






决策树(Decision Tree)是一种常用的机器学习算法,用于分类和回归任务。它通过对数据集进行递归地二分,基于特征的值进行判断,从而构建一个树形结构的分类器或回归器。
原理
决策树的构建过程基本可以分为两个步骤:树的构建和树的剪枝。
-
树的构建:
- 特征选择:选择一个最优的特征来作为当前节点的分裂标准。通常使用信息增益(ID3 算法)、信息增益比(C4.5 算法)、基尼指数(CART 算法)等指标来衡量特征的优劣。
- 分裂节点:根据选择的特征将数据集分成不同的子集,每个子集对应于特征的一个取值。
- 递归构建:对每个子集递归地应用上述步骤,直到满足停止条件,如节点中样本数小于预定阈值或者树的深度达到预定值。
-
树的剪枝:
- 避免过拟合:通过剪枝来简化生成的决策树,减少过拟合风险。剪枝可以通过预剪枝(在构建时提前停止分裂)和后剪枝(构建完整树后进行剪枝)两种方式实现。
案例实现
假设我们有一个分类问题,数据集包含几种不同类型的动物,每种动物有一些特征属性,我们想根据这些特征属性来预测动物的类别(如猫、狗、鸟等)。
步骤:
决策树算法在实际应用中非常灵活,能够处理各种类型的数据,但需要注意的是,决策树容易过拟合,因此常常需要通过调整参数或者使用剪枝技术来优化模型。
-
准备数据:准备包含动物特征和类别标签的数据集。
-
构建决策树模型:
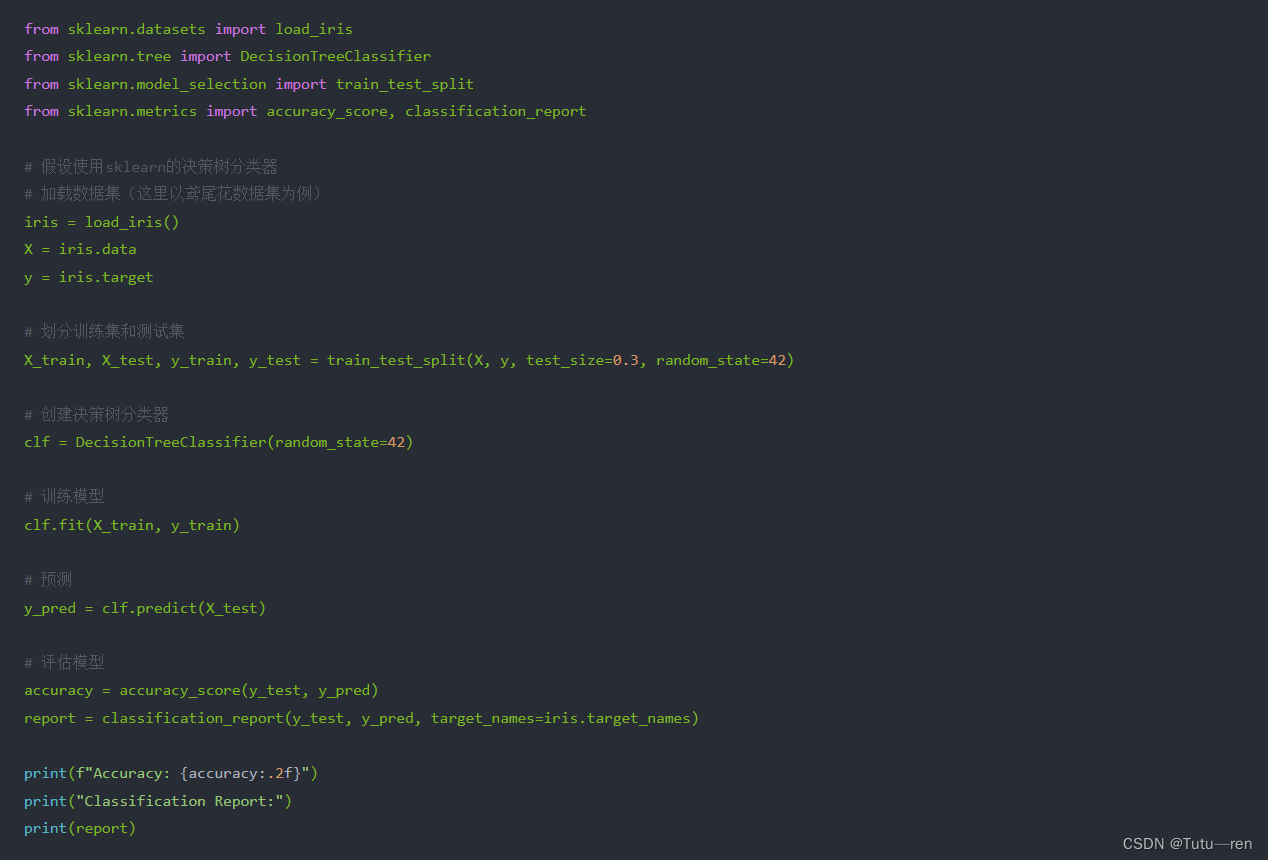
-
这段代码展示了如何使用 sklearn 库中的
DecisionTreeClassifier来构建和训练一个决策树模型,然后进行预测并评估模型的性能。 -
解释:
DecisionTreeClassifier是 sklearn 中用于实现决策树的类。fit(X_train, y_train)方法用于训练模型,其中X_train是特征数据,y_train是目标标签。predict(X_test)方法用于使用训练好的模型进行预测,其中X_test是测试集的特征数据。accuracy_score和classification_report是用来评估分类模型性能的函数,分别计算预测准确率和生成分类报告。















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









