






MongoDB 有三种集群部署模式,分别为主从复制(Master-Slaver)、副本集(Replica Set)和分片(Sharding)模式。
- Master-Slaver 是一种主从副本的模式,目前已经不推荐使用。
- Replica Set 模式取代了 Master-Slaver 模式,是一种互为主从的关系。Replica Set 将数据复制多份保存,不同服务器保存同一份数据,在出现故障时自动切换,实现故障转移,在实际生产中非常实用。
- Sharding 模式适合处理大量数据,它将数据分开存储,不同服务器保存不同的数据,所有服务器数据的总和即为整个数据集。
主从复制
主从复制是 MongoDB 中最简单的数据库同步备份的集群技术,其基本的设置方式是建立一个主节点(Primary)和一个或多个从节点(Secondary),如下图所示。
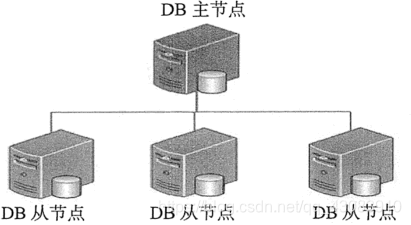
这种方式比单节点的可用性好很多,可用于备份、故障恢复、读扩展等。集群中的主从节点均运行 MongoDB 实例,完成数据的存储、查询与修改操作。
主从复制模式的集群中只能有一个主节点,主节点提供所有的增、删、查、改服务,从节点不提供任何服务,但是可以通过设置使从节点提供查询服务,这样可以减少主节点的压力。
另外,每个从节点要知道主节点的地址,主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。
在主从复制的集群中,当主节点出现故障时,只能人工介入,指定新的主节点,从节点不会自动升级为主节点。同时,在这段时间内,该集群架构只能处于只读状态。
副本集
副本集的集群架构如下图所示。
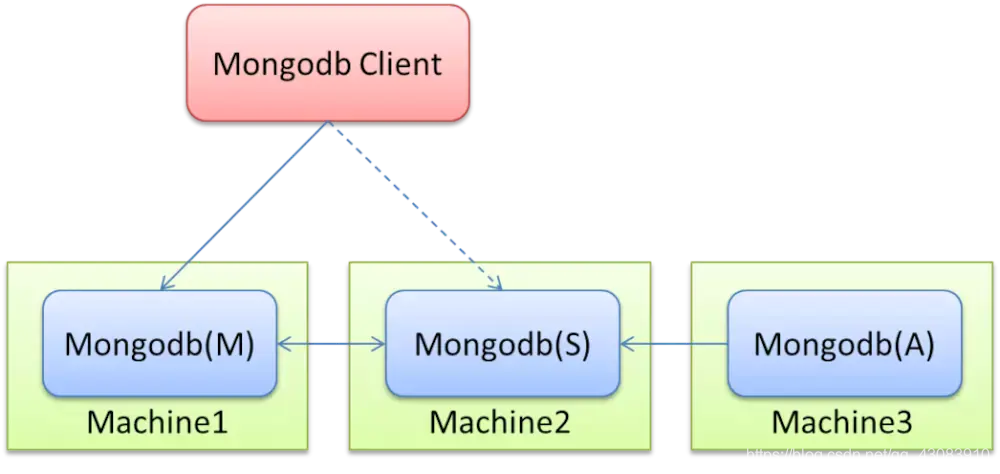
Mongodb(M)表示主节点,Mongodb(S)表示备节点,Mongodb(A)表示仲裁节点。主备节点存储数据,仲裁节点不存储数据。客户端同时连接主节点与备节点,不连接仲裁节点。
默认设置下,主节点提供所有增删查改服务,备节点不提供任何服务。但是可以通过设置使备节点提供查询服务,这样就可以减少主节点的压力,当客户端进行数据查询时,请求自动转到备节点上。这个设置叫做Read Preference Modes,同时Java客户端提供了简单的配置方式,可以不必直接对数据库进行操作。
仲裁节点是一种特殊的节点,它本身并不存储数据,主要的作用是决定哪一个备节点在主节点挂掉之后提升为主节点,所以客户端不需要连接此节点。这里虽然只有一个备节点,但是仍然需要一个仲裁节点来提升备节点级别。
相信大家看到这里是不是可以联想到redis的一种集群模式,即哨兵模式跟这个原理很像,确实如此,仲裁节点就像是一个哨兵,当监听到其它的某个节点挂了,会重新选择某个节点提升为主节点继续对外提供读写服务,从而保障集群的高可用性,减少人工干预;
MongoDB复制原理
mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
mongodb各个节点常见的搭配方式为:一主一从, 一主多从。
主节点记录其上的所有操作oplog,从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作。
副本集的特征
- N个节点的集群
- 任何节点可作为主节点
- 所有写操作都在主节点上
- 自动故障迁移
- 自动恢复
此集群拥有一个主节点和多个从节点,这一点与主从复制模式类似,且主从节点所负责的工作也类似,但是副本集与主从复制的区别在于:当集群中主节点发生故障时,副本集可以自动投票,选举出新的主节点,并引导其余的从节点连接新的主节点,而且这个过程对应用是透明的。
可以说,MongoDB 的副本集是自带故障转移功能的主从复制。
MongoDB 副本集使用的是 N 个 mongod 节点构建的具备自动容错功能、自动恢复功能的高可用方案。在副本集中,任何节点都可作为主节点,但为了维持数据一致性,只能有一个主节点。
主节点负责数据的写入和更新,并在更新数据的同时,将操作信息写入名为 oplog 的日志文件当中。主节点还负责指定其他节点为从节点,并设置从节点数据的可读性,从而让从节点来分担集群读取数据的压力。
另外,从节点会定时轮询读取 oplog 日志,根据日志内容同步更新自身的数据,保持与主节点一致。
在一些场景中,用户还可以使用副本集来扩展读性能,客户端有能力发送读写操作给不同的服务器,也可以在不同的数据中心获取不同的副本来扩展分布式应用的能力。
在副本集中还有一个额外的仲裁节点(不需要使用专用的硬件设备),负责在主节点发生故障时,参与选举新节点作为主节点。
副本集中的各节点会通过心跳信息来检测各自的健康状况,当主节点出现故障时,多个从节点会触发一次新的选举操作,并选举其中一个作为新的主节点。为了保证选举票数不同,副本集的节点数保持为奇数。
下面我们在三台虚拟机上模式搭建一下mongodb的这种副本集模式的集群;
1、环境准备,我这里提前准备好了三台虚拟机,
192.168.111.134
192.168.9.147
192.168.111.133
2、上传mongodb的安装包
我这里放在 /usr/local 目录下, tar -zxvf mongodb-linux-x86_64-4.0.9.tgz
 3、为使用方便,将解压后的文件命名为mongodb
3、为使用方便,将解压后的文件命名为mongodb
mv mongodb-linux-x86_64-4.0.9 mongodb
4、创建相关目录
mkdir data
mkdir logs
mkdir conf
cd logs
touch master.log
cd conf
touch mongodb.conf
5、创建配置文件
进入conf目录,创建mongodb.conf,并编辑
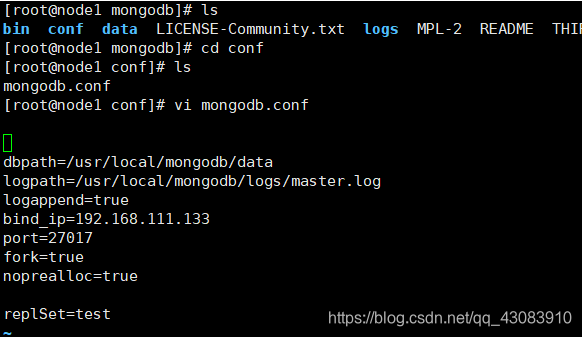
6、以上是在主节点做的操作,在另外的两个节点上做同样的配置即可,只需要修改端口号和相应的目录文件地址,下面帖上配置文件
#master配置
dbpath=/usr/local/mongodb/data
logpath=/usr/local/mongodb/logs/master.log
logappend=true
bind_ip=192.168.111.133
port=27017
fork=true
noprealloc=true
replSet=test
#slave配置
dbpath=/usr/local/mongodb/data
logpath=/usr/local/mongodb/logs/slave.log
logappend=true
bind_ip=192.168.9.147
port=27017
fork=true
noprealloc=true
replSet=test
#仲裁节点配置
dbpath=/usr/local/mongodb/data
logpath=/usr/local/mongodb/logs/arbite.log
logappend=true
bind_ip=192.168.111.134
port=27018
fork=true
noprealloc=true
replSet=test
7、做完了上述的配置基本上就可以了,下面我们就来启动集群
进入三个节点的bin目录下,执行,看到如下信息就表示启动成功了,三个节点做同样的启动操作,
/usr/local/mongodb/bin/mongod -f /usr/local/mongodb/conf/mongodb.conf

8.配置主、备、仲裁节点
#连接到节点
./mongo 192.168.111.133:27017
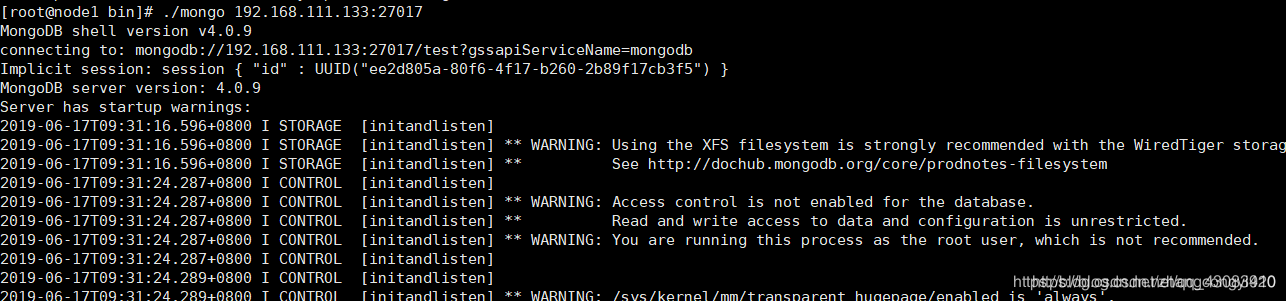
忽略启动的警告信息,没有报错就是连接上了客户端,
初始化并建立三个节点之间的信息,使用如下命令,大家修改为自己机器的IP
cfg={ _id:“test”, members:[ {_id:0,host:‘192.168.111.133:27017’,priority:2}, {_id:1,host:‘192.168.9.147:27017’,priority:1}, {_id:2,host:‘192.168.111.134:27018’,arbiterOnly:true}] };
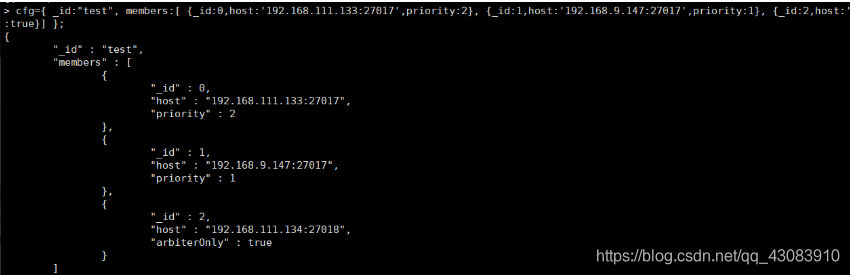
可以看到,各个节点的基本信息已经展示出来了,接着执行,
rs.initiate(cfg);
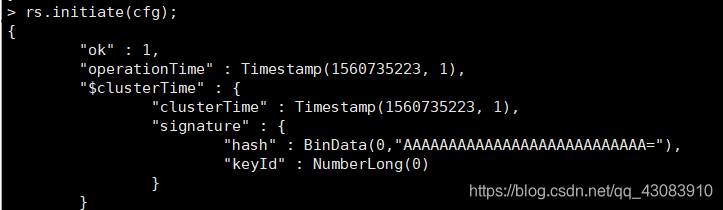
最后,执行rs.status();查看集群的状态
{
"set" : "test",
"date" : ISODate("2019-06-17T01:34:05.135Z"),
"myState" : 2,
"term" : NumberLong(0),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"appliedOpTime" : {
"ts" : Timestamp(1560735223, 1),
"t" : NumberLong(-1)
},
"durableOpTime" : {
"ts" : Timestamp(1560735223, 1),
"t" : NumberLong(-1)
}
},
"lastStableCheckpointTimestamp" : Timestamp(0, 0),
"members" : [
{
"_id" : 0,
"name" : "192.168.111.133:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 169,
"optime" : {
"ts" : Timestamp(1560735223, 1),
"t" : NumberLong(-1)
},
"optimeDate" : ISODate("2019-06-17T01:33:43Z"),
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "could not find member to sync from",
"configVersion" : 1,
"self" : true,
"lastHeartbeatMessage" : ""
},
{
"_id" : 1,
"name" : "192.168.9.147:27017",
"health" : 1,
"state" : 0,
"stateStr" : "STARTUP",
"uptime" : 21,
"optime" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"optimeDurable" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"optimeDurableDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2019-06-17T01:34:04.957Z"),
"lastHeartbeatRecv" : ISODate("1970-01-01T00:00:00Z"),
"pingMs" : NumberLong(5),
"lastHeartbeatMessage" : "",
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"configVersion" : -2
},
{
"_id" : 2,
"name" : "192.168.111.134:27018",
"health" : 1,
"state" : 0,
"stateStr" : "STARTUP",
"uptime" : 21,
"lastHeartbeat" : ISODate("2019-06-17T01:34:04.794Z"),
"lastHeartbeatRecv" : ISODate("1970-01-01T00:00:00Z"),
"pingMs" : NumberLong(4),
"lastHeartbeatMessage" : "",
"syncingTo" : "",
"syncSourceHost" : "",
"syncSourceId" : -1,
"infoMessage" : "",
"configVersion" : -2
}
],
"ok" : 1,
"operationTime" : Timestamp(1560735223, 1),
"$clusterTime" : {
"clusterTime" : Timestamp(1560735223, 1),
"signature" : {
"hash" : BinData(0,"AAAAAAAAAAAAAAAAAAAAAAAAAAA="),
"keyId" : NumberLong(0)
}
}
}
各个节点的状态比如节点的健康状况,是否主节点等都可以清楚的看出来
分片
相关概念
在搭建集群之前,需要首先了解几个概念:路由,分片、副本集、配置服务器等。
- mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
- config server,顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,防止数据丢失!
- shard,分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。
- replica set,中文翻译副本集,其实就是shard的备份,防止shard挂掉之后数据丢失。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
- 仲裁者(Arbiter),是复制集中的一个MongoDB实例,它并不保存数据。仲裁节点使用最小的资源并且不要求硬件设备,不能将Arbiter部署在同一个数据集节点中,可以部署在其他应用服务器或者监视服务器中,也可部署在单独的虚拟机中。为了确保复制集中有奇数的投票成员(包括primary),需要添加仲裁节点做为投票,否则primary不能运行时不会自动切换primary。
简单了解之后,我们可以这样总结一下,应用请求mongos来操作mongodb的增删改查,配置服务器存储数据库元信息,并且和mongos做同步,数据最终存入在shard(分片)上,为了防止数据丢失同步在副本集中存储了一份,仲裁在数据存储到分片的时候决定存储到哪个节点。
分片架构说明
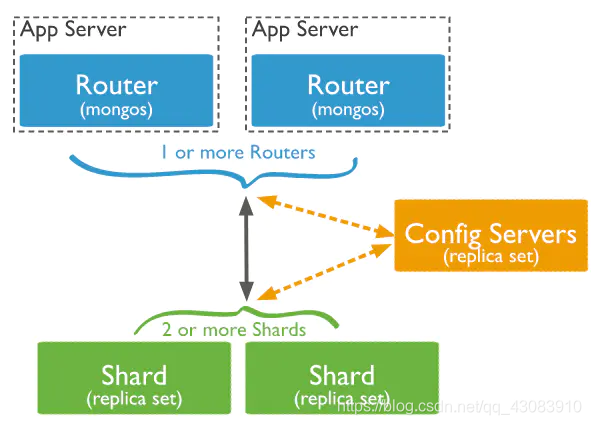
更详细点可以看作为:
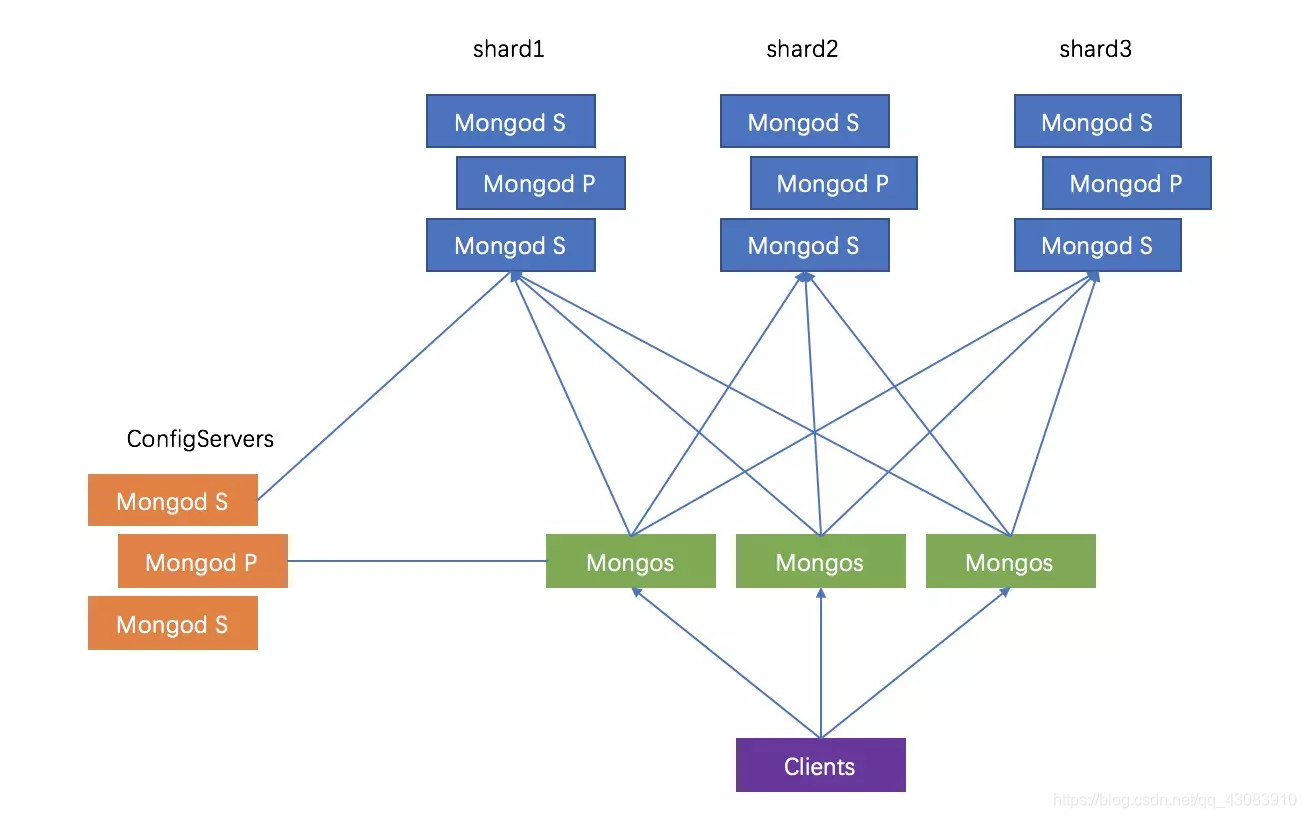
我上面建立的这个集群一共使用了8台物理服务器。最左边三台物理服务器中,每台物理服务器里放一个config(mongod)进程,和一个mongos进程。三个config节点组成config副本集,这样任意一个config挂掉都不会对整体造成影响。三个mongos采用相同的配置,在连接mongoDB集群的时候,将URL写成
mongodb://username:password@192.168.1.1:2000,192.168.1.2:2000,192.168.1.3:2000/DatabaseName
这种模式,由客户端自动的在3个mongos中选择一个连接,并在一个mongos出故障时由客户端自动迁移到另一个mongos上去。这样就不怕某个mongos突然挂掉。
下面的操作使用的MongoDB版本为4.0以上
然后是上面三台物理服务器每个里面都运行着一个mongod进程,用来存放真实的业务数据,这三个服务器的mongod均设置为Master,并且分属不同的分片,加载不同内容的配置文件。
然后我们就有了3个分片了,然后我们再为每个分片设置副本集,组成一个3x3的集群,即3个分片,每个分片里有3个数据副本,防止数据丢失。
于是在同一个机房或者同城机房内在找一台算力和存储都比Master大一些的两台物理机,每台物理机里执行三个mongod进程,分别数据分片1,分片2和分片3的Slave。这样三分片三复制集的集群就搭建完成了。下面是详细步骤
搭建Config节点复制集
config节点有一个就够用了,但是为了实现高可用,我这里使用3台物理机跑三个config节点,并组成复制集。
config节点的配置文件如下
sharding:
clusterRole: configsvr
replication:
replSetName: confset
net:
port: 7017
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/conf/mongod.log
storage:
dbPath: /mnt/mongo/conf
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/conf/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
跑mongod进程很方便,只需编写好一个简短的配置文件就可以了,这也是mongodb比mysql方便的地方,即配置文件结构非常简单,不需要考虑太多。
其中要注意,clusterRole必须填configsvr,这一点与普通的mongod数据库进程不一样。因为config节点虽然也可以当做普通的mongo数据来使用,但是其最主要的作用不是存储业务数据,而是与mongos进程配合,存储每个分片节点的信息,数据分片规则,和分片后每个chunk的存储信息。所以不应该在config节点中存储任何业务数据。
replSetName可以自己随便起,但在三个config节点中应该保持相同,这样才能把三个config节点添加到同一个复制集中去
port就是开放的端口,注意和其他的进程不冲突就可以了,我这里三台config节点的配置文件都是一样的,用的一样的数据库端口。
systemLog就是配置mongo运行时产生log日志的存放位置,storage里的dbPath就是存放数据库数据文件的位置,如果目录不存在需要手工创建。
在这里要提醒一下,默认搭建出来的mongo数据库集群是没有管理员密码的,连接也不需要提供用户名和密码,非常不安全。所以我们这里先使用mongodb集群密码验证的方式生成相关的密钥。
生成密钥使用openssl命令即可,如果数据库服务器本身没有openssl命令,可以在其他设备上生成后拷贝过来
openssl rand -base64 741 > /etc/mongo/mongodb-keyfile
生成的密钥大概是下面这个样子,懒得生成的同学可以直接把我下面这个拷贝过去使用
bJd/FkxJaYfZPL5bbP7eRI2sh8EydhuZa8jXUtzlT+uYz0oKHKhnMBECsX+CZfRG
xebslFdXrWdAuhwVvSoFDGtp9o7O9kwJbna0txKxhFfeYcDh5X81hQT7TbflY1oH
JVgCFMrfejz9vR5bMa5ieumhDJ0WruvO3y1fvOVZN4/SDkWahxY88mF40GTambGw
q6VeIV4aEPOrqDUu7TqTzuaCGZBRd6EQoWGqQ/bsmq8Q37hag8Pdk1dFE0jyUvsA
ol00lIFN+49OkTcO/t20/MUae+opcIn8sUtV7a80WyiklH9AxIRR6Xjl/Peb+vbg
gsyq2XK3LFqga/WWDY16AYGBBGn53oCxjkmDH+HZ5VL2IlAoEELUIYHKpSiafUCg
/fsVloVJh7niZaOsBrsd7ltK3SDeK2BNdtSGFLdRR80CzmYn+CAmcW87pxlhTopQ
iqmHbkAL6AwLyDUkuqVjQCExYNT5jOv2UqHwq758m1PRZJrfikBM3m/oiF1j+R7c
i8sqz2qHYKyc4C2l3bRM27IIpayJB976CK4a9TOI/qunNLLNlWGcKlJOvHSDbHEN
mvFP5AekkL1rhmPLdk8GQdWTPXe52qTHsH10T9okF59r0qnqx3AXsuOTw/AR1r5d
qq3ERE/xB/y2mrXVRmkygel6UKwA7q5UjVQt6w0JubnhKWWtb4xVUbvSgHC/M9jY
MaVx6B9O4Ga2ENrAGkH/8iRXiR7BlMR9DZeE+QG1vaz35c/Gj74EbqnGrmyCnlNV
T+J1ovhPg6q0L4UsPCWoaXCz2d4HOBNr6Tr3sd7L0wB3UdWINXA3kMUqOiUSLpt/
2VbnETSdLoNWtezzT09SY4wn+N5yvHbZt+ugwB1i62FvNQLx3IIq9sJqIPvR8R3W
HlhxiYTWQp9IaKxIuITOZ+eL+ybmym4jGHErfheRFnNq9ywnJt/ZiGoiPB3xWYZl
4qmi9ZRb38MMNI/8wnwVKm5lWYM4
把密钥文件放到相关目录后,还需要修改密钥文件的权限,否则mongod进程会启动失败
chown mongod:mongod /etc/mongo/mongodb-keyfile
chmod 600 /etc/mongo/mongodb-keyfile
然后我们在配置文件上加入下面这几行,就可以开启mongodb集群的密码功能了。注意这个mongodb-keyfile要保存好,之后所有分片,复制集的mongod进程都要使用同一个mongodb-keyfile才能建立集群。
然后我们在三个物理服务器上建立相同的目录,主要是数据库数据存储目录,pid文件目录,log文件目录,然后把密钥文件mongodb-keyfile和mongod配置文件在三台服务器上都拷贝一个,就可以准备启动了。
假设我们mongod的配置文件为/etc/mongo/config.conf,那么在三台config节点服务器上都运行
mongod --config /etc/mongo/config.conf
启动三个config节点,然后我们使用mongo命令任意连接其中一个节点,初始化配置三个config节点为一个复制集
rs.initiate(
{
_id: "confset",
configsvr: true,
members: [
{ _id : 0, host : "192.168.1.1:7017" },
{ _id : 1, host : "192.168.1.2:7017" },
{ _id : 2, host : "192.168.1.3:7017" }
]
}
)
上面的_id就是前面配置文件中replSetName你起的名字,在三个config节点的配置文件中是相同的,这里rs.initiate的命令只需在一个config节点中执行即可,其他两个节点会自动添加进来,无需每个节点都执行一遍。但前提是你必须在防火墙上打开你设置的监听端口,上文中是7017,保证三个节点可以互相通信
这样,由三个mongod组成的复制集集群就建设好了,此时推荐建立root用户,这样在开启了密码之后,我们就可以方便的对config节点登录和修改配置。
此时要注意添加root用户的时机,要在复制集初始化之后,密钥配置之前配置。因为如果还没有初始化集群,那么创建用户命令就只对一个节点生效,需要创建三遍,而如果创建的不一致还会导致复制集的问题,所以要先初始化集群。初始化之后如果配置文件中带着上面讲的keyFile: /etc/mongo/mongodb-keyfile来启动,那么启动之后仍然没有权限创建新用户,恰当的时机就是一开始不写keyFile: /etc/mongo/mongodb-keyfile这两行到配置文件中去,然后初始化集群,创建root用户,然后把mongod全部kill掉再在配置文件中加入这两行后重启mongod
db.createUser(
{
user: "root",
pwd: "passwd",
roles: [ { role: "root", db: "admin" } ]
}
)
官网的文档只给了role为userAdminAnyDatabase的用户,但是这个用户的权限并不大,不能修改集群内的配置,所以还是需要root role。
建立一个分片节点并组成副本集
有了config节点之后,下一步就需要建立分片节点,而且为了保证一个分片里数据库挂掉之后数据不丢失,还需要给每个分片建立一个复制集组成集群里的集群,这样不仅有了多个数据副本,还可以实现读写分离。
首先我们在Shard 1 Master这台服务器上建立第一个分片的主节点。同样我们先建立数据库数据存储目录,pid文件目录,log文件目录,然后把密钥文件mongodb-keyfile拷贝到/etc/mongo/下,或者其他的什么位置,然后开始编写mongod的配置文件
sharding:
clusterRole: shardsvr
replication:
replSetName: shard1
net:
port: 17017
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/shard1/mongod.log
storage:
dbPath: /mnt/mongo/shard1
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/shard1/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/mongo/mongodb-keyfile
此时clusterRole:要改成shardsvr,这样才能和config节点,mongos节点一起组成分片集群。replSetName可以随便填一个,但是对于分片一和它的几个副本都应该是相同的名字。分片一和分片二两个副本集的replSetName一般为不一样的,和config节点的集群也应该不一样。
然后我们就可以启动master了,一般使用mongod用户启动
mongod --config /etc/mongo/shard1Master.conf
然后我们去另外两台放Slave节点的服务器,编写slave节点的配置文件,而且别忘了建立数据库数据存储目录,pid文件目录,log文件目录,然后把密钥文件mongodb-keyfile拷贝到/etc/mongo/下。
sharding:
clusterRole: shardsvr
replication:
replSetName: shard1
net:
port: 17017
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/shard1/mongod.log
storage:
dbPath: /mnt/mongo/shard1
journal:
enabled: true
wiredTiger:
engineConfig:
cacheSizeGB: 4
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/shard1/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/mongo/mongodb-keyfile
这里要注意,repSetName要和Master节点填一样的。在我的集群里,由于有两台服务器是存放了三个分片的slave节点。而在mongodb的内存使用规则中,使用LRU方式,一个mongod进程最多可以使用50%的物理内存,所以三个节点可分配的内存就是150%的物理内存,这样最后肯定会触发OOM,所以在slave节点的配置文件中,要加上上面的cacheSizeGB,限定最大使用的内存数量,我这里使用的4GB,我的物理服务器大约有24GB的物理内存。
这里顺便提一下mongodb的内存管理,从MongoDB 3.2版本开始,就开始使用WiredTiger作为默认的存储引擎,下面摘自mongodb的官方document
Starting in MongoDB 3.4, the default WiredTiger internal cache size is the larger of either:
50% of (RAM - 1 GB), or
256 MB.
For example, on a system with a total of 4GB of RAM the WiredTiger cache will use 1.5GB of RAM (0.5 * (4GB - 1 GB) = 1.5 GB). Conversely, a system with a total of 1.25 GB of RAM will allocate 256 MB to the WiredTiger cache because that is more than half of the total RAM minus one gigabyte (0.5 * (1.25 GB - 1GB) = 128 MB < 256 MB).
在实际应用中,发现这个存储引擎特别的牛逼,比如我插入10GB的数据,只要数据量没有超过上面的内存限制,即总物理内存-1的一半,那么数据再保存在磁盘的同时,还会保存在内存中,如果你的数据库本身不大而物理内存特别大的话,那此时你已经有了一个内存型数据库,所有的查询在内存中就可以完成,这样的扫描速度往往是磁盘的上千倍。性能还是非常恐怖的。
官网文档还明确的指出,在一个服务器有多个mongod进程或者容器中运行时,需要设定cacheSizeGB这个参数,原文如下
NOTE
The storage.wiredTiger.engineConfig.cacheSizeGB limits the size of the WiredTiger internal cache. The operating system will use the available free memory for filesystem cache, which allows the compressed MongoDB data files to stay in memory. In addition, the operating system will use any free RAM to buffer file system blocks and file system cache.
To accommodate the additional consumers of RAM, you may have to decrease WiredTiger internal cache size.
The default WiredTiger internal cache size value assumes that there is a single mongod instance per machine. If a single machine contains multiple MongoDB instances, then you should decrease the setting to accommodate the other mongod instances.
If you run mongod in a container (e.g. lxc, cgroups, Docker, etc.) that does not have access to all of the RAM available in a system, you must set storage.wiredTiger.engineConfig.cacheSizeGB to a value less than the amount of RAM available in the container. The exact amount depends on the other processes running in the container.
然后我们启动Master节点的mongod,然后启动两个slave节点的mongod,然后使用mongo命令连接master节点,来把这三个mongod节点配置成一主两备的单一分片集群
rs.initiate(
{
_id : "shard1",
members: [
{ _id : 0, host : "192.168.1.4:17017" },
{ _id : 1, host : "192.168.1.5:17017" },
{ _id : 2, host : "192.168.1.6:17017" }
]
}
)
上面的是最简单的配置方式,mongodb自己会决定哪个节点是master,哪些是salve,priority默认为0,priority越大越有可能成为master,但是你也可用通过传参数来手工指定priority,并且在节点数多于2的时候可以选择一个节点不存储数据只做仲裁。也就是三副本模式可以改成两副本+仲裁模式,如下
rs.initiate(
{
_id : "shard1",
members: [
{ _id : 0, host : "192.168.1.4:17017" ,priority : 2 },
{ _id : 1, host : "192.168.1.5:17017" ,priority : 1 },
{ _id : 2, host : "192.168.1.6:17017" ,arbiterOnly :true }
]
}
)
然后,为了能在集群之后还能登陆进节点修改数据库配置,我们要添加一个root用户,注意添加用户的时机应该是集群初始化之后,keyFile: /etc/mongo/mongodb-keyfile写在配置文件之前。等创建完root之后再把keyFile: /etc/mongo/mongodb-keyfile写入进配置文件重启。
db.createUser(
{
user: "root",
pwd: "root",
roles: [ { role: "root", db: "admin" } ]
}
)
创建第二个分片的集群和第三个分片的集群也大同小异,下面光把配置文件贴出来
shard 2 master 配置文件:
sharding:
clusterRole: shardsvr
replication:
replSetName: shard2
net:
port: 27017
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/shard2/mongod.log
storage:
dbPath: /mnt/mongo/shard2
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/shard2/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/mongo/mongodb-keyfile
shard 2 两个slave节点配置文件
sharding:
clusterRole: shardsvr
replication:
replSetName: shard2
net:
port: 27017
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/shard2/mongod.log
storage:
dbPath: /mnt/mongo/shard2
journal:
enabled: true
wiredTiger:
engineConfig:
cacheSizeGB: 4
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/shard2/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/mongo/mongodb-keyfile
初始化shard2 复制集的命令
rs.initiate(
{
_id : "shard2",
members: [
{ _id : 0, host : "192.168.1.7:27017" },
{ _id : 1, host : "192.168.1.5:27017" },
{ _id : 2, host : "192.168.1.6:27017" }
]
}
)
shard3 master 配置文件:
sharding:
clusterRole: shardsvr
replication:
replSetName: shard3
net:
port: 37017
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/shard3/mongod.log
storage:
dbPath: /mnt/mongo/shard3
journal:
enabled: true
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/shard3/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/mongo/mongodb-keyfile
shard3 两个slave节点配置文件
sharding:
clusterRole: shardsvr
replication:
replSetName: shard3
net:
port: 37017
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/shard3/mongod.log
storage:
dbPath: /mnt/mongo/shard3
journal:
enabled: true
wiredTiger:
engineConfig:
cacheSizeGB: 4
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/shard3/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/mongo/mongodb-keyfile
初始化分片3复制集的命令
rs.initiate(
{
_id : "shard3",
members: [
{ _id : 0, host : "192.168.1.8:37017" },
{ _id : 1, host : "192.168.1.5:37017" },
{ _id : 2, host : "192.168.1.6:37017" }
]
}
)
注意三个分片mongod一般采用不同的接口这样不容易出错。
然后分别在shard2 和shard3创建root用户,一遍以后登录调试。
现在3个分片,9个配置文件,9个mongod进程已经都启动起来了,现在可以开始把这3个分片+config节点集群配置成一个大集群了。
首先我们编写mongos的配置文件,这个配置比起mysql的路由网关配置简单太多了,因为mongodb的mongos配置基本全是启动之后在里面配置,不用提前写进配置文件,这一点比mycat要方便很多,修改参数无需重启mongos了。
sharding:
configDB: confset/192.168.1.1:7017,192.168.1.2:7017,192.168.1.3:7017
net:
port: 2000
bindIp: 0.0.0.0
systemLog:
destination: file
logAppend: true
path: /mnt/mongo/mongos/mongod.log
processManagement:
fork: true # fork and run in background
pidFilePath: /mnt/mongo/mongos/mongod.pid # location of pidfile
timeZoneInfo: /usr/share/zoneinfo
security:
keyFile: /etc/mongo/mongodb-keyfile
同样的,我们需要建立日志目录,需要keyfile密钥文件,但是无需建立数据存储目录了,因为mongos不会存储任何数据,只做路由转发,而片键和chunk存储的位置等信息都记录在config节点上。
在配置文件中需要指明config集群中所有节点的IP和端口,并且保证网络畅通。然后使用mongos命令启动
mongos --config /etc/mongo/mongos.conf
启动一个或者多个mongos之后,使用mongo命令连接任何一个mongos,并且建立好root用户。注意此处可以先不加keyfile把整个集群创建完成,root用户建完,然后再每个节点修改配置文件加入keyfile,再把整个集群的所有节点重启一遍。
db.createUser(
{
user: "root",
pwd: "root",
roles: [ { role: "root", db: "admin" } ]
}
)
然后使用root用户登录,把三个分片都添加进去,每个分片添加里面的一个节点即可,master和slave都行,因为复制集里任何一个节点都是可以的。
sh.addShard( "shard1/192.168.1.4:17017")
sh.addShard( "shard2/192.168.1.7:27017")
sh.addShard( "shard3/192.168.1.8:37017")
至此,我们的3x3集群,既包含复制集又包含分片的集群就搭建完成了,下一步就是选择片键,然后对collection进行切分,这又是一个很大的话题。
使用如下bash命令即可接入mongos进行配置
mongo --port 2000 -u root -p password --authenticationDatabase admin
建立好集群之后,使用root用户登录,然后就可以使用
rs.status()
命令来来查看集群中有哪些分片和数据库了。
注意mongos只需配置一遍,另外两个mongos只需按照配置文件启动起来即可,因为mongos会调取config节点提供的信息。
客户端连接数据库的时候,可以选择任意一个mongos连接,或者只选择一个,之用URL这种方式连接。URL方式连接的好处就是对于多种语言的驱动程序都能良好的支持,通用性比较高,因为用到mongo的场合很多,nodejs,python和JAVA都会经常调用,如果每种语言写一套连接方式那就太麻烦了。
下面是我常用的一种URL
mongodb://username:password@192.168.1.1:2000,192.168.1.2:2000,192.168.1.3:2000/数据库名?authSource=admin&readPreference=secondary&maxStalenessSeconds=120&connectTimeoutMS=300000
同时写明了用户名密码,三个mongos地址,数据库名,用户验证库,读写分离,超时时间等。在python,java,node均有很好的支持。














 2172
2172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









