






RNN、LSTM、GRU
-
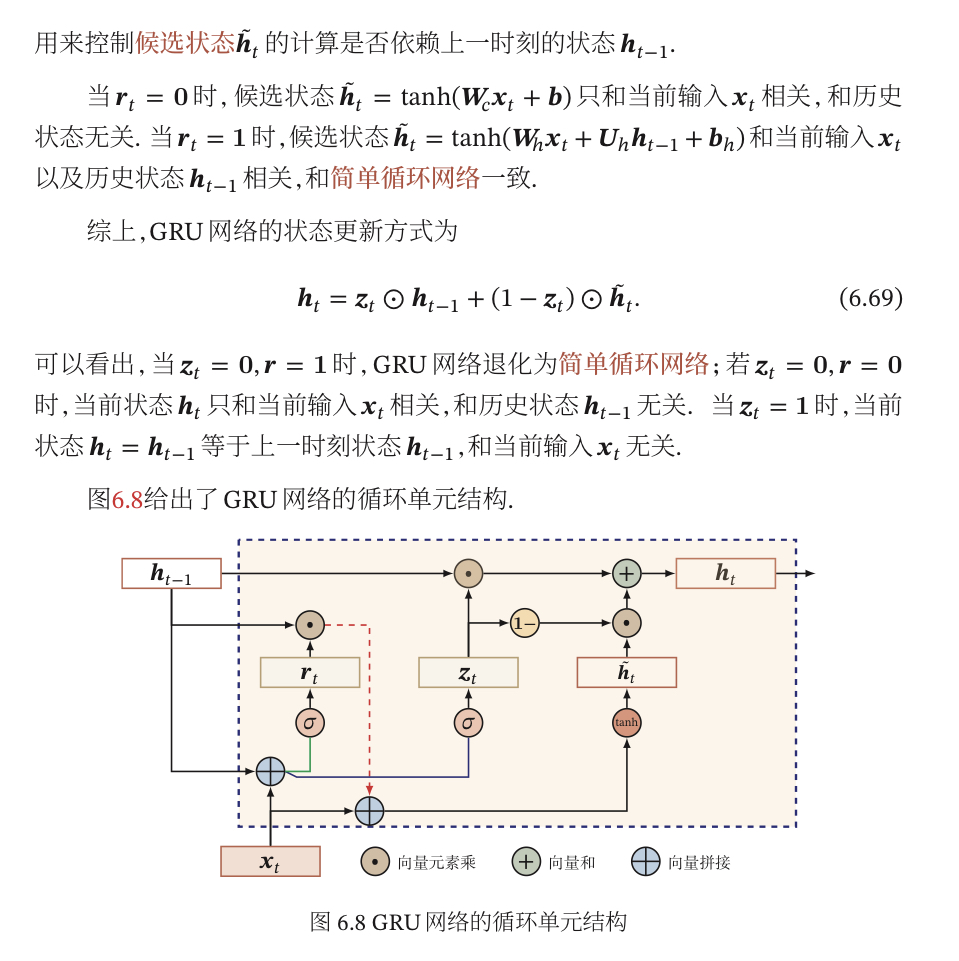
画一下GRU的单元结构?
-
介绍一下RNN、LSTM、Transformer各自的优缺点?
-
介绍一下梯度爆炸/梯度消失的解决办法?
-
RNN为什么容易出现梯度爆炸/梯度消失的问题,能否使用一些技巧缓解?
- RNN计算过程:
- 设E为损失函数,则:
- 主要关注其中一项:
- 我们已知:
- 可得:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3EJuch0A-1677248604553)(null)]


- 缓解技巧:

- 梯度裁剪:
- 按范数裁剪
- 按值裁剪

- LSTM如何解决梯度消失/爆炸?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4sIXGUho-1677248604824)(null)]

- 实践中如何解决梯度爆炸问题,超参数如何设置的?
- 设置梯度裁剪阈值时,有没有尝试通过参数分布来计算,而不是直接使用超参数?
- LSTM的图结构以及公式,以及LSTM的流程,与GRU的区别。面对长文本有什么解决办法?
- 介绍一下LSTM的原理,hidden_state和outputs的关系?
- LSTM的激活函数是什么?能否使用ReLU?
- LSTM的参数量以及初始化方式?
- LSTM里面有哪些门,为什么用这些门?



- GRU?

- RNN输入长度不一致如何处理?
- LSTM解决了RNN的什么问题?
- LSTM如何调参?
- RNN为什么用tanh不用relu?
- LSTM VS GRU?


word2vec
介绍
- word2vec有两种模型:CBOW和Skip-Gram,CBOW是在已知w的上下文的情况下,预测w,Skip-Gram是在已知w的情况下预测上下文。
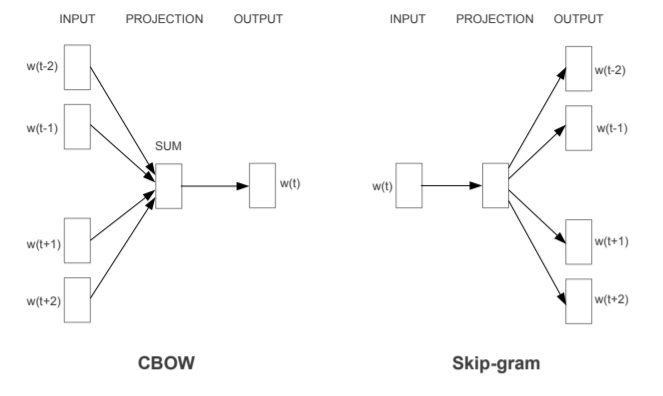
- 不经过优化的CBOW和Skip-gram中 ,在每个样本中每个词的训练过程都要遍历整个词汇表,也就是都需要经过softmax归一化,计算误差向量和梯度以更新两个词向量矩阵(这两个词向量矩阵实际上就是最终的词向量,可认为初始化不一样),当语料库规模变大、词汇表增长时,训练变得不切实际。
- 为了解决这个问题,word2vec支持两种优化方法:hierarchical softmax 和negative sampling。
- 层次softmax:首先根据词典中每个词的词频构造出一棵哈夫曼树,保证词频较大的词在浅层,词频较小的在深层,每个词都处于树的叶节点。原本的V分类问题简化为log(V)分类问题,树的每个非叶节点都进行了一次逻辑回归。这棵哈夫曼树除了根结点以外的所有非叶节点中都含有一个由参数θ确定的sigmoid函数,不同节点中的θ不一样。训练时隐藏层的向量与这个sigmoid函数进行运算,根据结果进行分类,若分类为正类则沿左子树向下传递,编码为1;若分类为正类则沿右子树向下传递,编码为0。
- 负采样:为每个训练实例都提供负例。

面试题
- Word2Vec原理,词向量是如何训练出来的?
- word2vec有两种模型:CBOW和Skip-Gram,CBOW是在已知w的上下文的情况下,预测w,Skip-Gram是在已知w的情况下预测上下文。
- Word2Vec参数量计算?
- 2xVxN
- CBOW与Skip-gram的训练过程,以及使用的加速技巧?
- 从原理的角度解释一下为什么Skip-gram效果一般比CBOW更好?
- 训练速度上 CBOW 应该会更快一点。因为每次会更新 context(w) 的词向量,而 Skip-gram 只更新核心词的词向量。两者的预测时间复杂度分别是 O(V),O(KV)
- Skip-gram 对低频词效果比 CBOW好。因为是尝试用当前词去预测上下文,当前词是低频词还是高频词没有区别。但是 CBOW 相当于是完形填空,会选择最常见或者说概率最大的词来补全,因此不太会选择低频词。Skip-gram 在大一点的数据集可以提取更多的信息。
- Word2Vec有什么缺点?
- 忽略了词序信息
- 没办法解决一词多义的现象
- 层次soft和负采样,负采样的损失函数,层次softmax的时间复杂度?
- softmax多分类的计算时间复杂度是O(V),而层次softmax的时间复杂度是O(log V),加快了计算速度
- 层次softmax的损失函数是二元交叉熵
- 负采样为什么要用词频来做采样?
- 优先学习词频高的词向量,带动低频词
- 层次softmax为什么要用哈夫曼树?其他树不可以吗?
- 因此哈夫曼树构建时是按照词频优先构建的,词频高的离根节点越近,优化高频词的计算量
- 其他树也可以,不一定要用哈夫曼树
- word2vec中目标函数为什么不用加正则化项?
- 加正则的本质是减少数据中的误差对模型的影响。word2vec中输入数据是one hot encoding没有误差所以不用加。
- Word2Vec哪个矩阵是词向量?无论是CBOW还是Skip-Gram中,都有两个权重矩阵W和W‘,W 反映的是一个词本身的词义,W’ 反映的是其他词与该词的搭配状况。上下文词向量的意思不是上下文单词的词向量,而是用来反映单词搭配状况(而非这个词的词义本身)的向量。一般来说词向量是指 W(因为用到下游任务的时候,W’ 的功能被 RNN 或其他网络结构代替了)。也有文章把 W 叫 input embedding,把 W’ 叫 output embedding。
- word2Vec的CBOW,SKIP-gram为什么有2组词向量?- 训练两组词向量是为了计算梯度的时候求导更方便。如果只用一组词向量 ,那么Softmax计算的概率公式里分母会出现一项平方项 ,那么再对 求导就会比较麻烦。相反如果用两套词向量,求导结果就会很干净。实际上,因为在窗口移动的时候,先前窗口的中心词会变成当前窗口的上下文词,先前窗口的某一个上下文词会变成当前窗口的中心词。所以这两组词向量用来训练的词对其实很相近,训练结果也会很相近。一般做法是取两组向量的平均值作为最后的词向量。

TextCNN
- TextCNN的原理和细节?
- embedding后,卷积层、最大池化层、全连接层
- TextCNN的卷积核大小,为什么要对文本进行卷积,卷积核大小选取的标准?
- TextCNN中卷积核的物理意义是什么,提取全局特征还是局部特征?
- 局部特征
- TextCNN和图像中的CNN最大的区别是什么?
- 与图像当中CNN的网络相比,textCNN 最大的不同便是在输入数据的不同:
- 图像是二维数据, 图像的卷积核是从左到右, 从上到下进行滑动来进行特征抽取。
- 自然语言是一维数据, 虽然经过word-embedding 生成了二维向量,但是对词向量做从左到右滑动来进行卷积没有意义. 比如 “今天” 对应的向量[0, 0, 0, 0, 1], 按窗口大小为 1* 2 从左到右滑动得到[0,0], [0,0], [0,0], [0, 1]这四个向量, 对应的都是"今天"这个词汇, 这种滑动没有帮助.
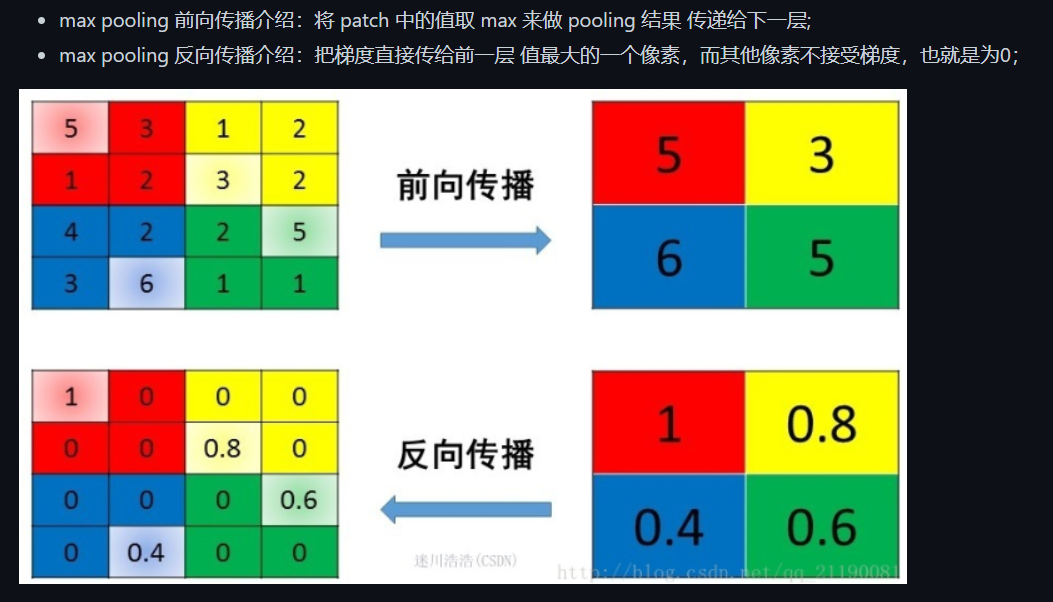
- 为什么用最大池化?
- 最大池化选取最重要的特征,平均池化获取全局上下文关系
- 若用平均池化,则相当于认为该卷积核提取到的每个n-gram的信息是同等重要的,实际上不是,我们要选取最重要的特征。
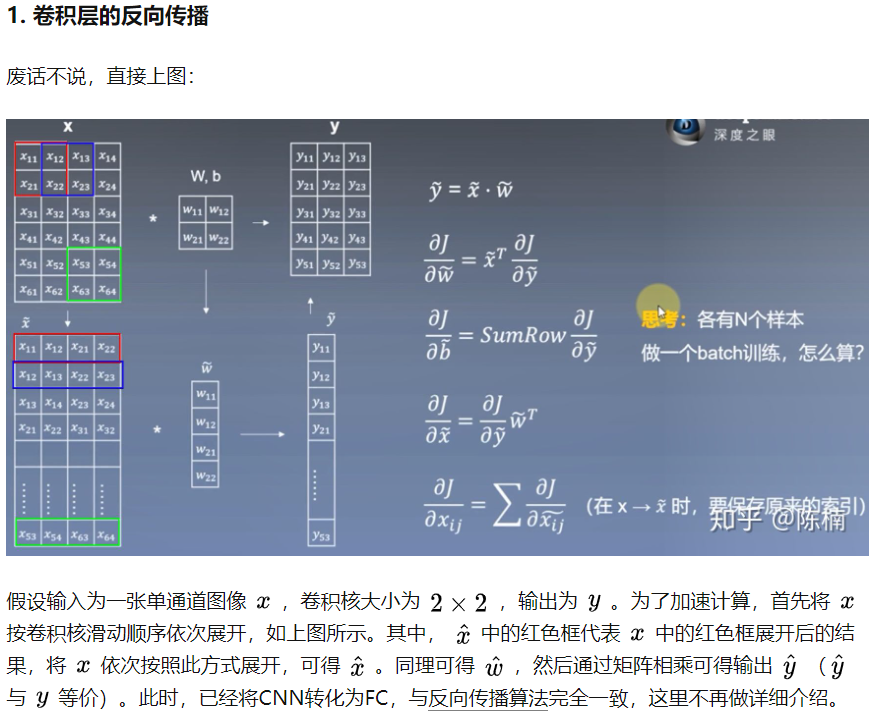
- TextCNN的反向传播?
- 卷积层
- 平均池化

- 最大池化















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









