







数据结构
数据结构
一、链表
1.链表分类
2.链表结构与实现
3.插入与删除节点,节点的交换
4.链表的销毁、复制、遍历、反转
5.判断回文链表、链表是否相交
6.链表按值排序,链表模拟加法,有序链表合并
7.链表获取节点首地址,查找特点节点位置,统计节点个数
8.快慢指针
(1)求链表中间节点
(2)找到倒数第n个节点
(3)判断链表是否有环
- 找到有环节点个数
- 找到入环节点
二、栈和队列
1.链式栈
(1)栈的定义与初始化
(2)常规操作
2.普通队列
(1)数组实现(存在假溢出)
1.实现
2.遍历
3.判断为满、为空
4.长度
(2)链表实现
1.实现
2.遍历
3.判断为空
4.长度
3.循环队列
1.实现
2.遍历
3.判断为满(rear+1%Max==Max)、为空(rear== front)
4.长度((rear-front+max)%Max)
4.优先队列(二叉堆存储结构)
1.最大优先队列
2.最小优先队列
三、字符串
字符串简称串,是一种特殊的线性表,它的数据元素仅由一个字符组成。
1.基本概念
- 长度:字符个数
- 空串:string="",长度为0
- 空格串:stringBlank=" ",仅含一个空格,长度为1
- 字串:串中任何连续字符组成
- 主串:包含子串b的串,称为b的主串
- 真子串:串的所有子串,除了自身以外
- 字串的位置:子串中第一个字符的位置
- 串相等:长度和位置相等
- 模式匹配–子串的定位运算又称为模式匹配,是求给定一个子串,要求在某个字符串中找出与该子串相同的所有子串的运算。被匹配的主串称为目标串,子串称为模式。
2.存储表示
1.顺序存储
- 基本概念:
类似于线性表的顺序存储结构,用一组地址连续的存储单元存储串值的字符序列。在串的定长顺序存储结构中,为每个串变量分配一个固定长度的存储区,即定长数组。 - 存储结构:
class SqString(object):
def __init__(self, size=0):
self.data = list(None for _ in range(size))
#分配空间(定长)
self.max_size = size
self.length = 0
def assign(self, str):
# 将字符串常量赋值为串s, 即生成一个值等于cstr的串
for i, item in enumerate(str):
self.data[i] = item
self.length += 1
def show_str(self):
# 将字符串输出
if self.length == 0:
raise ValueError("SqString is empty!")
for i, item in enumerate(self.data):
if item is None:
break
else:
print item,
print ""
2.堆分配存储
- 基本概念:
堆分配存储表示仍然以一组地址连续的存储单元存放串值得字符序列,但它们的存储空间是在程序执行过程中动态分配(堆分配)得到的。 - 存储结构:
- (1)开辟一块地址连续的存储空间,用于存储各串的值,该存储空间称为"堆"(也称自由存储区)
(2)另外建立一个索引表,用来存储串的名称(name),长度(length)和该串在"堆"中存储的起始地址(Start)。
(3)程序执行过程中,每产生一个串,系统就从"堆"中分配一快大小与串的长度相同的连续的空间,用于存储该串的值,并且在索引表中增加一个索引项,用于登记该串的名称、长度、和该串的起始地址。
#define MAXLEN 10
typedef struct
{
char name[MAXLEN];//串名
int length;//串长
char *Stradr;//起始地址
} LNode
3.链式存储
- 基本概念:
类似于线性表的链式存储结构,也可采用链表方式存储串值。由于串的特殊性(每个元素只有一个字符),在具体实现时,每个结点既可以存放一个字符,又可以存放多个字符。每个结点称为块,整个链表称为块链结构。 - 存储结构:
用链表存储字符串,每个结点有两个域:一个是数据域(data)和一个指针域(next)。
typedef struct node
{
char data;
struct node *next;
}LinkStrNode;
3.基本运算(顺序存储python)
python中的str是字符串的一种实现方式,str是不可变对象,一旦创建其内容和长度不变化。
python中字符串的存储方式和一体式顺序表类似,有记录表的长度等信息以及具体内容存储
(1)去除空格
str.strip():删除字符串两边的指定字符,括号的写入指定字符,默认为空格
str.lstrip(): 删除字符串左边的指定字符,括号的写入指定字符,默认空格
str.rstrip(): 删除字符串右边的指定字符,括号的写入指定字符,默认空格
(2)复制字符串
str a = b
(3)连接字符串
+:连接2个字符串注:此方法又称为 “万恶的加号”,因为使用加号连接2个字符串会调用静态函数string_concat(register PyStringObject *a ,register PyObject * b),在这个函数中会开辟一块大小是a+b的内存的和的存储单元,然后将a,b字符串拷贝进去。如果是n个字符串相连 那么会开辟n-1次内存,是非常耗费资源的。
str.join:连接2个字符串,可指定连接符号
#join
10 li=["alex","eric"]
11 s="******".join(li)
12 print(s)
(4)查找字符串
str.index 和str.find 功能相同,区别在于find()查找失败会返回-1,不会影响程序运行。一般用find!=-1或者find>-1来作为判断条件。
str.index:检测字符串中是否包含子字符串str,可指定范围。返回次数,不存在则中断报错
str.find:检测字符串中是否包含子字符串str,可指定范围
(5)比较字符串
str.cmp:比较两个对象,并根据结果返回一个整数。X< Y,返回值是负数 ,X>Y 返回的值为正数。
#python3已经没有该方法,可以用表达式(a > b) - (a < b)代替cmp(a,b)
(6)是否包含指定字符串
in | not in
>> a='hello world'
>> 'hello' in a
True
>> '123' not in a
True
(7)字符串长度
str.len
(8)字符串中字母大小写转换
S.lower() #转换为小写
S.upper() #转换为大写
S.swapcase() #大小写互换
S.capitalize() #首字母大写
(9)将字符串放入中心位置可指定长度以及位置两边字符
str.center()
>> a='hello world'
>> print(a.center(40,'*'))
**************hello world***************
ljust(width,fillchar)左对齐,右填充,默认空格
rjust(width,fillchar)右对齐,左填充,默认空格
(10)字符串统计
s.count()
(11)字符串切片
str = '0123456789′
print str[0:3] #截取第一位到第三位的字符
print str[:] #截取字符串的全部字符
print str[6:] #截取第七个字符到结尾
print str[:-3] #截取从头开始到倒数第三个字符之前
print str[2] #截取第三个字符
print str[-1] #截取倒数第一个字符
print str[::-1] #创造一个与原字符串顺序相反的字符串
print str[-3:-1] #截取倒数第三位与倒数第一位之前的字符
print str[-3:] #截取倒数第三位到结尾
print str[:-5:-3] #逆序截取,截取倒数第五位数与倒数第三位数之间
(12)分割,前中后三部分
s="al adm alex"
ret = s.partition('adm')
print(ret)
#输出元组 ('alex ', 'SB', ' alex')
(13)替换
s.replace(,)
(14)按输入字符切割
s.split("")
(15)根据换行执行分割
s.splitlines()
(16)变成标题
s.title()#每个单词首字母大写,其余小写
(17)返回指定长度的字符串,原字符串右对齐,前面填充0
s.zfill(11)# 11 : 长度
(18)格式化输出
%d :整数
%s :字符串
%f :浮点数
*x = 1.1267 %f :1.127(四舍五入) %.3f : 1.126700
(19)字符串排序
python中的字符串类型是不允许直接修改元素的。必须先把要排序的字符串放在容器里,如list。
python中list容器的sort()函数没有返回值。
s="string"
l=list(s)
l.sort()
s="".join(l)
print s 'ginrst'
xs.sort(key=len)
#根据长度排序
2.哈夫曼算法
哈夫曼压缩基本思想是将二进制代码分配给字符,用于减少编码这些符号的字符串比特数。
1.算法思想
算法的主要过程分为:构造哈夫曼编码表、转码压缩、转码解压。
-
构造哈夫曼编码表
Step1 遍历需要处理的字符串,得到每个字符出现的次数(频数)
Step2 将频数最低的两位字符作为叶子节点,左子树频数大于右子树,构造分支节点,同时将分支节点作为新的字符,频数即为子叶频数之和,进行重新排序(如图 1 中,将 “bd” 作为新字符,进行重新排序)
Step3 重复 Step1 和 Step2,直到所有字符编码完成
Step4 从树的顶端开始编码,左子树编为 0,右子树编为 1,直到树的底端
Step5 根据编码情况构造哈夫曼编码表 -
转码压缩
Step1 根据哈夫曼编码表将正文转换为 0-1 编码
Step2 每 8 位编码进行一次切割,作为 1 个字节数据写入压缩文件
Step3 文末不足 8 位则需要补 “0”,直到刚好达到 8 位编码
Step4 解码时避免补 “0” 干扰,需要将补 0 情况写入压缩文件中
Step5 将码表写入压缩文件 -
转码解压
Step1 根据补 0 情况,删减文本
Step2 读取哈夫曼编码表,作为转码对照表
Step3 读取正文文本,与转码对照表进行比对,还原信息
2.代码实现
(1)导入模块
os:使用了 os 模块的 path.splitext 函数,用于分割文件名与扩展名。
six:使用了 six 模块的 int2byte 函数,用于将数字转化为字节存入文件。
tkinter 模块:选用,使用了 tkinter 模块的 filedialog.askopenfilenames 函数,用于实现弹窗打开文件的功能 。
import os
import six
import tkinter
(2)打开文件
f = open(file_name, 'r') # file_name为文件名
file_data = check_binary(f.read())
f.close()
*纯英文文本
def check_binary(input_data):
# 检查文件编码,ASCII码超出255的字符替换为空格
output_data = ''
for word_index in range(len(input_data)):
if ord(input_data[word_index]) >= 256:
output_data += ' '
else:
output_data += input_data[word_index]
return output_data
(3)统计字符频次
统计各字符出现的频数,并保存在字典 char_freq 中
- setdefault(word, 0):创建键为 word,,初始值为 0 的对象,若字典中已存在此键,则不产生影响。
char_freq = {}
for word in file_data:
char_freq.setdefault(word, 0)
char_freq[word] += 1
(4) 编码哈夫曼树
两个重要过程:更新字符频数排序,更新字符编码
- sort_tuple(dist):传入一个字典 dist ,按照值大小顺序进行排序,并返回元组
def sort_tuple(dist):
# 传入字典,按照键大小顺序重排序
return sorted(dist.items(), key=lambda x: x[1], reverse=True)
# X[1]:字符出现频次
- get_coding_schedule(end1, end2, sort_list, code_schedule):传入排序表中频数最低的两位字符的 (键, 值) 元组、剔除传入的 end1, end2 后的字符排序列表、哈夫曼编码表,返回更新后的哈夫曼编码表
哈夫曼表构造过程解析
– 传入 end1 作为右子树,end2 作为左子树
– 分别判断 end1 和 end2 的字符长度,如果长度为 1 说明该字符是叶子节点,否则说明该字符是分支节点
– - 如果 end1 是叶子节点,则设置编码值为 “1”,如果 end2 是叶子节点,则设置编码值为 “0”
– -如果 end1 是分支节点,则根据分支节点的字符串进行遍历,为每一个子叶编码值都添加前缀字符 “1”,如果 end2 是分支节点,则根据分支节点的字符串进行遍历,为每一个子叶编码值都添加前缀字符 “0”
– 在 sort_list 中添加由 end1 和 end2 构成的分支节点信息,结点信息包含所有子叶字符,所有子叶累计频数
def get_coding_schedule(end1, end2, sort_list, code_schedule):
# 传入 末端2位字符组 频数 序列列表(剔除末端字符) 哈夫曼编码表
if len(end1[0]) == 1:
code_schedule.setdefault(end1[0], '1')
else:
for k in end1[0]:
code_schedule[k] = '1' + code_schedule[k]
if len(end2[0]) == 1:
code_schedule.setdefault(end2[0], '0')
else:
for k in end2[0]:
code_schedule[k] = '0' + code_schedule[k]
sort_list.append((end2[0] + end1[0], end1[1] + end2[1]))
return code_schedule
# 初始 字符--频数 列表
sort_list = sort_tuple(char_freq)
# 初始化哈夫曼编码表
code_schedule = {}
# 不断重排序,更新哈夫曼编码表及节点信息
for i in range(len(sort_list) - 1):
sort_list = sort_tuple(dict(sort_list))
code_schedule = get_coding_schedule(sort_list.pop(), sort_list.pop(), sort_list, code_schedule)
(5)文本转哈夫曼编码
# 文本信息转哈夫曼码
# 哈夫曼 0-1 编码转码 + 正文文本
code = ''.join(list(code_schedule.values()))
for word in file_data:
code += code_schedule[word]
# 不足 8 位补 0,记录在 code_sup 中
code_sup = 8 - len(code) % 8
code += code_sup * '0'
(6)创建压缩文件并写入信息
python 默认的存储数据以字符串形式存入,若要进行字节文件写入,需要使用二进制文件格式打开,还需要使用 six 模块下的 int2byte 函数对信息进行转码。
# 1.创建压缩文件
f = open(os.path.splitext(file_name)[0] + '.qlh', 'wb')
# 2.写入补 0 情况
f.write(six.int2byte(code_sup))
# 3.写入哈夫曼编码表(总长度+每一个编码长度+每一个编码对应的字符+转码信息)
# 3.1 码表总长度(字符个数,与指针读取定位有关,分割码表与正文)
f.write(six.int2byte(len(code_schedule)))
# 3.2 储存每一个哈夫曼编码的位长
for v in code_schedule.values():
f.write(six.int2byte(len(v)))
# 3.3 储存每一个哈夫曼编码配对字符 字符 ==> ASCII 码
for k in code_schedule.keys():
f.write(six.int2byte(ord(k)))
# 3.4 以 8 为长度单位,将 0-1 字符转为对应的十进制数,映射为 ASCII 符号,写入正文文本
for i in range(len(code) // 8):
f.write(six.int2byte(int(code[8 * i:8 + 8 * i], 2)))
# 4.关闭文件
f.flush()
f.close()
print('压缩完成', file_name, '>>', os.path.splitext(file_name)[0] + '.qlh')
(7)解压
- 补 0 情况,用于删除正文信息中末尾补充的 “0”
- 码表总长度(设为 N )
- 码表表文长度:表文长度以 1 字节形式存储在文件中,根据码表总长度向后截取N个字节即得到所有码表表文长度
- 码表表头:码表表文长度之后就是码表表文(编码对应的原字符),也是向后继续截取N个字节,每一个字节对应的 ASCII 码都对应着一个字符,将其转译作为哈夫曼编码表的表头信息
- 码表表文:根据表文长度,在码表表头之后不断搜索截取表文长度指示的位数,获取到每个表头对应的表文,写入哈夫曼编码表。
- 正文信息:所有表文读取结束后即复原了哈夫曼编码表,根据补 0 情况删除末尾的字符,剩余的文本即为原始文本信息。对于原始文本信息,每次对编码向后搜索、拼接,并与哈夫曼编码表进行匹配,若编码存在哈夫曼编码表表文中,则使用自定义函数 get_keys 进行转译得到对应的表头
def get_keys(dict, value):
# 传入字典,值,获取对应的键
for k, v in dict.items():
if v == value:
return k
import os
# 1.打开文件
f = open(file_name, 'rb')
# 2.读取信息
file_data = f.read()
f.close()
# 3.分割信息
# 3.1 获取补 0 位数
code_sup = file_data[0]
# 3.2 获取码表长度
code_schedule_length = file_data[1]
# 3.3 指针跳过 补0+码长+码符
pointer = 2 * code_schedule_length + 2
# 3.4 获取码表中每一个编码的长度
code_word_len = [file_data[2 + i] for i in range(code_schedule_length)]
# 3.5 编码表中字符长度总和,用于切割码表与正文
sum_code_word_len = sum(code_word_len) // 8 + 1 if sum(code_word_len) % 8 != 0 else sum(code_word_len) // 8
# 4.还原码表
# 4.1 码表转译
code_schedule_msg = ''
for i in range(sum_code_word_len):
code_schedule_msg += '0' * (10 - len(bin(file_data[pointer + i]))) + bin(file_data[pointer + i])[2:]
# 4.2 初始化指针
pointer = 0
# 4.3 创建码表
code_schedule = {}
for i in range(code_schedule_length):
code_word = chr(file_data[code_schedule_length + 2 + i]) # 码符
code_schedule[code_word] = code_schedule_msg[pointer:pointer + code_word_len[i]] # 码符码文匹配,还原码表
pointer += code_word_len[i]
# 5.提取正文
code = code_schedule_msg[pointer:]
pointer = 2 * code_schedule_length + 2 + sum_code_word_len
for number in file_data[pointer:]:
code += '0' * (10 - len(bin(number))) + bin(number)[2:]
# 删去补0
code = code[:-code_sup]
# 6.文本转译
pointer = 0 # 指针归零
# 初始化文本
letter = ''
# 限制最大搜索长度,提高效率
max_length = max([len(list(code_schedule.values())[i]) for i in range(len(code_schedule.values()))])
while pointer != len(code):
for i in range(max_length):
if code[pointer:pointer + i + 1] in code_schedule.values():
letter += get_keys(code_schedule, code[pointer:pointer + i + 1])
pointer += i + 1
break
# 7.创建解压文件
f = open(os.path.splitext(file_name)[0] + '.txt', 'w+')
f.write(letter)
print('解压完成', file_name, '>>', os.path.splitext(file_name)[0] + '.txt')
3.数据压缩、lzw压缩
1.lzw压缩
lzw压缩伪代码:
初始化中间寄存器 A = 0
for 每一个字符 K:
如果 AK 在 字典中:
A = AK, 进入下一次循环
否则:
**输出 A 的编码**
**把 AK 加入字典**
A = K
string = "thisisthe"
#小写(97,123),大写(65,91)
dictionary = {chr(i):i for i in range(97,123)}
last = 256
p = ""
result = []
for c in string:
pc = p+c
if pc in dictionary:
p = pc
else:
result.append(dictionary[p])
dictionary[pc] = last
last += 1
p = c
if p != '':
result.append(dictionary[p])
print(result)
2.lzw解压
伪代码如下:
// dict[A] = A 所代表的原始字符串
解码第一个字符 K,输出K
令 A = K
for 每一个字符 K:
如果 K 在 字典中:
解码输出 K
把dict[A] + dict[K][0] 作为新的value放入字典
K不在字典中:
dict[K] 必然是 dict[A] + dict[A][0]
把新的键值对加入字典
解码输出K
不论K在不在字典中,最后都有 A = K
dictionary = {i:chr(i) for i in range(97,123)}
last = 256
arr = [97, 97, 98, 256, 258, 257, 259]
result = []
p = arr.pop(0)
result.append(dictionary[p])
for c in arr:
if c in dictionary:
entry = dictionary[c]
result.append(entry)
dictionary[last] = dictionary[p] + entry[0]
last += 1
p = c
print(''.join(result))
4.正则表达式
1.规则
普通字符
| 符号 | 描述 |
|---|---|
| [abc] | 匹配[]中的任意字母 |
| [^abc] | 匹配除了[]中的任意字母 |
| [A-Z] | 匹配大写字母,[a-z]小写字母 |
| · | 匹配除换行符之外的单个字符 |
| [/s/S] | 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。 |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
特殊字符
| 符号 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘\n’ 或 ‘\r’。要匹配 $ 字符本身,请使用 $。 |
| ( ) | 标记一个子表达式的开始和结束位置。 |
| * | 匹配前面的子表达式零次或多次。 |
| + | 匹配前面的子表达式一次或多次。 |
| . | 匹配除换行符 \n 之外的任何单字符。 |
| [ | 标记一个中括号表达式的开始。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。 |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。 |
| { | 标记限定符表达式的开始。 |
| | | 指明两项之间的一个选择。 |
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。
| 符号 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。 |
| {n,} | n 是一个非负整数。至少匹配n 次。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
定位符
| 符号 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
选择
用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔
但用圆括号会有一个副作用,使相关的匹配会被缓存,此时可用 ?: 放在第一个选项前来消除这种副作用。
- exp1(?=exp2):查找 exp2 前面的 exp1。
- (?<=exp2)exp1:查找 exp2 后面的 exp1。
- exp1(?!exp2):查找后面不是 exp2 的 exp1。
- (?<!exp2)exp1:查找前面不是 exp2 的 exp1。
修饰符
| 符号 | 描述 |
|---|---|
| i | ignore - 不区分大小写,将匹配设置为不区分大小写,搜索时不区分大小写: A 和 a 没有区别。 |
| g | global - 全局匹配,查找所有的匹配项。 |
| m | multi line - 多行匹配,使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾。 |
| s | 特殊字符圆点 . 中包含换行符 \n 默认情况下的圆点 . 是 匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, . 中包含换行符 \n。 |
2.运算优先级
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?😃, (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, $, \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作 |
| 字符具有高于替换运算符的优先级,使得"m | food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m |
6.匹配原理
字符串匹配是计算机科学中最古老、研究最广泛的问题之一。一个字符串是一个定义在有限字母表∑上的字符序列。
符串匹配问题就是在一个大的字符串T中搜索某个字符串P的所有出现位置。
传统的串匹配算法可以概括为前缀搜索、后缀搜索、子串搜索。代表算法有KMP,Shift-And,Shift-Or,BM,Horspool,BNDM,BOM等。所用到的技术包括滑动窗口、位并行、自动机、后缀树等。
7.状态机
有限状态机(FSM)
- Moore:输出只和状态有关而与输入无关
- Mealy:输出不仅和状态有关而且和输入有关系
transitions开源库
transitions是一个由Python实现的轻量级的、面向对象的有限状态机框架。
官网举例:
from transitions import Machine
class Matter(object):
pass
model = Matter()
#The states argument defines the name of states
states=['solid', 'liquid', 'gas', 'plasma']
# The trigger argument defines the name of the new triggering method
transitions = [
{'trigger': 'melt', 'source': 'solid', 'dest': 'liquid' },
{'trigger': 'evaporate', 'source': 'liquid', 'dest': 'gas'},
{'trigger': 'sublimate', 'source': 'solid', 'dest': 'gas'},
{'trigger': 'ionize', 'source': 'gas', 'dest': 'plasma'}]
machine = Machine(model=model, states=states, transitions=transitions, initial='solid')
# Test
print(model.state) # solid
model.melt()
print(model.state) # liquid
model.evaporate()
print(model.state)

基类实现
class StateMachine:
def __init__(self, cfg, states, events_handler, actions_handler):
# config information for an instance
self.cfg = cfg
# define the states and the initial state
self.states = [s.lower() for s in states]
self.state = self.states[0]
# process the inputs according to current state
self.events = dict()
# actions according to current transfer
self.actions = {state: dict() for state in self.states}
# cached data for temporary use
self.records = dict()
# add events and actions
for i, state in enumerate(self.states):
self._add_event(state, events_handler[i])
for j, n_state in enumerate(self.states):
self._add_action(state, n_state, actions_handler[i][j])
def _add_event(self, state, handler):
self.events[state] = handler
def _add_action(self, cur_state, next_state, handler):
self.actions[cur_state][next_state] = handler
def run(self, inputs):
# decide the state-transfer according to the inputs
new_state, outputs = self.events[self.state](inputs, self.states, self.records, self.cfg)
# do the actions related with the transfer
self.actions[self.state][new_state](outputs, self.records, self.cfg)
# do the state transfer
self.state = new_state
return new_state
def reset(self):
self.state = self.states[0]
self.records = dict()
return
# handlers for events and actions, event_X and action_XX are all specific functions
events_handlers = [event_A, event_B]
actions_handlers = [[action_AA, action_AB],
[action_BA, action_BB]]
# define an instance of StateMachine
state_machine = StateMachine(cfg, states, events_handlers, actions_handlers)
8.BF算法、KMP算法、Sunday算法
1.BF算法(普通模式匹配算法)
(1)原理概念
BF算法是一种蛮力算法,其实现过程没有任何技巧,就是简单粗暴地拿一个串同另一个串中的字符一一比对,得到最终结果。
算法目的:确定主串中所含子串第一次出现的位置,这里的子串也称为模式串。
(2)设计思想
1.主串和模式串逐个字符进行比较
2.当出现字符不匹配(失配)时,主串的比较位置重置为起始位置的下一个字符位置,模式串的比较位置重置为起始字符。
- 回溯关系的确定:i = i - j + 1;
3.匹配成功返回主串中匹配串的起始位置,否则返回错误代码
时间复杂度:最坏情况为O(N*M)。数据量大时,效率低下
(3)实现
def BF(s1,s2,pos = 0):
i = pos
j = 0
while(i<len(s1) and j<len(s2)):
if(s1[i]==s2[j]):
i+=1
j+=1
else:
#回溯
i = i-j+1
j=0
if(j>=len(s2)):
return i-len(s2)
else:
return -1
#返回值为首次匹配串首位置,为-1则为匹配失败。
优化一下
def BF(s,p):
for i in range(len(s)-len(p)+1):
if s[i:i+len(p)] == p:
print("pos={i}")
2.KMP算法
(1)原理概念
KMP算法是一种改进的字符串匹配算法。
KMP常用于在一个文本串S内查找一个模式串P 的出现位置。
KMP 算法永不回退 txt 的指针 i,不走回头路(不会重复扫描 txt),而是借助 dp 数组中储存的信息把 pat 移到正确的位置继续匹配,时间复杂度只需 O(N),用空间换时间。
(2)设计思想
KMP的思想就是:利用已经部分匹配这个有效信息,保持i指针不回溯,通过修改j指针,让模式串尽量地移动到有效的位置。
如果字串中存在相同的字符,匹配时如何知道j的指针应该移动到哪里呢?
利用一个数组next来保存每一个字符不相同时j应该移动到的位置。
KMP算法的核心就是找到数组next。
- 当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。
S[0∼k−1]==S[j−k∼j−1]
P 的 next 数组定义为:next[i] 表示 P[0] ~ P[i] 这一个子串,使得 前k个字符恰等于后k个字符 的最大的k.(k不能取i+1)
如果失配在 P[r], 那么P[0]~P[r-1]这一段里面,前next[r-1]个字符恰好和后next[r-1]个字符相等——也就是说,我们可以拿长度为 next[r-1] 的那一段前缀,来顶替当前后缀的位置,让匹配继续下去.
(3)实现
def getNex(x):
for i in range(x,0,-1):
if p[0:i]==p[x-i+1:x+1]:#前缀等于后缀
return i
return 0
nxt = [getNex(x) for x in range(len(p))]
匹配:
def search():
tar=0
pos=0
while tar<len(s):
if s[tar]=p[pos]:#匹配均前移
tar +=1
pos +=1
elif pos:#失配,pos !=0,根据next数组移动标尺。
pos = nex[pos+1]
else:
tar +=1#p[0]失配,直接右移一位
if pos = len(p):#匹配成功,输出位置
print(tar-pos)
pos = nex[pos-1]
可以发现构建next数组时,时间复杂度为O(M**2)。进行优化
快速构建next数组,是KMP算法的精髓所在,核心思想是“P自己与自己做匹配”。
如果 P[x] 与 P[now] 一样,那最长相等前后缀的长度就可以扩展一位,很明显 next[x] = now + 1。 P[x] 与 P[now] 不一样,我们应该缩短这个now。因为两端是相同的,所以使得A的k-前缀等于B的k-后缀的最大的k就是公共前后缀的长度next[now-1]。
总结,当P[now]与P[x]不相等的时候,我们需要缩小now——把now变成next[now-1],直到P[now]=P[x]为止。P[now]=P[x]时,就可以直接向右扩展了。
def buildNxt():
nxt.append(0)#nxt[0]为0
x=1
now=0
while x<len(p):
if p[now]==p[x]:
now +=1
x +=1
nxt.append[now]
elif now:
now = nxt[now-1]
else:# now为0,已经无法再缩小
nxt.append[0]
x +=1
具体实现就是实现一个next()函数,函数本身包含了模式串的局部匹配信息。时间复杂度O(m+n)。
3.Sunday算法
(1)概念
Sunday是一个线性字符串模式匹配算法。其核心思想是:在匹配过程中,模式串并不被要求一定要按从左向右进行比较还是从右向左进行比较,它在发现不匹配时,算法能跳过尽可能多的字符以进行下一步的匹配,从而提高了匹配效率。
(2)设计思想
Sunday算法会提前记录p的组成和每种字符在p中最右出现的位置,比如 : “abcab”,每种字符在模板中的最靠右的位置为{‘a’:3, ‘b’:4, ‘c’:2}。
第一位匹配成功则右移一位;若失败则右移len(pattern)位,检查target[i+len(pattern)]这个位置的字符
*注:若target[i+len(pattern)]的字符也不在模式串中,则s[i:i+len§]必不能匹配。
在每一次的比较中,一旦出现失配,算法会去看s中在当前匹配段后一位的字符 ,找到这个字符在p中最右出现的位置,并与其对齐,如果在 p中没有对应的字符 ,则直接右移跳过整段的匹配段。
(3)实现
- 定义一个判断字符是否在p中的函数
def check(char_, p):
# 判断字符是否在串中出现
for c in p:
if char_ == c:
return True
return False
- 记录字符位置
def charpos(P):
posdict={}
for i in range(len(p)):
posdict[p[i]]=i
return posdict
首先定义一个空列表positions=[],用来记录pattern在target中出现的位置
def sunday_match(s, p):
i = 0
flag =0
pos = 0
posdict = charpos(P)
positions = []
it = len(s)
ip = len(p)
while i < (it-ip+1):
for j in range(0, ip):
if s[i+j] != p[j]:
flag = -1
pos = j
break
if flag == 0:
positions.append(i)
if flag == -1:
if not check(s[i+ip],p):#不在p串中,跳过整串
i = i+ip+1
else:#在串中,右移到最右部分
ipos = posdict[s(i+ip)]
i = i+ip-ipos
return positions
print(sunday_match(s, p))
四、树
1.基本概念
树和图一样都是非线性结构,树是n个结点的有限集合,当n=0时,称这棵树为空树。 非空树有以下特征:
- 有且仅有一个称为根的结点。
- 如果n>1, 除根结点以外其它结点可以分为m(m>0)个不相交的集合T1,T2,T3,T4,…,Tm,其中每一个集合都是一棵树。树T1, T2, T3,…,Tm称为这棵对的子树。
节点:树是由有限个元素组成的集合,每个元素都称作一个节点
(1)节点分类
- 子节点(孩子节点): 一个节点含有的子树的根节点称为该节点的子节点;
- 父节点(双亲节点):若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 堂兄弟节点:双亲在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙节点:以某节点为根的子树中任一节点都称为该节点的子孙;
边、根、路径
层数:节点 n 的层数为从根结点到该结点所经过的分支数目。 根节点的层数为零。
高度:树的高度等于树中任何节点的最大层数。
(2)树的分类
- 有序树:树的各个子树的顺序是固定的,不能随意改变顺序。
- 无序树:树的各个子树的顺序可变。
- 二叉树: 每个节点最多只能有两个子节点的树称为二叉树,二叉树是有序树,左右子树的顺序不能改变。二叉树又可以分为满二叉树和完全二叉树。
- B树
- 霍夫曼树
2.存储结构
1.双亲表示法
实现:通常用一个二维数组,在存储结点的同时也将对应节点的父节点存储进来。
特点:找父节点容易、找子节点难。

2.孩子表示法
实现:每个结点都存储在一个二维数组的第一列里面,多个子节点之间以链表方式连接,最后一个子节点的指向为NULL,数组的第二个元素指向其子节点链表的起始地址。
特点:找子节点容易,找父节点难。

3.双亲孩子表示法
实现:将双亲表示法与孩子表示法综合起来,既存储父节点的下标,又指向子节点链表。
特征:找父节点与子节点都比较方便,但相对前面两种复杂度有一定程度的提升。

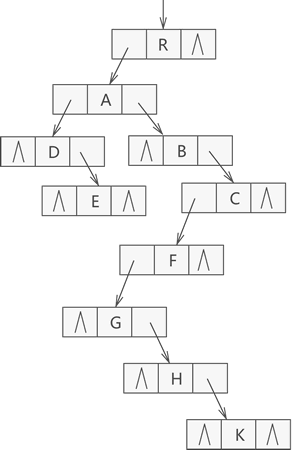
4.孩子兄弟表示(左孩子右兄弟)
每个节点一个为儿子指针,一个为兄弟指针
孩子兄弟表示法,采用的是链式存储结构,其存储树的实现思想是:从树的根节点开始,依次用链表存储各个节点的孩子节点和兄弟节点。
该链表中的节点应包含以下 3 部分内容:
1.节点的值;
2.指向孩子节点的指针;
3.指向兄弟节点的指针

如原树为
转换后为
3.二叉树
1.分类
二叉树:最多有两棵子树的树被称为二叉树
(1)完全二叉树
完全二叉树:如果一个二叉树与满二叉树前m个节点的结构相同,这样的二叉树被称为完全二叉树
(2)斜树
分为左斜树和右斜树:
左斜树:所有节点都只有左子树
右斜树:所有节点都只有右子树
(3)满二叉树
满二叉树:二叉树中所有非叶子结点的度都是2,且叶子结点都在同一层次上
2.性质
1.在二叉树的第i层上至多有2^(i-1)个节点(i≥1)
2.深度为k的二叉树,至多有2^k - 1 个节点(k≥1)
3.对任何一颗二叉树T,如果其终端节点为n0,度数为2的节点为n2,则有n0 = n2 + 1。换一句话说,就是叶子节点数-1就等于度数为2的节点数
4.具有n个节点的完全二叉树的深度为int(log2n) + 1 或者math.ceil(log2(n+1))
3.存储结构
(1)链式存储(二叉链表)
采用链式存储二叉树时,其节点结构由 3 部分构成:
- 指向左孩子节点的指针(Lchild);
- 节点存储的数据(data);
- 指向右孩子节点的指针(Rchild);

class TreeNode:
def __init__(self,data = None,left = None,right = None):
self.data = data
self.left = left
self.right = right
# 二叉树类,进行遍历操作
class Bitree:
# 初始化根
def __init__(self,root = None):
self.root = root
def is_empty(self):
if self.root is None:
return True
else:
return False
# 先序遍历
def preorder(self,node):
if node == None:
return
print(node.data,end=" ")
self.preorder(node.left)
self.preorder(node.right)
# 中序遍历
def inorder(self,node):
if node == None:
return
self.inorder(node.left)
print(node.data,end=" ")
self.inorder(node.right)
# 后序遍历
def postorder(self,node):
if node == None:
return
self.postorder(node.left)
self.postorder(node.right)
print(node.data,end=" ")
# 层次遍历
def levelorder(self,node):
qu = Queue()
qu.push(node)
while not qu.is_empte():
node = qu.pop()
print(node.data,end=" ")
if node.left:
qu.push(node.left)
if node.right:
qu.push(node.right)
if __name__ == "__main__":
# 按照后序遍历方式增加结点
b = TreeNode("B")
f = TreeNode("F")
g = TreeNode("G")
d = TreeNode("D",f,g)
i = TreeNode("I")
h = TreeNode("H")
e = TreeNode("E",i,h)
c = TreeNode("C",d,e)
a = TreeNode("A",b,c)
bt = Bitree(a)
bt.preorder(bt.root)
print()
bt.inorder(bt.root)
print()
bt.postorder(bt.root)
print()
bt.levelorder(bt.root)
print()
(2)数组存储(顺序存储)
二叉树的顺序存储,指的是使用顺序表(数组)存储二叉树。需要注意的是,顺序存储只适用于完全二叉树。
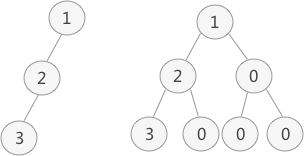
我们想顺序存储普通二叉树,需要提前将普通二叉树转化为完全二叉树。(补0)
完全二叉树的顺序存储,仅需从根节点开始,按照层次依次将树中节点存储到数组即可。
class ArrayBinaryTree(object):
def __init__(self, array):
self.array = array # 必须传入一个数组
def pre_order(self, index): # 传入要遍历数组的下标
if self.array is None or len(self.array) == 0:
print("数组为空,无法按照二叉树的前序遍历")
# 前序遍历,先输出当前元素
print(self.array[index], end=" ")
# 向左递归,先判断是否越界
if 2 * index + 1 < len(self.array):
self.pre_order(2 * index + 1)
# 向右递归,先判断是否越界
if 2 * index + 2 < len(self.array):
self.pre_order(2 * index + 2)
def in_order(self, index): # 中序遍历
if self.array is None or len(self.array) == 0:
print("数组为空,无法按照二叉树的中序遍历")
if 2 * index + 1 < len(self.array):
self.in_order(2 * index + 1)
print(self.array[index], end=" ")
if 2 * index + 2 < len(self.array):
self.in_order(2 * index + 2)
def post_order(self, index): # 后序遍历
if self.array is None or len(self.array) == 0:
print("数组为空,无法按照二叉树的后序遍历")
if 2 * index + 1 < len(self.array):
self.post_order(2 * index + 1)
if 2 * index  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









