类
4.4 Flink数据转换
使用操作符将一个或多个数据流转换为新的数据流
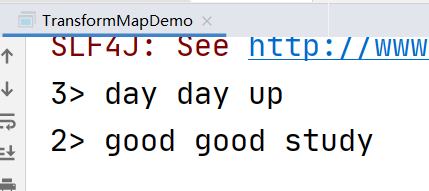
4.4.1 map转换
最简单的转换之一
4.4.2 flatMap转换
接收1条记录并输出0 或者1条或者多条记录
Scala
Java
4.4.3 filter转换
对条件进行评估,如果结果是true,则输出该条数据
Scala
java
将数据流中的数据封装到事件对象中
scala
java
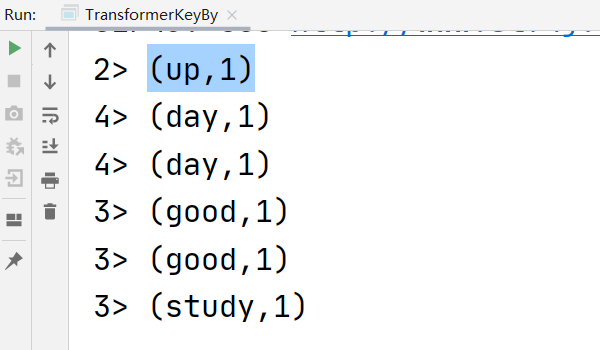
4.4.4 keyBy转换
有一些转换要求在元素集合上定义一个key,还有一些转换可以引用在按照key分组的数据上。
Flink的数据模型不是基于key-value的,不需要将数据集类型打包为key-value
scala
java
使用字段表达式来定义key,在Flink1.11版本之前可以用,从1.11之后开始弃用
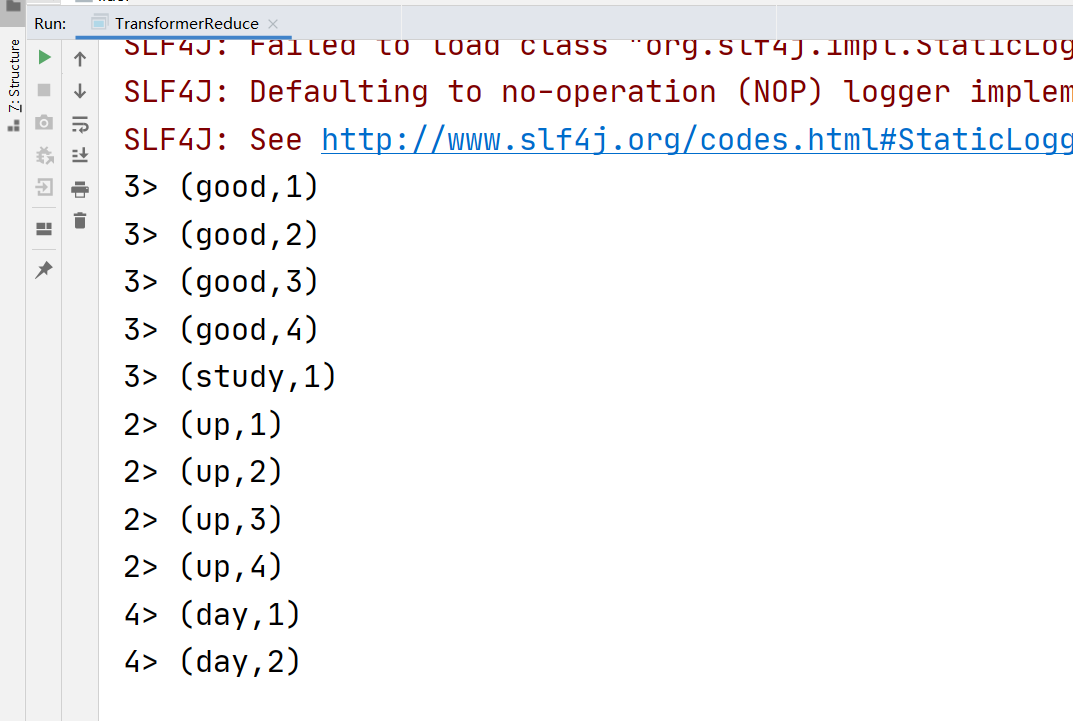
4.4.5 reduce转换
接收一个函数作为累加器,将流中的每个值从左到右开始缩减,最终计算成为一个值
scala
java
4.4.6 聚合转换
DataStream API支持各种聚合操作,如min,max,sum等。
这些聚合函数可以应用于KeyedDataStream类型的流上,以获得滚动聚合
scala
java

4.4.7 union转换
执行两个或者多个数据流的合并。

4.4.8 connect转换
合并两个数据流,合并的结果创建的是ConnectedStreams或BroadcastConnectedStreams类型的流。
不要求两个DataStream的元素是用一类型
和union的区别
1connect只能连接两个数据流,但是union可以连接多个数据流
2connect所连接的两个数据流的数据类型可以不一致,但是union所连接的两个数据流的数据类型必须一致
3两个DataStream经过connect之后被转换为ConnectedStreams,ConnectedStreams会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态
也可以分别执行两个不同的函数,那么这两个流元素输出的数据结构可以不同
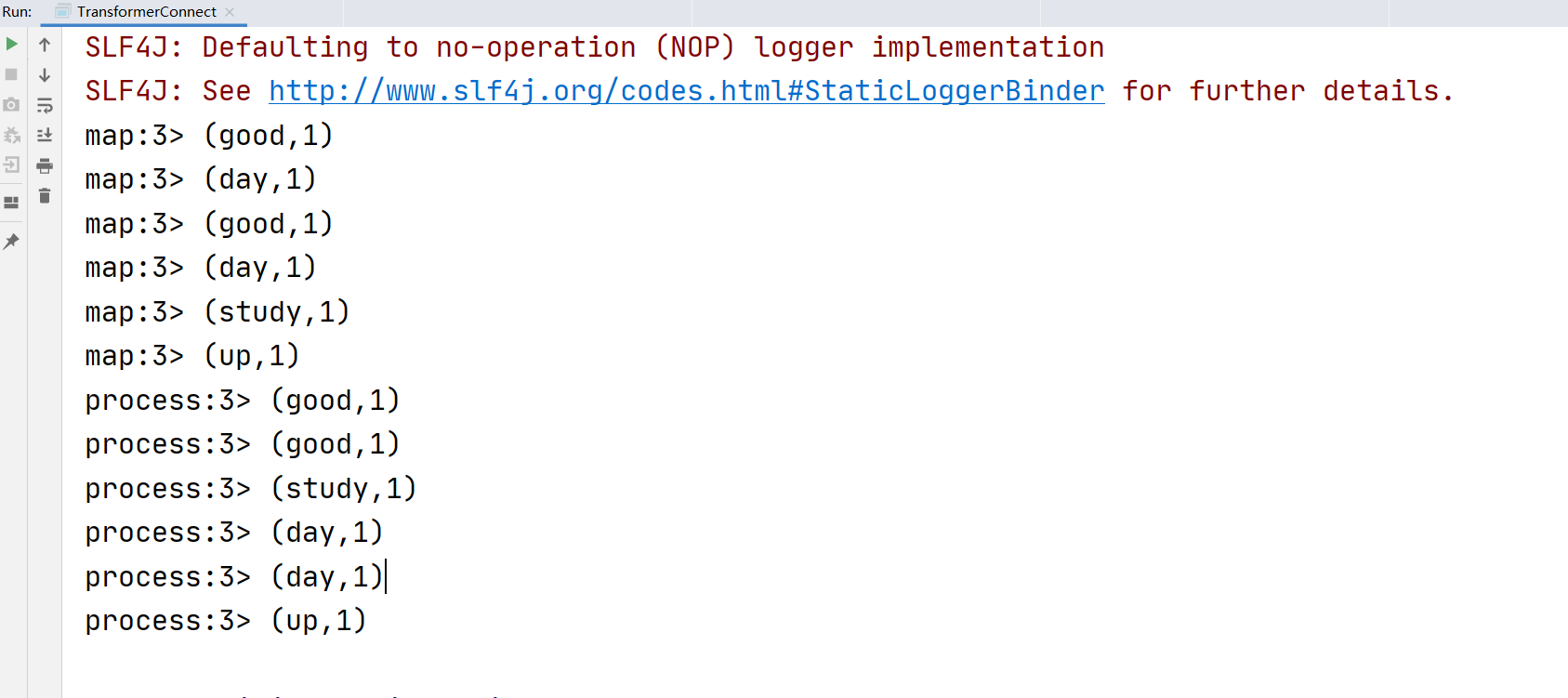
4.4.9 coMap和FlatMap转换
作用于ConnectedStreams类型的流上,功能和map、flatmap一样

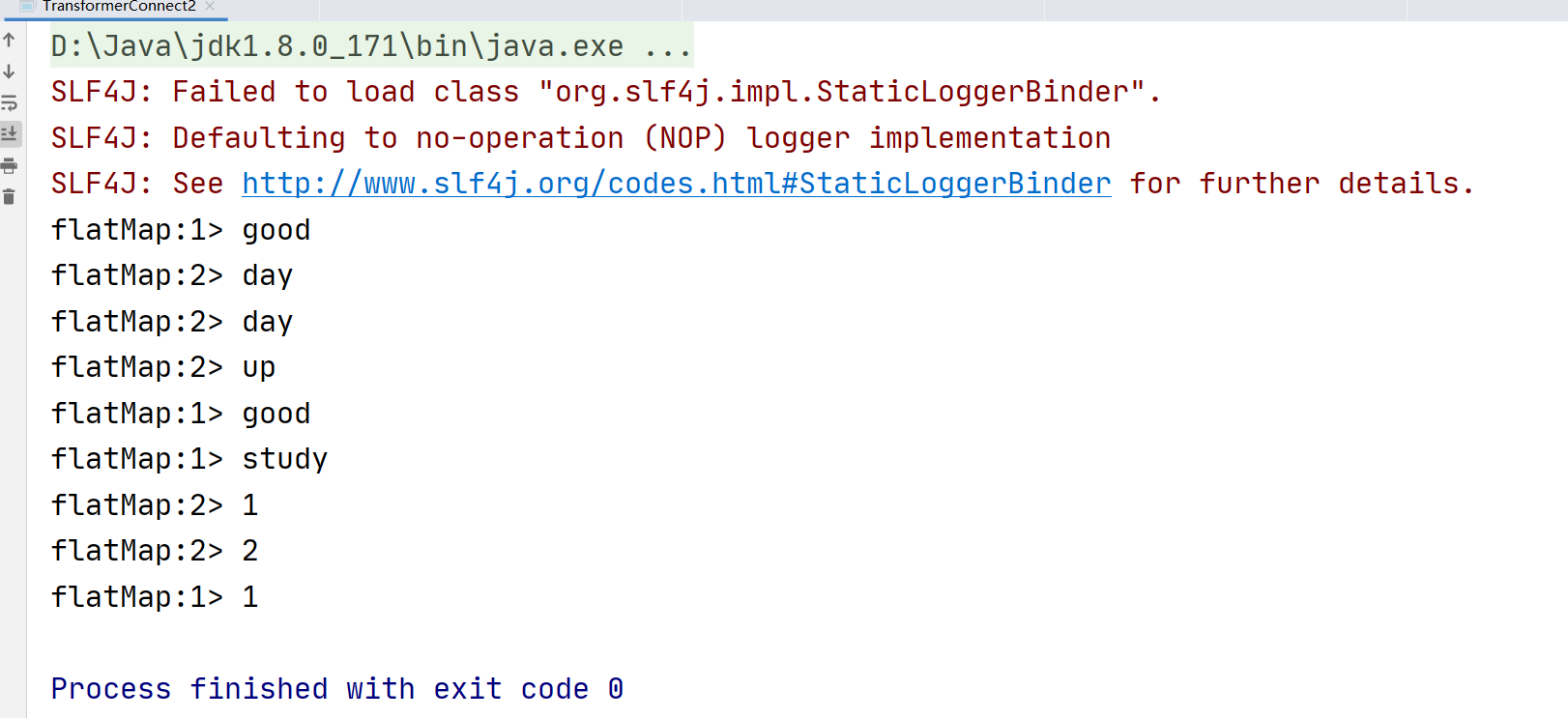
4.4.10 iterate转换
这个转换操作通过将一个算子的输出重定向到某个先前的算子在流中创建反馈循环。
案例:流程需只输出非负整数,如果遇到负整数,就会被发送回反馈通道,并不断地应用迭代体(每次都加1,直到非负为止)
这里注意一个错误
如果没有设置反馈流和原始流的并行度,会报错
Exception in thread "main" java.lang.UnsupportedOperationException: Parallelism of the feedback stream must match the parallelism of the original stream. Parallelism of original stream: 1; parallelism of feedback stream: 12. Parallelism can be modified using DataStream#setParallelism() method
原始流的平行度:1;反馈流的并行度:12。可以使用DataStream#setParallelism()方法修改并行性
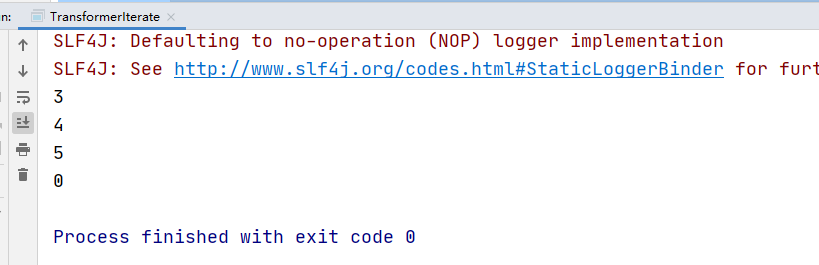
4.4.11 project转换
从事件流中选择一组属性子集,并且只将选中的元素发送到下一个处理流中。
scala不支持
Java复制代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
package org.example;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
public class BatchJob {
public static void main(String[] args) throws Exception {
// set up the batch execution environment
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
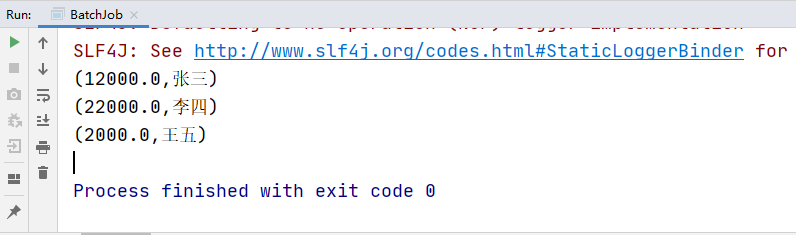
Tuple3<Integer, String, Double> user01 = new Tuple3<>(1, "张三", 12000.0);
Tuple3<Integer, String, Double> user02 = new Tuple3<>(2, "李四", 22000.0);
Tuple3<Integer, String, Double> user03 = new Tuple3<>(3, "王五", 2000.0);
DataSource<Tuple3<Integer, String, Double>> dataSource
= env.fromElements(user01, user02, user03);
//选择第3列和第2列
dataSource.project(2,1).print();
}
}
若有收获,就点个赞吧















 2796
2796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









