







大数据的应用场景
各行业(移动、互联网、电力、医疗)在信息化时代,产生的数据量日益增多,如果想对这些有用的数据进行挖掘、分析,获取它的价值,传统的mysql、Oracle数据库将无法解决这一需求,因此产生了大数据,业界拥有一整套对应海量数据的存储、运算的技术体系。
大数据的核心
分布式存储与分布式运算
大数据得到学习路线和前景规划
学习路线:Linux–>—>Hadoop(mapreduce,hdfs,yarn;hive,hbase,flume,sqoop)–>spark(spark core,spark streaming,spark sql,spark grahx,sprak mllib,kafka)—>flink(新秀)—>OLAP框架(kylin,clickHouse)
Hadoop简介
核心技术
HDFS:大数据首选的的数据存储技术
mapreduce:基本已被淘汰,替代者:spark,flink
yarn:大数据中最大通用的数据调度平台
上层技术
HIve:大数据体系中数据仓库建设的首选工具
Hbase:在一些大型企业中还有不少应用
内部核心组件
分布式核心技术:利用大量的机器协同工作、实现存储(HDFS)、运算(mapreduce)资源调度系统(yarn)
外围组件

HDFS的核心设计思想
重点
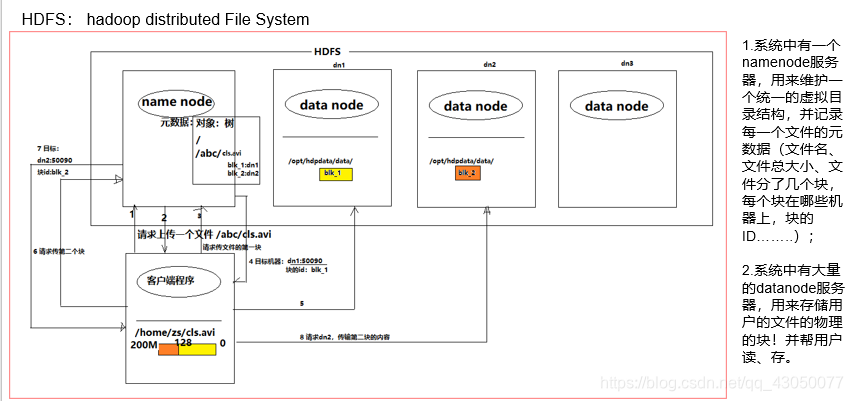
集群的搭建及常用知识点

















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









