







1.vector(向量)(底层是数组)
向量没有确定数据类型所以向量可以是多种数据类型,但是注意一个向量对象只能有一种数据类型,可以构造二维向量(二维数组)比如二维整型向量vector ,但值得注意的是二维向量的大元素和小元素(行元素和最小元素)都是一个向量可以不分配大小而是通过数据的规模分配大小
这里介绍整型向量的常用方法函数(其他类型的可以自行通过转换类型达到相同的效果):
vector a(10); //定义了10个整型元素的向量
vector a(10,1); //定义了10个整型元素的向量,且给出每个元素的初值为1
vector a(b); //用b向量来创建a向量,整体复制性赋值
vector a(b.begin(),b.begin+3); //定义了a值为b中第0个到第2个(共3个)元素
a.assign(b.begin(), b.begin()+3); //b为向量,将b的0~2个元素构成的向量赋给a
a.assign(4,2); //是a只含4个元素,且每个元素为2
a.back(); //返回a的最后一个元素
a.front(); //返回a的第一个元素
a.clear(); //清空a中的元素
a.empty(); //判断a是否为空,空则返回ture,不空则返回false
a.pop_back(); //删除a向量的最后一个元素
a.erase(a.begin()+1,a.begin()+3); //删除a中第1个(从第0个算起)到第2个元素
a.push_back(5); //在a的最后一个向量后插入一个元素,其值为5
a.insert(a.begin()+1,5); //在a的第1个元素(从第0个算起)的位置插入数值5
a.insert(a.begin()+1,3,5); //在a的第1个元素(从第0个算起)的位置插入3个数,其值都为5
a.size(); //返回a中元素的个数;
a.capacity(); //返回a在内存中总共可以容纳的元素个数
a.swap(b); //b为向量,将a中的元素和b中的元素进行整体性交换
vector的find函数是一个比较特殊的函数他的返回值必须用迭代器接收
迭代器即为一个存储某个值在向量中的地址 整型迭代器的定义方式:vector::iterator 可以接收vector的元素的地址
vector的find函数: vector::iterator it; it=find(a.begin(),a.end(),int) 其中a为vector的对象
此时为查找a开头到结尾是否有这个值,如果没有就会返回a.end().
用vector动态创建二维数组
template <typename Container>
void Show(Container &con)
{
Container::iterator it = con.begin();
for(; it != con.end();++it)
{
cout<<*it<<" ";
}
cout<<endl;
}
template <typename Container>
bool Del_Container1(Container &con,int val)
{
if(con.empty())
{
return false ;
}
Container::iterator it = con.begin();
for( it ; it != con.end();)
{
if(*it == val)
{
it = con.erase(it);
}
else
{
++it;
}
}
return true;
}
template <typename Container>
bool Del_Container2(Container &con,int val)
{
Container::iterator it = con.begin();
int count = 0 ;
sort(con.begin(),con.end());
for( it ; it != con.end();++it)
{
if(*it == val)
{
break;
}
}
//排序后,用pos标记要删的数字的第一个位置;
Container:: iterator pos = it;
//从标记位开始找要删数字的个数
for(it = pos ; it != con.end();++it)
{
if(*it == val)
{
count++;
}
}
//it指向要删数字区间的最后一个;
it = pos+3;
//留出一个数字 删除后面的区间内的所有元素
con.erase(pos+1,it);
return true ;
}
template <typename Container>
bool Del_Container3(Container &con,int val)
{
if(con.empty())
return false;
sort(con.begin(),con.end());
Container::iterator it = unique(con.begin(),con.end());
//unique(begin.end),表示一定区间,通过相邻比较删除重复的元素,但是不会真正的删除,而是会放到尾地址后面
//unique函数会将重复出现的数字放在容器的末尾并返回第一个重复的数字的迭代器
//再用erase函数擦除从指向的元素到最后的元素
con.erase(it,con.end());
return true;
}
int main()
{
int row;
cin>>row;
int col;
cin>>col;
vector<vector<int>> array(row);
for(int i = 0 ; i < row ; ++i)
{
array[i].resize(col);
}
for(int i = 0 ; i < row ;++i)
{
for(int j = 0 ; j < col ;++j)
{
cin>>array[i][j];
}
}
int arr[] = {1,2,3,4,2,6,2,2,2,3,3,3,3,7,8,2};
int len = sizeof(arr)/sizeof(arr[0]);
vector<int> vec(arr,arr+len);
cout<<"删除前vector中的元素"<<" ";
Show(vec);
Del_Container1(vec,2);
cout<<"删除后vector中的元素"<<" ";
Show(vec);
return 0;
}
Vector是同一种类型的对象的集合,每个对象都有一个对应的整数索引值。Vector的数据安排及操作方式与array非常相似,唯一的差别在于array是静态空间,一旦配置了就不能改变;vector是动态空间,随着元素的加入,它的内部机制会自行扩充空间以容纳新元素。
使用vector之前,必须包含相应的头文件和命名空间:
使用vector之前,必须包含相应的头文件和命名空间:
也可以采用万能头文件
#include <vector>
using std::vector
vector不是一种数据类型,而只是一个类模版,可以用来定义多种数据类型。在定义了vector对象之后,vector类型的每一种都指定了其保存元素的类型。例如:使用的vector和vector都是数据类型。
- vector对象的定义及初始化
vector<type> vec1; / v1保存类型为type的对象,默认构造函数,v1为空
vector<type> vec2(size); / v2含有值初始化的元素的size个副本
vector<type> vec3(size,value); / v3包含值为value的size个元素
vector<type> vec4(myvector); / v4是myvector的一个副本
vector<type> vec5(first,last); / 用迭代器first和last之间的元素创建v5
- vector与Array的转换
v.empty():如果v为空,则返回true,否则返回false。
v.size():返回v中元素的个数。
v.push_back(t):在v的末尾增加一个值为t的元素。
v[n]:返回v中位置为n的元素。
v1=v2:把v1的元素替换成v2中元素的副本。
v1==v2:如果v1与v2相等,则返回true。
!=, <, <=, >, >=:保持这些操作符惯有的含义。
- 容器的容器与2维数组
因为容器受容器元素类型的约束,所以可定义元素是容器类型的容器。例如,可以定义 vector 类型的容器 lines,其元素为 string 类型的 vector 对象:
vector< vector<string> > lines;
/这里需要特别说明的是C++11中已经不在使用两个空格隔开相邻的>符号
声明容器的容器,必须用空格隔开两个相邻的 > 符号,以示这是两个分开的符号,否则,系统会认为 >> 是单个符号,为右移操作符,并导致编译时错误。
vector<vector<int> > mat(3, vector<int>(4));
mat含有3个元素,每个元素是含有4个int值的向量,mat.size()是3 ,即3行。这个用法即相当于一个2维数组。
- vector元素的常用操作
这里我们以vector c;为例进行说明。
容器的大小操作
- c.max_size():返回向量类型的最大容量(2^30-1=0x3FFFFFFF)
- c.capacity():返回向量当前开辟的空间大小(<= max_size,与向量的动态内存分配策略相关)。
- c.size():返回向量中现有元素的个数(<=capacity)。
- c.resize(n):调整向量的长度使其能容纳n个元素。
- c.resize(n,x):把向量的大小改为n,所有新元素的初值赋为x。
- c.empty():如果向量为空,返回真。
元素的赋值操作
c.assign(first,last):将迭代器first,last所指定范围内的元素复制到c 中。
c.assign(num,val):用val的num份副本重新设置c。
元素的访问操作
c.at(n):等价于下标运算符[],返回向量中位置n的元素,因其有越界检查,故比[ ]索引访问安全。
c.front():返回向量中第一个元素的引用。
c.back():返回向量中最后一个元素的引用。
c.begin():返回向量中第一个元素的迭代器。
c.end():返回向量中最后一个元素的下一个位置的迭代器,仅作结束游标,不可解引用。
c.rbegin():返回一个反向迭代器,该迭代器指向容器的最后一个元素。
c.rend():返回一个反向迭代器,该迭代器指向容器第一个元素前面的位置。
元素的删除操作
c.pop_back():删除向量最后一个元素。
c.clear():删除向量中所有元素。
c.erase(iter):删除迭代器iter所指向的元素,返回一个迭代器指向被删除元素后面的元素。
c.erase(start, end):删除迭代器start、end所指定范围内的元素,返回一个迭代器指向被删除元素段后面的元素。
元素的插入操作
c.push_back(x):把x插入到向量的尾部。
c.insert(iter, x):在迭代器iter指向的元素之前插入值为x的新元素,返回指向新插入元素的迭代器。
c.insert(iter,n,x):在迭代器iter指向的元素之前插入n个值为x的新元素,返回void。
c.insert(iter,start,end):把迭代器start和end所指定的范围内的所有元素插入到迭代器iter所指向的元素之前,返回void。
元素的交换操作
c.reverse():反转元素顺序。
c.swap(c2):交换2个向量的内容,c和c2 的类型必须相同。
- 顺序访问vector的几种方式
1、向向量a中添加元素
vector<int> a;
for(int i=0;i<10;i++)
a.push_back(i);
2、也可以从数组中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector<int> b;
for(int i=1;i<=4;i++)
b.push_back(a[i]);
3、也可以从现有向量中选择元素向向量中添加
int a[6]={1,2,3,4,5,6};
vector<int> b;
vector<int> c(a,a+4);
for(vector<int>::iterator it=c.begin();it<c.end();it++)
b.push_back(*it);
- 从向量中读取元素
1、通过下标方式读取
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(int i=0;i<=b.size()-1;i++)
cout<<b[i]<<" ";
2、通过遍历器方式读取
int a[6]={1,2,3,4,5,6};
vector<int> b(a,a+4);
for(vector<int>::iterator it=b.begin();it!=b.end();it++)
cout<<*it<<" ";
- 几种重要的算法
使用时需要包含头文件:#include<algorithm>
(1)sort(a.begin(),a.end()); //对a中的从a.begin()(包括它)到a.end()(不包括它)的元素进行从小到大排列
(2)reverse(a.begin(),a.end()); //对a中的从a.begin()(包括它)到a.end()(不包括它)的元素倒置,但不排列,如a中元素为1,3,2,4,倒置后为4,2,3,1
(3)copy(a.begin(),a.end(),b.begin()+1); //把a中的从a.begin()(包括它)到a.end()(不包括它)的元素复制到b中,从b.begin()+1的位置(包括它)开始复制,覆盖掉原有元素
(4)find(a.begin(),a.end(),10); //在a中的从a.begin()(包括它)到a.end()(不包括它)的元素中查找10,若存在返回其在向量中的位置
2.string(字符串)
字符串也能根据其值的大小来自动分配空间,相当于字符数组但是不需要提前分配空间
string 可用+直接连接字符串
这里介绍string的常用函数:
string str; //定义了一个空字符串str
str = “Hello world”; // 给str赋值为"Hello world"
string s1(str); //调用复制构造函数生成s1,s1为str的复制品
cout<<s1<<endl;
string s2(str,6); //将str内,开始于位置6的部分当作s2的初值
string s3(str,6,3); //将str内,开始于6且长度顶多为3的部分作为s3的初值
string s4(cstr); //将C字符串作为s4的初值
string s6(5,‘A’); //生成一个字符串,包含5个’A’字符
string s7(str.begin(),str.begin()+5); //区间str.begin()和str.begin()+5内的字符作为初
int capacity()const; //返回当前容量(即string中不必增加内存即可存放的元素个数)
int size(); //返回当前字符串的大小
int length(); //返回当前字符串的长度
bool empty(); //当前字符串是否为空
find 函数一般用string::size_type这个迭代器接收
find( const basic_string &str, size_type index );
//返回str在字符串中第一次出现的位置(从index开始查找),如果没找到则返回string::npos
find( const char *str, size_type index ); // 同上
find( const char *str, size_type index, size_type length );
//返回str在字符串中第一次出现的位置(从index开始查找,长度为length),如果没找到就返回string::npos npos可以看作一个int的值
size_type find( char ch, size_type index );
// 返回字符ch在字符串中第一次出现的位置(从index开始查找),如果没找到就返回string::npos
string &insert(int p,const string &s); //在p位置插入字符串s
string &replace(int p, int n,const char *s); //删除从p开始的n个字符,然后在p处插入串s
erase的三种用法(上闭下开):
(1)erase(pos,n); 删除从pos开始的n个字符,比如erase(0,1)就是删除第一个字符
(2)erase(position);删除position处的一个字符(position是个string类型的迭代器)
(3)erase(first,last);删除从first到last之间的字符(first和last都是迭代器)
string substr(int pos ,int n ) ; //返回pos开始的n个字符组成的字符串
void swap(string &s2); //交换当前字符串与s2的值
string &append(const char *s); //把字符串s连接到当前字符串结尾
void push_back(char c) //当前字符串尾部加一个字符c
transform(str.begin(),str.end(),str.begin(),::tolower)//将从头到尾的字符全部小写
transfom(str.begin(),str.end(),str.begin(),::toupper)//将从头到尾的字符全部大写
3.set(集合)(底层红黑树)
set即为一个红黑树(是一种自平衡二叉查找树,红黑树和AVL树类似,都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能.它虽然是复杂的,但它的最坏情况运行时间也是非常良好的可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目),其作用是将排入的数据自动进行去重并且按照树的特性(左孩子的值一定比父节点的小,右孩子的值一定比父节点大) 可起到二分搜索的一个作用,但是这里一般常用的是查找是否右一个值在set里面和去重
下面介绍set的常用函数:
insert() 向set容器插入一个元素
push() 向set容器的尾部插入一个元素
begin() ,返回set容器第一个元素的迭代器
end() ,返回一个指向当前set末尾元素的下一位置的迭代器.
clear() ,删除set容器中的所有的元素
empty() ,判断set容器是否为空
max_size() ,返回set容器可能包含的元素最大个数
size() ,返回当前set容器中的元素个数
rbegin() ,返回的值和end()相同
rend() ,返回的值和begin()相同
count() 查找其值是否在set中存在
find() ,返回给定值值得定位器并赋值给迭代器,如果没找到则返回end()。
set集合的两个特点,有序和不重复。自动排序
count() 用来查找set中某个值出现的次数//一个值在set中只可能出现0次或者1次,这个函数主要是用于判断这个值是否在set中出现过
erase(iterator) ,删除定位器iterator指向的值
erase(first,second),删除定位器first和second之间的值
erase(key_value),删除键值key_value的值
集合set
set集合容器:实现了红黑树的平衡二叉检索树的数据结构,插入元素时,它会自动调整二叉树的排列,把元素放到适当的位置,以保证每个子树根节点键值大于左子树所有节点的键值,小于右子树所有节点的键值;另外,还得保证根节点左子树的高度与右子树高度相等。平衡二叉检索树使用中序遍历算法,检索效率高于vector、deque和list等容器,另外使用中序遍历可将键值按照从小到大遍历出来。构造set集合主要目的是为了快速检索,不可直接去修改键值。
常用操作:
1.元素插入:insert()
如s.insert(3)
2.中序遍历:类似vector遍历(用迭代器)
3.反向遍历:利用反向迭代器reverse_iterator。
set<int> s;
......
set<int>::reverse_iterator rit;
for(rit=s.rbegin();rit!=s.rend();rit++)
4.元素删除:与插入一样,可以高效的删除,并自动调整使红黑树平衡。
set<int> s;
s.erase(2); //删除键值为2的元素
s.clear();
5.元素检索:find(),若找到,返回该键值迭代器的位置,否则,返回最后一个元素后面一个位置。
set<int> s;
set<int>::iterator it;
it=s.find(5); //查找键值为5的元素
if(it!=s.end()) //找到
cout<<*it<<endl;
else //未找到
cout<<"未找到";
6.自定义比较函数
(1)元素不是结构体:
例:
//自定义比较函数myComp,重载“()”操作符
struct myComp
{
bool operator()(const your_type &a,const your_type &b)
{
return a.data-b.data>0;
}
}
set<int,myComp>s;
......
set<int,myComp>::iterator it;
(2)如果元素是结构体,可以直接将比较函数写在结构体内。
例:
struct Info
{
string name;
float score;
//重载“<”操作符,自定义排序规则
bool operator < (const Info &a) const
{
//按score从大到小排列
return a.score<score;
}
}
set<Info> s;
......
set<Info>::iterator it;
4.priority_queuqe(优先队列)(底层为大根堆小根堆)
priority_queue的底层为堆,大根堆(根节点的值是整个堆最大的,所有的子节点都比父节点的值小)和小根堆(根节点的值是整个堆最小的,所有的子节点都比父节点大)
empty() 如果队列为空,则返回真
pop() 删除对顶元素,删除第一个元素
push() 加入一个元素
size() 返回优先队列中拥有的元素个数
top() 返回优先队列对顶元素,返回优先队列中有最高优先级的元素
1、普通方法:
priority_queue q; //通过操作,按照元素从大到小的顺序出队
priority_queue<int,vector, greater > q; //通过操作,按照元素从小到大的顺序出队
2、自定义优先级:
bool cmp(int x, int y)
return x > y; // x小的优先级高 //也可以写成其他方式,如: return p[x] > p[y];表示p[i]小的优先级高
};
可以根据algorithm里面打包的快排sort进行改进比如sort(a,a+n,cmp)就能产生自定义排序
priority_queue<int, vector, cmp> q; //定义方法
//其中,第二个参数为容器类型。第三个参数为比较函数。
实用方法就是解决堆排序问题
优先队列priority_queue
1.调用头文件:
#include
using namespace std;
2.详细用法(部分):
priority_queue k; ------ 定义一个有序队列(默认从小到大排,其顶端元素为最大的那个)
priority_queue<(队列中元素的数据类型), (用于储存和访问队列元素的底层容器的类型), (比较规则) > k ------
(标准式)定义一个有序队列
例如:priority_queue<int, vector, greater > k;(注意:比较规则后面必须要空上一格) ->定义一个有序队列,
排序规则为从大到小(其顶端元素为最小的那个)(greater为从小到大,顶端最小,less为从大到小,顶端最大)
k.empty() ------ 查看是否为空范例,是的话返回1,不是返回0
k.push(i) ------ 从已有元素后面增加元素i(队伍大小不预设)
k.pop() ------ 清除位于顶端的元素(当然是排完序后,下同)
k.top() ------ 显示顶端的元素
k.size() ------ 输出现有元素的个数
例题:
问题概述:有n个土堆,每个土堆都有一定重量,你每次可以将任意两个土堆合并成一个大土堆,并消耗同等于两个
土堆总质量的体力,请问你至少需要多少体力才可以将所有土堆合成一个
输入样例: 对应输出:
10 105
8
1 2 8 7 6 9 2 3
思路:很显然,每次都将当前最轻的两个土堆合成一个大土堆即可
代码
#include<iostream>
#include<cstdio>
#include<queue>
using namespace std;
int main(void)
{
int T, n, x, i, a, b;
long long sum;
scanf("%d", &T);
while(T--)
{
sum = 0;
priority_queue<int, vector<int>, greater<int> > q; /*建立一个队列,其中队列顶端为最小值*/
scanf("%d", &n);
for(i=1;i<=n;i++)
{
scanf("%d", &x);
q.push(x);
}
while(q.empty()==0)
{
a = q.top(); /*弹出质量最小的两个土堆并合并*/
q.pop();
if(q.empty()==1) /*当然如果只剩下一个土堆了就结束*/
break;
b = q.top();
q.pop();
q.push(a+b); /*合并之后入队*/
sum += a+b;
}
printf("%lld\n", sum);
}
return 0;
}
5.queue(队列)(底层list或者deque)
queue 模板类的定义在头文件中。
与stack 模板类很相似,queue 模板类也需要两个模板参数,一个是元素类型,一个容器类
型,元素类型是必要的,容器类型是可选的,默认为deque 类型。
定义queue 对象的示例代码如下:
queue q1;
queue q2;
queue 的基本操作有:
入队,如例:q.push(x); 将x 接到队列的末端。
出队,如例:q.pop(); 弹出队列的第一个元素,注意,并不会返回被弹出元素的值。
访问队首元素,如例:q.front(),即最早被压入队列的元素。
访问队尾元素,如例:q.back(),即最后被压入队列的元素。
判断队列空,如例:q.empty(),当队列空时,返回true。
队列queue
C++队列queue模板类的定义在头文件中,queue 模板类需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是可选的,默认为deque 类型。 C++队列Queue是一种容器适配器,它…
C++队列queue模板类的定义在<queue>头文件中,queue 模板类需要两个模板参数,一个是元素类型,一个容器类型,元素类型是必要的,容器类型是可选的,默认为deque 类型。
C++队列Queue是一种容器适配器,它给予程序员一种先进先出(FIFO)的数据结构。
C++队列Queue类成员函数如下:
back() 返回最后一个元素
empty() 如果队列空则返回真
front() 返回第一个元素
pop() 删除第一个元素
push() 在末尾加入一个元素
size() 返回队列中元素的个数
定义queue 对象的示例代码如下:
queue<int> q1;
queue<double> q2;
queue 的基本操作举例如下:
queue入队,如例:q.push(x); 将x 接到队列的末端。
queue出队,如例:q.pop(); 弹出队列的第一个元素,注意,并不会返回被弹出元素的值。
访问queue队首元素,如例:q.front(),即最早被压入队列的元素。
访问queue队尾元素,如例:q.back(),即最后被压入队列的元素。
判断queue队列空,如例:q.empty(),当队列空时,返回true。
访问队列中的元素个数,如例:q.size()
C++ stl队列queue示例代码1:
#include <cstdlib>
#include <iostream>
#include <queue>
using namespace std;
int main()
{
int e,n,m;
queue<int> q1;
for(int i=0;i<10;i++)
q1.push(i);
if(!q1.empty())
cout<<"dui lie bu kong\n";
n=q1.size();
cout<<n<<endl;
m=q1.back();
cout<<m<<endl;
for(int j=0;j<n;j++)
{
e=q1.front();
cout<<e<<" ";
q1.pop();
}
cout<<endl;
if(q1.empty())
cout<<"dui lie bu kong\n";
system("PAUSE");
return 0;
}
C++ stl队列queue示例代码2:
#include <iostream>
#include <queue>
#include <assert.h>
/*
调用的时候要有头文件: #include<stdlib.h> 或 #include<cstdlib> +
#include<queue> #include<queue>
详细用法:
定义一个queue的变量 queue<Type> M
查看是否为空范例 M.empty() 是的话返回1,不是返回0;
从已有元素后面增加元素 M.push()
输出现有元素的个数 M.size()
显示第一个元素 M.front()
显示最后一个元素 M.back()
清除第一个元素 M.pop()
*/
using namespace std;
int _tmain(int argc, _TCHAR* argv[])
{
queue <int> myQ;
cout<< "现在 queue 是否 empty? "<< myQ.empty() << endl;
for(int i =0; i<10 ; i++)
{
myQ.push(i);
}
for(int i=0; i<myQ.size(); i++)
{
printf("myQ.size():%d\n",myQ.size());
cout << myQ.front()<<endl;
myQ.pop();
}
system("PAUSE");
return 0;
}
输出结果:
现在 queue 是否 empty? 1
myQ.size():10
0
myQ.size():9
1
myQ.size():8
2
myQ.size():7
3
myQ.size():6
4
请按任意键继续. . .
(二)deque双端队列
1.包含在头文件#include
2.底层实现
底层是一个二维数组 刚开始只开辟了两个格子的一维数组,每个一维数组里的指针指向一个二维数组的格子
每个指针指向的格子的大小由创建的双端队列所存放的数据类型有关
tempalate
QUEUE_SIZE = 4096/T
3.扩容规则
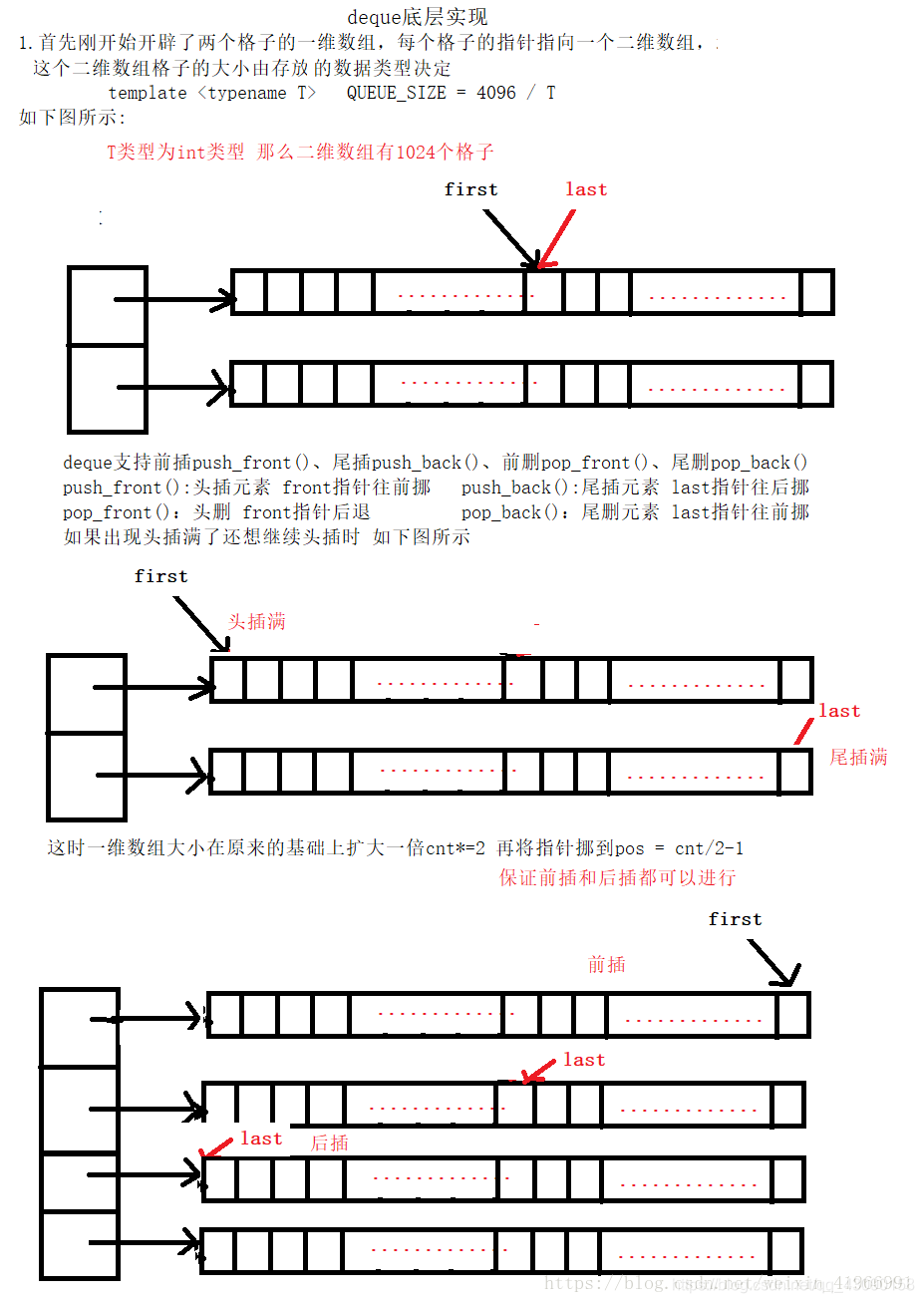
扩容方式如上图所示
从deque的内存布局来看 它是整体不连续 局部连续
优点:随机访问方便 支持[]操作符和at操作
在内部可以进行头插 头删 尾插 尾删 时间复杂度都为O(1)
缺点:内存占用量大
4.初始化方式
deque dq1;//创建一个空的队列
deque dq2(10);//创建一个含有10个数据的队列 数据被默认初始构造
deque dq3(10,5);//创建有一个含有10个数据并且都初始化为5的队列
deque dq4(begin.end);//创建一个以(begin,end)区间的队列
deque dq5(dq4);//复制一个队列
5.常用函数接口
dq.begin():表示迭代器指向的第一个元素 dq.end():表示迭代器指向尾元素的后一个位置
dq.at(index):传回index对应的元素 如果index越界 抛出out_of_range
dq.back():传回最后一个元素 不检查这个数据是否存在
dq.front():传回第一个元素
dq.assgin(begin.end):将(begin.end)区间中的数据赋值c
dq.assign(n.val):将n个val的拷贝值给dq
dq.empty():判空
dq.erase(pos):删除os位置 传回pos的下一个位置
d1.erase(begin,end):删除(begin,end)区间的值
dq.resize(num):重新指定队列的长度
dq.size():返回容器中的实际数据个数
dq1.swap(dq2):将dq1和dq2元素互换
6.元素遍历方式
7.插入元素
8.删除元素
dq.erase(pos):删除os位置 传回pos的下一个位置
d1.erase(begin,end):删除(begin,end)区间的值
dq1.pop_back():尾删
dq1.pop_front():头删
9.迭代器失效问题
1.在deque容器首部或者尾部插入元素不会使得任何迭代器失效
2.在其首部或尾部删除元素则只会使指向被删除元素的迭代器失效
3.在deque容器的任何其他位置的插入和删除操作将使指向该容器元素的所有迭代器失效
4.在扩容阶段也会使所有迭代器失效
template <typename Container>
void Show(Container &con)
{
Container::iterator it = con.begin();
for(; it != con.end();++it)
{
cout<<*it<<" ";
}
cout<<endl;
}
template <typename Container>
bool Del_Container1(Container &con,int val)
{
if(con.empty())
{
return false ;
}
Container::iterator it = con.begin();
for( it ; it != con.end();)
{
if(*it == val)
{
it = con.erase(it);
}
else
{
++it;
}
}
return true;
}
int main()
{
deque<int> dq1(10,5);
deque<int>::iterator it = dq1.begin();
for(; it != dq1.end();++it)
cout<<*it<<" ";
cout<<endl;
int arr[] = {1,2,3,4,5,6,7,8,1,2,1,2,2,2};
int len = sizeof(arr)/sizeof(arr[0]);
deque<int> dq2(arr,arr+len);
Show(dq2);
dq2.pop_back();
Show(dq2);
return 0;
}
1、声明deque容器
#include<deque> / 头文件
deque<type> deq; / 声明一个元素类型为type的双端队列que
deque<type> deq(size); / 声明一个类型为type、含有size个默认值初始化元素的的双端队列que
deque<type> deq(size, value); / 声明一个元素类型为type、含有size个value元素的双端队列que
deque<type> deq(mydeque); / deq是mydeque的一个副本
deque<type> deq(first, last); / 使用迭代器first、last范围内的元素初始化deq
2、deque的常用成员函数
deque<int> deq;
- deq[ ]:用来访问双向队列中单个的元素。
- deq.front():返回第一个元素的引用。
- deq.back():返回最后一个元素的引用。
- deq.push_front(x):把元素x插入到双向队列的头部。
- deq.pop_front():弹出双向队列的第一个元素。
- deq.push_back(x):把元素x插入到双向队列的尾部。
- deq.pop_back():弹出双向队列的最后一个元素。
3、deque的一些特点 - 支持随机访问,即支持[ ]以及at(),但是性能没有vector好。
- 可以在内部进行插入和删除操作,但性能不及list。
- deque两端都能够快速插入和删除元素,而vector只能在尾端进行。
- deque的元素存取和迭代器操作会稍微慢一些,因为deque的内部结构会多一个间接过程。
- deque迭代器是特殊的智能指针,而不是一般指针,它需要在不同的区块之间跳转。
- deque可以包含更多的元素,其max_size可能更大,因为不止使用一块内存。
- deque不支持对容量和内存分配时机的控制。
- 在除了首尾两端的其他地方插入和删除元素,都将会导致指向deque元素的任何pointers、
- references、iterators失效。不过,deque的内存重分配优于vector,因为其内部结构显示不需要复制所有元素。
- deque的内存区块不再被使用时,会被释放,deque的内存大小是可缩减的。不过,是不是这么做以及怎么做由实际操作版本定义。
- deque不提供容量操作:capacity()和reverse(),但是vector可以。
6.map(映射)(底层为红黑树)
map提供一对一的hash,Map主要用於資料一對一映射(one-to-one)的情況,map內部的實現自建一顆紅黑樹,這顆樹具有對數據自動排序的功能。比如一個班級中,每個學生的學號跟他的姓名就存在著一對一映射的关系
这里介绍常用的方法函数:
map<string, string> mapStudent;//定义变量,一对一数据类型,
//用insert函數插入pair
mapStudent.insert(pair<string, string>(“r000”, “student_zero”));
//用"array"方式插入
mapStudent[“r123”] = “student_first”;
mapStudent[“r456”] = “student_second”;
iter = mapStudent.find(“r123”)//和以往的find的返回值相同如果额米有查询到就返回end(),如果右就返回其所在地址
clear()清空
empty()判断是否为空,若为空则返回true
三种erase()方式:
mapStudent.erase(iter);//迭代器删除
int n = mapStudent.erase(“r123”);//关键字删除,如果刪除了會返回1,否則返回0
mapStudent.erase(mapStudent.begin(), mapStudent.end())//此时为删除所有元素,左闭下右
映射map
Map是键-值对的集合,map中的所有元素都是pair,可以使用键作为下标来获取一个值。Map中所有元素都会根据元素的值自动被排序,同时拥有实值value和键值key,pair的第一元素被视为键值,第二元素被视为实值,同时map不允许两个元素有相同的键值。
1. map最基本的构造函数:
map<string , int >mapstring; map<int ,string >mapint;
map<string, char>mapstring; map< char ,string>mapchar;
map<char ,int>mapchar; map<int ,char >mapint;
2. map添加数据:
给map容器添加元素可通过两种方式实现:
- 通过insert成员函数实现。
- 通过下标操作符获取元素,然后给获取的元素赋值。 map对象的访问可通过下标和迭代器两种方式实现:
- map的下标是键,返回的是特定键所关联的值。
- 使用迭代器访问,iter->first指向元素的键,iter->second指向键对应的值。
使用下标访问map容器与使用下标访问vector的行为截然不同:用下标访问map中不存在的元素将导致在map容器中添加一个新的元素,这个元素的键即为该下标值,键所对应的值为空。
如:
map<int ,string> maplive;
1.maplive.insert(pair<int,string>(102,"aclive"));
2.maplive.insert(map<int,string>::value_type(321,"hai"));
3, maplive[112]="April"; /map中最简单最常用的插入添加!
3,map中元素的查找:
find()函数返回一个迭代器指向键值(就是键,值在这里叫做实值)为key的元素,如果没找到就返回指向map尾部的迭代器。
map<int ,string >::iterator l_it;;
l_it=maplive.find(112);
if(l_it==maplive.end())
cout<<"we do not find 112"<<endl;
else
cout<<"wo find 112"<<endl;
4,map中元素的删除:
如果删除112;
map<int ,string >::iterator l_it;;
l_it=maplive.find(112);
if(l_it==maplive.end())
cout<<"we do not find 112"<<endl;
else
maplive.erase(l_it); //delete 112;
5,map中 swap的用法:
Map中的swap不是一个容器中的元素交换,而是两个容器交换;
For example:
#include <map>
#include <iostream>
using namespace std;
int main( )
{
map <int, int> m1, m2, m3;
map <int, int>::iterator m1_Iter;
m1.insert ( pair <int, int> ( 1, 10 ) );
m1.insert ( pair <int, int> ( 2, 20 ) );
m1.insert ( pair <int, int> ( 3, 30 ) );
m2.insert ( pair <int, int> ( 10, 100 ) );
m2.insert ( pair <int, int> ( 20, 200 ) );
m3.insert ( pair <int, int> ( 30, 300 ) );
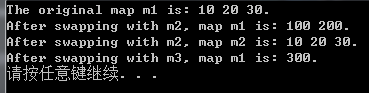
cout << "The original map m1 is:";
for ( m1_Iter = m1.begin( ); m1_Iter != m1.end( ); m1_Iter++ )
cout << " " << m1_Iter->second;
cout << "." << endl;
// This is the member function version of swap
//m2 is said to be the argument map; m1 the target map
m1.swap( m2 );
cout << "After swapping with m2, map m1 is:";
for ( m1_Iter = m1.begin( ); m1_Iter != m1.end( ); m1_Iter++ )
cout << " " << m1_Iter -> second;
cout << "." << endl;
cout << "After swapping with m2, map m2 is:";
for ( m1_Iter = m2.begin( ); m1_Iter != m2.end( ); m1_Iter++ )
cout << " " << m1_Iter -> second;
cout << "." << endl;
// This is the specialized template version of swap
swap( m1, m3 );
cout << "After swapping with m3, map m1 is:";
for ( m1_Iter = m1.begin( ); m1_Iter != m1.end( ); m1_Iter++ )
cout << " " << m1_Iter -> second;
cout << "." << endl;
}
运行结果
6.map的sort问题:
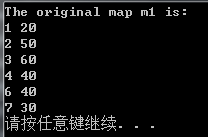
Map中的元素是自动按key升序排序,所以不能对map用sort函数:
For example:
#include <map>
#include <iostream>
using namespace std;
int main( )
{
map <int, int> m1;
map <int, int>::iterator m1_Iter;
m1.insert ( pair <int, int> ( 1, 20 ) );
m1.insert ( pair <int, int> ( 4, 40 ) );
m1.insert ( pair <int, int> ( 3, 60 ) );
m1.insert ( pair <int, int> ( 2, 50 ) );
m1.insert ( pair <int, int> ( 6, 40 ) );
m1.insert ( pair <int, int> ( 7, 30 ) );
cout << "The original map m1 is:"<<endl;
for ( m1_Iter = m1.begin( ); m1_Iter != m1.end( ); m1_Iter++ )
cout << m1_Iter->first<<" "<<m1_Iter->second<<endl;
}
7, map的基本操作函数:
C++ Maps是一种关联式容器,包含“关键字/值”对
begin() 返回指向map头部的迭代器
clear() 删除所有元素
count() 返回指定元素出现的次数
empty() 如果map为空则返回true
end() 返回指向map末尾的迭代器
equal_range() 返回特殊条目的迭代器对
erase() 删除一个元素
find() 查找一个元素
get_allocator() 返回map的配置器
insert() 插入元素
key_comp() 返回比较元素key的函数
lower_bound() 返回键值>=给定元素的第一个位置
max_size() 返回可以容纳的最大元素个数
rbegin() 返回一个指向map尾部的逆向迭代器
rend() 返回一个指向map头部的逆向迭代器
size() 返回map中元素的个数
swap() 交换两个map
upper_bound() 返回键值>给定元素的第一个位置
value_comp() 返回比较元素value的函数
8.map容器和哈希表 :
对于map容器,使用其下标行为一次访问一系列的相同类型的元素,则可以将这个过程理解为构造了这些元素的一个哈希表,以统计输入单词的出现次数为例:
map<string, int> word_count;
string word;
while(cin>>word)
++word_count[word]; // 相当于生成了一个哈希表word_count
简单的说,就是键(本例中为string)会被作为数组的下标,值(本例中为int)则为该下标所对应的数组元素的值
7.list(链表)(底层双向链表)
这里介绍常用的方法函数
//定义变量
lista{1,2,3}
lista(n)//定义了n个初始值为0的元素
lista(n,m)定义了n个初始值为m的元素
begin();//起始位置迭代器
end();//末尾位置下一个位置迭代器
size()//返回长度
push_back()//从末尾加入
push_front()//从开头加入
empty()//检查其是否为空
resize(n)//将链表改为最多只能容纳n个元素超出的将会删除
clear();//清空链表
front()//返回首元素
back()//返回末尾元素
pop_back()//删除末尾元素
pop_front()//删除首元素
a.assign(n,val)//将a中的所有元素全部替换成n个val元素
b.assign(a.begin(),a.end())将b的元素全部替换成a的元素
swap()//交换
reserve()//当前逆序排列
insert(a.begin(),100)//在a开头插入100
insert(a.begin(),2,100)//在a开头插入两个100
insert(a.begin(),b.begin(),b.end())//在a开头插入b的全部元素
a.erase(a.begin())//删除a开头的元素
a.erase(a.begin(),a.end())//删除a的全部元素
a.remove(4)从a中移除所有值为4的元素
一.list的定义
List是stl实现的双向链表,与向量(vectors)相比, 它允许快速的插入和删除,但是随机访问却比较慢。使用时需要添加头文件
#include <list>
二.List定义和初始化:
list<int>lst1; //创建空list
list<int> lst2(5); //创建含有5个元素的list
list<int>lst3(3,2); //创建含有3个元素的list
list<int>lst4(lst2); //使用lst2初始化lst4
list<int>lst5(lst2.begin(),lst2.end()); //同lst4
三.List常用操作函数:
Lst1.assign() 给list赋值
Lst1.back() 返回最后一个元素
Lst1.begin() 返回指向第一个元素的迭代器
Lst1.clear() 删除所有元素
Lst1.empty() 如果list是空的则返回true
Lst1.end() 返回末尾的迭代器
Lst1.erase() 删除一个元素
Lst1.front() 返回第一个元素
Lst1.get_allocator() 返回list的配置器
Lst1.insert() 插入一个元素到list中
Lst1.max_size() 返回list能容纳的最大元素数量
Lst1.merge() 合并两个list
Lst1.pop_back() 删除最后一个元素
Lst1.pop_front() 删除第一个元素
Lst1.push_back() 在list的末尾添加一个元素
Lst1.push_front() 在list的头部添加一个元素
Lst1.rbegin() 返回指向第一个元素的逆向迭代器
Lst1.remove() 从list删除元素
Lst1.remove_if() 按指定条件删除元素
Lst1.rend() 指向list末尾的逆向迭代器
Lst1.resize() 改变list的大小
Lst1.reverse() 把list的元素倒转
Lst1.size() 返回list中的元素个数
Lst1.sort() 给list排序
Lst1.splice() 合并两个list
Lst1.swap() 交换两个list
Lst1.unique() 删除list中重复的元素
四、List使用示例:
示例1:遍历List
//迭代器法
for(list<int>::const_iteratoriter = lst1.begin();iter != lst1.end();iter++)
{
cout<<*iter;
}
cout<<endl;
示例2:
#include <iostream>
#include <list>
#include <numeric>
#include <algorithm>
#include <windows.h>
using namespace std;
typedef list<int> LISTINT;
typedef list<int> LISTCHAR;
void main()
{
//用LISTINT创建一个list对象
LISTINT listOne;
//声明i为迭代器
LISTINT::iterator i;
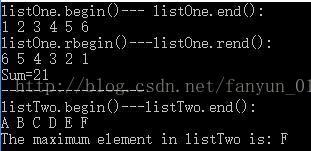
listOne.push_front(3);
listOne.push_front(2);
listOne.push_front(1);
listOne.push_back(4);
listOne.push_back(5);
listOne.push_back(6);
cout << "listOne.begin()--- listOne.end():" << endl;
for (i = listOne.begin(); i != listOne.end(); ++i)
cout << *i << " ";
cout << endl;
LISTINT::reverse_iterator ir;
cout << "listOne.rbegin()---listOne.rend():" << endl;
for (ir = listOne.rbegin(); ir != listOne.rend(); ir++) {
cout << *ir << " ";
}
cout << endl;
int result = accumulate(listOne.begin(), listOne.end(), 0);
//accumulate: 以init为初值,对迭代器给出的值序列做累加,返回累加结果值,
cout << "Sum=" << result << endl;
cout << "------------------" << endl;
//用LISTCHAR创建一个list对象
LISTCHAR listTwo;
//声明i为迭代器
LISTCHAR::iterator j;
listTwo.push_front('C');
listTwo.push_front('B');
listTwo.push_front('A');
listTwo.push_back('D');
listTwo.push_back('E');
listTwo.push_back('F');
cout << "listTwo.begin()---listTwo.end():" << endl;
for (j = listTwo.begin(); j != listTwo.end(); ++j)
cout << char(*j) << " ";
cout << endl;
j = max_element(listTwo.begin(), listTwo.end());
cout << "The maximum element in listTwo is: " << char(*j) << endl;
Sleep(10000); //这是windows里的延时函数,这里作用是主函数运行完之后10s后程序才停止
}
8.stack(栈)(底层为list或者deque)
stack的底层就是一个栈其底层默认容器为deque(双向队列),栈的特性是后进先出并且只有一端有接口可以进行操作
下面介绍常用的方法函数:
top()//返回栈顶元素;
pop()//删除栈顶元素
push()//将一个元素压入栈顶
empty()//检查其是否为空
size()//返回长度
stack<>//定义对象
stack<int,vector<>//定义一个底层为vector的int栈
deque a;
stackb(a)//将底层相同的对象赋值给stack
栈stack
c++ stl栈stack介绍c++ Stack(堆栈) 是一个容器类的改编,为程序员提供了堆栈的全部功能,——也就是说实现了一个先进后出(FILO)的数据结构。
c++ stl栈stack的头文件为:
#include <stack>
c++ stl栈stack的成员函数介绍
操作 比较和分配堆栈
empty() 堆栈为空则返回真
pop() 移除栈顶元素
push() 在栈顶增加元素
size() 返回栈中元素数目
top() 返回栈顶元素
c++ stl栈stack用法代码举例1
#include <iostream>
#include <stack>
using namespace std;
int main ()
{
stack<int> mystack;
int sum (0);
for (int i=1;i<=10;i++) mystack.push(i);
while (!mystack.empty())
{
sum += mystack.top();
mystack.pop();
}
cout << "total: " << sum << endl;
return 0;
}
c++ stl栈stack用法代码举例2
#include <iostream>
#include <stack>
using namespace std;
int main ()
{
stack<int> mystack;
for (int i=0; i<5; ++i) mystack.push(i);
cout << "Popping out elements...";
while (!mystack.empty())
{
cout << " " << mystack.top();
mystack.pop();
}
cout << endl;
return 0;
}














 1789
1789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









