







文章目录
实现 ASSERT 断言
作用: 哨兵,监督数据的正确性。何为“断言”?断即断定,断定程序某处一定是这样的结果,若不是则终止程序。
实现开、关中断的函数
本书中实现两种断言:
- 为内核系统使用的 ASSERT(本节先实现这个)
- 为用户进场使用的 ASSERT
内核运行中出现严重问题时,就没必要运行下去了。断言输出报错信息时,屏幕输出不应该被其它进场干扰。
所以:ASSERT 排查出错误后,最好在关中断的情况下打印报错信息。
kernel/interrupt.c:
// ...
#define EFLAGS_IF 0x00000200 // ELFAGS 寄存器中 IF = 1
// 获取标志寄存器的值,并且输出到C变量 EFLAG_VAR 中
#define GET_EFLAGS(EFLAG_VAR) asm volatile("pushfl; popl %0" : "=g" (EFLAG_VAR))
// ...
// 开中断并返回开中断前的状态
enum intr_status intr_enable() {
enum intr_status old_status;
if(INTR_ON == intr_get_status()) old_status = INTR_ON;
else {
old_status = INTR_OFF;
asm volatile("sti"); // 开中断,将IF置为1
}
return old_status;
}
// 关闭中断,并且返回关闭中断前的状态
enum intr_status intr_disable() {
enum intr_status old_status;
if(INTR_ON == intr_get_status()) {
old_status = INTR_ON;
asm volatile("cli" : : : "memory"); // 关中断,将IF置为0
} else {
old_status = INTR_OFF;
}
return old_status;
}
// 将中断状态设置为 status
enum intr_status intr_set_status(enum intr_status status) {
return status & INTR_ON ? intr_enable() : intr_disable();
}
// 获取中断状态
enum intr_status intr_get_status() {
uint32_t eflags = 0;
GET_EFLAGS(eflags);
return (EFLAGS_IF & eflags) ? INTR_ON : INTR_OFF;
}
kernel/interrupt.h:
#ifndef __KERNEL_INTERRUPT_H
#define __KERNEL_INTERRUPT_H
#include "stdint.h"
typedef void* intr_handler;
void idt_init(void);
/**
* 定义中断的状态:
* INTR_OFF:0 表示关中断
* INTR_ON:1 表示开中断
*/
enum intr_status {
INTR_OFF,
INTR_ON
};
enum intr_status intr_get_status(void);
enum intr_status intr_set_status(enum intr_status);
enum intr_status intr_enable(void);
enum intr_status intr_disable(void);
#endif
实现 ASSERT
C 语言中的 ASSERT:
ASSERT(条件表达式) // 若条件表达式不满足,则错误
kernel/debug.h:
#ifndef __KERNEL_DEBUG_H
#define __KERNEL_DEBUG_H
void panic_spin(char* filename, int line, const char* func, const char* condition);
// __VA_ARGS__ 是预处理器所支持的专用标识符
#define PANIC(...) panic_spin(__FILE__, __LINE__, __func__, __VA_ARGS__)
/**
* ASSERT 是在调试过程中用的,经过预处理器展开后,
* 调用宏的地方越多,程序的体积越大,所以执行得越慢。
* 因此不需要调试时,应该取消 ASSERT
*/
#ifdef NDEBUG
#define ASSERT(CONDITION) ((void) 0) // 取消 ASSERT
#else
#define ASSERT(CONDITION) \
if(CONDITION) {} else { \
/* 符号“#”让编译器将宏的参数转化为字符串字面量, 例如:a==b 变成 "a==b" */ \
PANIC(#CONDITION); \
}
#endif
#endif
kernel/debug.c:
#include "debug.h"
#include "print.h"
#include "interrupt.h"
void panic_spin(char* filename, int line, const char* func, const char* condition) {
intr_disable();
put_str("\n\n\n!!!!! error !!!!!\n");
put_str("filename:"); put_str(filename); put_str("\n");
put_str("line:0x"); put_int(line); put_str("\n");
put_str("function:"); put_str((char*) func); put_str("\n");
put_str("condition:"); put_str((char*) condition); put_str("\n");
while(1);
}
__VA_ARGS__
简介: 可变参数宏 __VA_ARGS__ 是 C99 中引入的一个宏,表示一个或多个参数,相当于一个占位符,会替代传入的所有可变参数。
#include <stdio.h>
#define ptr_str(format, ...) printf(format, ##__VA_ARGS__)
void main() {
ptr_str("%s\n", "hhh"); // printf("%s\n", "hhh")
ptr_str("%s\n"); // printf("%s\n")
}
// ======================================
#include <stdio.h>
#define ptr_str(format, ...) printf(format, __VA_ARGS__)
void main() {
ptr_str("%s\n", "hhh"); // printf("%s\n", "hhh")
ptr_str("%s\n"); // printf("%s\n", )
}
// 【编译报错】
// main.c: In function ‘main’:
// main.c:3:56: error: expected expression before ‘)’ token
// #define ptr_str(format, ...) printf(format, __VA_ARGS__)
关于 ## :
- 可以忽略,直接写成
__VA_ARGS__,但若可变参数为 0,则会编译报错。 - 加上后,意思是当可变参数个数为 0 时,自动忽略前面的逗号。
测试断言
kernel/main.c:
#include "print.h"
#include "init.h"
#include "debug.h"
int main(void) {
put_str("I am kernel\n");
init_all();
//asm volatile("sti");
ASSERT(1==2);
while(1);
return 0;
}
位图 bitmap 及其函数的实现
位图简介
位图,广泛应用于资源管理,是一种管理资源的方式、手段。资源包括很多,例如内存或硬盘,,对于此类大容量资源的管理一般都会采用位图的方式。
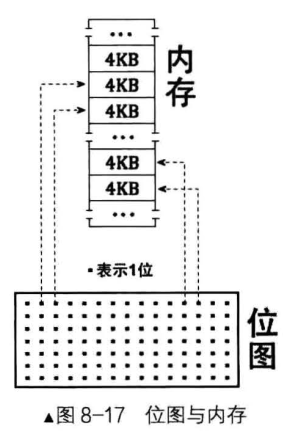
位指的是 Bit,1 字节为 8 个 Bit,每个 Bit 对应一个资源,也就是说资源和 Bit 是一对一的关系。
既然位图本质就是一串二进制位,那对于它的实现,用字节数组比较方便,数组中每个元素都是一个字节,每个字节八个位,每个位对应一个资源,即一个字节表示 8 个资源单位。
本书中,位图中的每一位都将表示实际物理内存中的 4KB,即一页。0 表示未使用,1 表示已使用。
位图的定义与实现
lib/kernel/bitmap.h:
#ifndef __LIB_KERNEL_BITMAP_H
#define __LIB_KERNEL_BITMAP_H
#include "global.h"
#define BITMAP_MASK 1
struct bitmap {
uint32_t btmp_bytes_len;
/* 在遍历位图时,整体上以字节为单位,细节上是以位为单位,所以此处位图的指针必须是单字节 */
uint8_t* bits; // 指向的是一个以字节为单位的数组
};
void bitmap_init(struct bitmap* btmp);
bool bitmap_scan_test(struct bitmap* btmp, uint32_t bit_idx);
int bitmap_scan(struct bitmap* btmp, uint32_t cnt);
void bitmap_set(struct bitmap* btmp, uint32_t bit_idx, int8_t value);
#endif
lib/kernel/bitmap.c:
// 初始化位图 btmp
void bitmap_init(struct bitmap* btmp) {
memset(btmp -> bits, 0, btmp -> btmp_bytes_len);
}
// 判断第 bit_idx 位是否为 1,若为 1,则返回 true,反之 false
bool bitmap_scan_test(struct bitmap* btmp, uint32_t bit_idx) {
uint32_t byte_idx = bit_idx / 8; // 向下取整,得到 bit_idx 所在字节,即数组下标索引
uint32_t bit_odd = bit_idx % 8; // 取余,表示字节中的位
return (btmp -> bits[byte_idx] & (BITMAP_MASK << bit_odd));
}
// 在位图中申请连续 cnt 个位,返回起始下标,否则返回 -1
int bitmap_scan(struct bitmap* btmp, uint32_t cnt) {
uint32_t idx_byte = 0; // 记录空闲位所在字节
// 先逐字比较
while((btmp->bits[idx_byte] == 0xFF) && (idx_byte < btmp->btmp_bytes_len)) idx_byte++;
ASSERT(idx_byte < btmp->btmp_bytes_len);
if(idx_byte == btmp->btmp_bytes_len) return -1; // 无可用空间
// 若在位图某字节中有空闲位,则在该字节上进行逐位比对
int idx_bit = 0; // 记录空闲位的索引
while((uint8_t)(BITMAP_MASK << idx_bit) & btmp -> bits[idx_byte]) idx_bit++;
int bit_idx_start = idx_byte * 8 + idx_bit; // 空闲位在位图中的下标
if(cnt == 1) return bit_idx_start;
uint32_t bit_left = (btmp -> btmp_bytes_len * 8 - bit_idx_start); // 记录还有多少位可以判断
uint32_t next_bit = bit_idx_start + 1; // 下一个位的下标
uint32_t count = 1; // 记录找到了多少个空闲位
bit_idx_start = -1; // 在 bit_idx_start == cnt 之前先置为 -1
while(bit_left-- > 0) {
if(!(bitmap_scan_test(btmp, next_bit))) count++; // next_bit 未使用
else count = 0; // next_bit 被使用,导致不连续,因此之前的全部废除,重新从 0 开始计算
if(count == cnt) { // 找到了连续的 cnt 个空闲位
bit_idx_start = next_bit - cnt + 1;
break;
}
next_bit++;
}
return bit_idx_start;
}
// 将位图 btmp 的第 bit_idx 个位设置位 value(0 or 1)
void bitmap_set(struct bitmap* btmp, uint32_t bit_idx, int8_t value) {
ASSERT((value == 0) || (value == 1));
uint32_t byte_idx = bit_idx / 8; // 找到 bit_idx 所在字节
uint32_t bit_odd = bit_idx % 8; // 找到字节内的位
if(value) btmp -> bits[byte_idx] |= (BITMAP_MASK << bit_odd); // value = 1
else btmp -> bits[byte_idx] &= ~(BITMAP_MASK << bit_odd); // value = 0
}
内存管理系统
内存池规划
如何规划物理内存池:操作系统为了能够正常运行,必须保证有足够的内存空间留给自己,不能用户想申请(malloc)多少就申请多少,否则可能出现物理内存不足,导致内核自己无法正常运行。
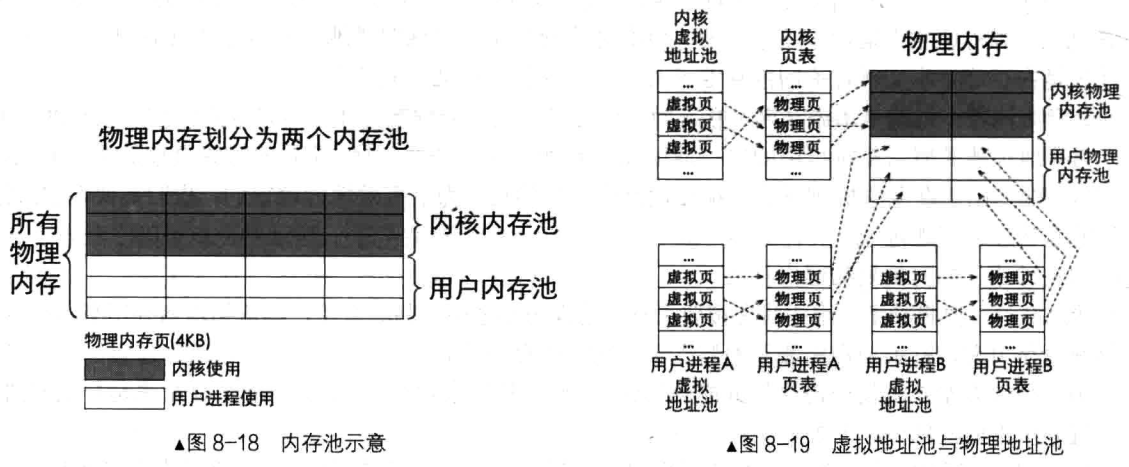
因此把物理内存分为两个内存池:
用户物理内存池:此内存池中的物理内存只用来分配给用户进程。内核物理内存池:此内存池中的物理内存只用来分配给操作系统。
内存池中的资源单位:4KB,即一页,因此内存池中的资源就是一个个 4KB 大小的内存块。
程序(进程、内核线程)在运行过程中也有申请内存的需求,这种动态申请内存一般是指在堆中申请内存,操作系统接受申请后,为进程或内核自己在堆中选择一段空闲的虚拟地址,并且找个空闲的物理地址作为此虚拟地址的映射,之后把这个虚拟地址返回给程序。
内核申请内存:内核也需要内存,虽然它可以不申请,而直接用,但我们还是让内核通过申请的方式得到内存资源,为此它也需要一个虚拟内存池,当它申请内存时,从内核自己的虚拟地址池中分配虚拟地址,再从内核物理内存池(内核专用)中分配物理内存,最后在内核自己的页表中将这两种地址建立好映射关系。
用户进程申请内存:用户进程向操作系统申请内存时,操作系统先从用户进程自己的虚拟地址池中分配空闲虚拟地址,然后再从用户物理内存池(所有用户进程共享)中分配空闲的物理内存,然后在该用户进程自己的页表中将这两种地址建立好映射关系。
对于所有任务(包括用户进程、内核)来说,它们都各自有 4GB 虚拟地址空间,因此需要为所有任务都维护它们自己的虚拟地址池,即一个任务一个。
为了便于管理,虚拟地址池和物理地址池都是 4KB,这样虚拟地址便于和物理地址做完整页的映射。
代码实现
kernel/memory.h:
#ifndef __KERNEL_MEMORY_H
#define __KERNEL_MEMORY_H
#include "stdint.h"
#include "bitmap.h"
/* 用于虚拟地址管理 */
struct virtual_addr {
struct bitmap vaddr_bitmap; // 虚拟地址用到的位图结构
uint32_t vaddr_start; // 虚拟地址起始地址
};
extern struct pool kernel_pool, user_pool;
void mem_init(void);
#endif
kernel/memory.c:
#include "memory.h"
#include "stdint.h"
#include "print.h"
#define PG_SIZE 4096
// ================ 位图地址 ================
// 为什么是 0xc009a000?
// 因为 0xc009f000 - 0x1000 - 0x1 = 0xc009e000 这是 PCB 表尾
// 0xc009e000 是将来主线程存放 PCB 的地址(表头 + 4k 为 0xc009efff)
// 因为页单位为 4k,位图以字节为单位划分,细粒度单位是位,每位表示 4k 即一页
// 故而一页大小的位图可管理的内存容量:4k * 8 * 4k = 128M
// 当前我们给虚拟机分配了 32Mb 内存空间,因此这才用了四分之一页
// 为了扩展,本书中这里假设要管理 4页 的位图,即最大可管理 512MB 的物理内存
// 综上所述,0xc009e000 还需要减去 4页 的位图:0xc009e000 - 0x4000 = 0xc009a000
#define MEM_BITMAP_BASE 0xc009a000
// =========================================
/* 0xc0000000 是内核从虚拟地址 3G 起. 0x100000 意指跨过低端 1M 内存,使虚拟地址在逻辑上连续 */
#define K_HEAP_START 0xc0100000
// 内存池结构
struct pool {
struct bitmap pool_bitmap; // 该内存池所用到的位图结构,用于管理物理内存
uint32_t phy_addr_start; // 该内存池所管理物理内存的起始地址
uint32_t pool_size; // 该内存池字节容量
};
struct pool kernel_pool, user_pool; // 内核物理内存池和用户物理内存池
struct virtual_addr kernel_vaddr; // 用于给内核分配虚拟地址
// 初始化内存池
static void mem_pool_init(uint32_t all_mem) {
put_str(" mem_pool_init start\n");
uint32_t page_table_size = PG_SIZE * 256; // 页表大小
uint32_t used_mem = page_table_size + 0x100000; // 已使用的内存,0x100000 是低端 1M
uint32_t free_mem = all_mem - used_mem; // 剩余的可以内存
uint16_t all_free_pages = free_mem / PG_SIZE; // 剩余的空闲内存可以分配成多少页
// 计算内核和用户内存池可以分配到的物理容量,这里采用对半分
uint16_t kernel_free_pages = all_free_pages / 2;
uint16_t user_free_pages = all_free_pages - kernel_free_pages;
// 因为位图每位表示 4k 即一页,而 1byte = 8bit,所以这里除 8 求得位图长度
uint32_t kbm_length = kernel_free_pages / 8;
uint32_t ubm_length = user_free_pages / 8;
// 计算内核和用户内存池的起始地址
uint32_t kp_start = used_mem; // Kernel Pool Start 内核内存池的起始地址
uint32_t up_start = kp_start + kernel_free_pages * PG_SIZE; // User Pool Start 用户内存池的起始地址
/* ----------------- 下面都是内核和用户内存池的初始化工作 --------------- */
kernel_pool.phy_addr_start = kp_start;
user_pool.phy_addr_start = up_start;
kernel_pool.pool_size = kernel_free_pages * PG_SIZE;
user_pool.pool_size = user_free_pages * PG_SIZE;
kernel_pool.pool_bitmap.btmp_bytes_len = kbm_length;
user_pool.pool_bitmap.btmp_bytes_len = ubm_length;
/*位图是全局数据,长度不固定。
全局或静态的数组需要在编译时直到其长度
而我们需要根据总内存大小算出需要多少字节
所以改为指定一块内存来生成位图*/
kernel_pool.pool_bitmap.bits = (void*) MEM_BITMAP_BASE;
// 用户内存池的位图紧跟在内核内存池的位图之后
user_pool.pool_bitmap.bits = (void*) (MEM_BITMAP_BASE + kbm_length);
/* ------------------------- 输出内存池信息 ---------------------------- */
put_str(" kernel_pool_bitmap_start:");put_int((int)kernel_pool.pool_bitmap.bits);
put_str(" kernel_pool_phy_addr_start:");put_int(kernel_pool.phy_addr_start);
put_str("\n");
put_str(" user_pool_bitmap_start:");put_int((int)user_pool.pool_bitmap.bits);
put_str(" user_pool_phy_addr_start:");put_int(user_pool.phy_addr_start);
put_str("\n");
// 将位图置为 0
bitmap_init(&kernel_pool.pool_bitmap);
bitmap_init(&user_pool.pool_bitmap);
/* ----------- 下面初始化内核虚拟地址的位图,按实际物理内存大小生成数组 ---------- */
// 用于维护内核堆的虚拟地址,所以要和内核内存池大小一致
kernel_vaddr.vaddr_bitmap.btmp_bytes_len = kbm_length;
// 位图的数组指向一块未使用的内存,目前定位在内核内存池和用户内存池之后
kernel_vaddr.vaddr_bitmap.bits = (void*) (MEM_BITMAP_BASE + kbm_length + ubm_length);
kernel_vaddr.vaddr_start = K_HEAP_START;
bitmap_init(&kernel_vaddr.vaddr_bitmap);
put_str(" mem_pool_init done\n");
}
// 内存管理部分的初始化入口
void mem_init() {
put_str("mem_init start\n");
uint32_t mem_bytes_total = (*(uint32_t*)(0xb00)); // 0xb00 是 loader.S 中定义的 mem_bytes_total 存储总内存容量
mem_pool_init(mem_bytes_total); // 初始化内存池
put_str("mem_init done\n");
}
图解
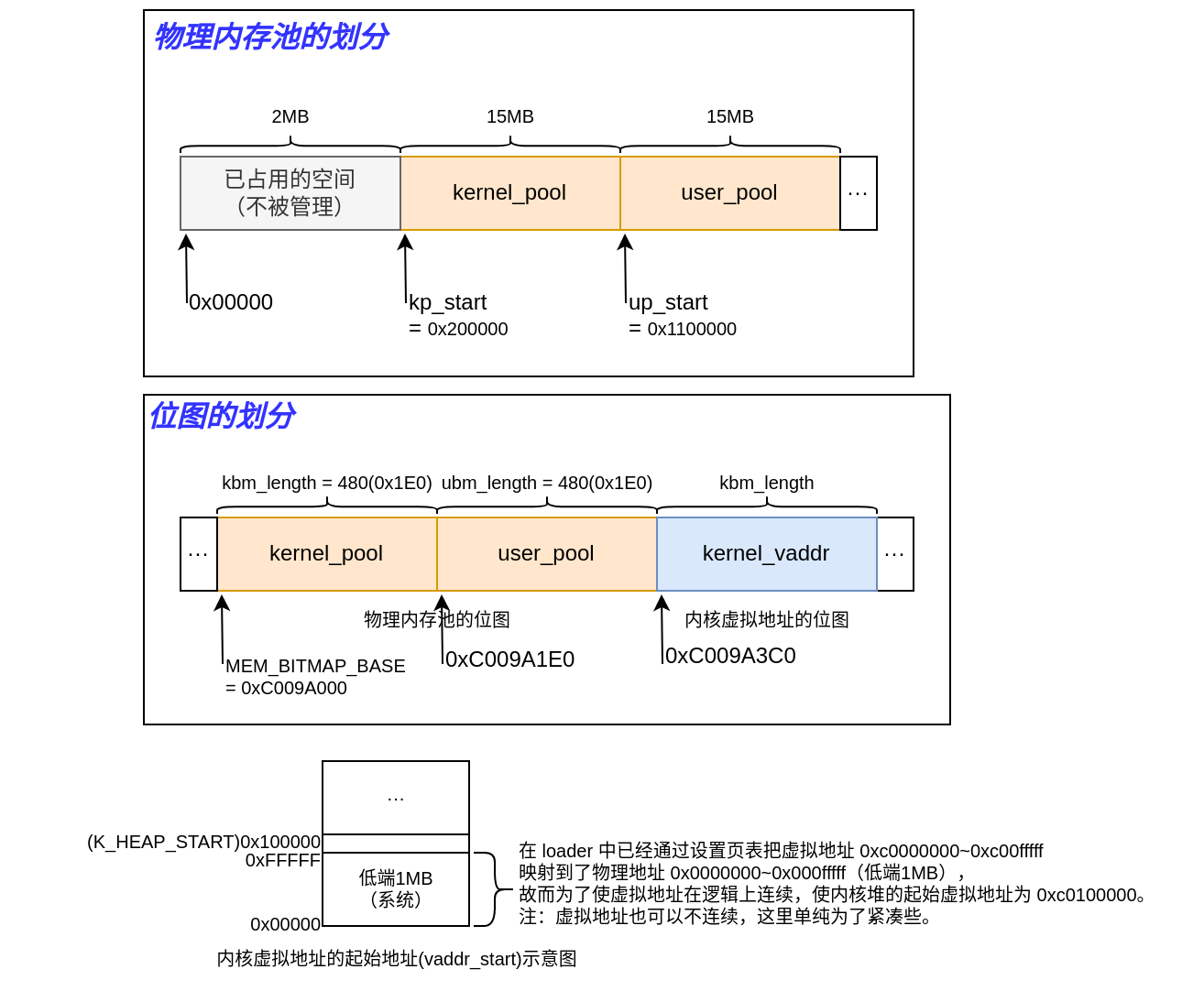
// 虚拟机设置总内存为 all_mem = 32MB
uint32_t page_table_size = PG_SIZE * 256
= 4096 * 256 = 1048576
= 1MB
uint32_t used_mem = page_table_size + 0x100000
= 1MB + 0x100000
= 2MB
uint32_t free_mem = all_mem - used_mem
= 32MB - 2MB
= 30MB
uint16_t all_free_pages = free_mem / PG_SIZE
= 30MB / 4096
= 7680
uint16_t kernel_free_pages = all_free_pages / 2
= 7680 / 2
= 3840
uint16_t user_free_pages = all_free_pages - kernel_free_pages
= 7680 - 3840
= 3840
uint32_t kbm_length = kernel_free_pages / 8
= 3840 / 8
= 480
uint32_t ubm_length = user_free_pages / 8
= 480
uint32_t kp_start = used_mem
= 2MB
= 0x200000
uint32_t up_start = kp_start + kernel_free_pages * PG_SIZE
= 2MB + 3840 * 4096
= 0x200000 + 0xF00000(15MB)
= 0x1100000
PCB
-
PCB 程序控制块
-
本书 PCB 实现方式占用一页内存,即 PCB 要 4KB。
-
PCB 所占用的内存必须是自然页。
自然页就是页的起始地址必须是
0xXXXXX000,终止地址必须是0xXXXXXFFF。也就是不能跨页占用,PCB 必须是完整、单独地占用一个物理页框。 -
任何一个进程都包含一个 PCB 结构。
假设 PCB 地址是 0xXXXXX000:
- 在 PCB 的最低处
0xXXXXX000以上存储的是进程或线程的信息。 - 在 PCB 的最高处
0xXXXXXFFF以下用于进程或线程在 0 特权级下所使用的栈。
为什么 MEM_BITMAP_BASE 是 0xc009a000 ?
去看代码中的注释。
为什么要将位图放在低端 1MB 以下呢?
内存中已经被占用的内存空间不需要被内存管理系统所管理,一般的内存管理系统所管理的都是那些空闲内存,也就是说已经被使用的内存是不在内存池中的。因为低端 1MB 的内存几乎已经被占用了,因此也不需要管理它了。
位图为什么不用变长数组来实现?
既然位图的长度并不固定,是否可以用变长数组来实现?变长数组只在 C99 中支持,并且数组占用的内存是堆空间,而且那还需要操作系统的支持,而我们目前所做的正是在构建操作系统,而我们的内存管理系统,其实也是在构建堆内存管理,我们的两个内存池就相当于堆。
分配内存
kernel/memory.h:
/* 内存池标记,用于判断用哪个内存池 */
enum pool_flags {
PF_KERNEL = 1, // 内核内存池
PF_USER = 2 // 用户内存池
};
#define PG_P_1 1 // 页表项或页目录项存在属性位
#define PG_P_0 0 // 页表项或页目录项存在属性位
#define PG_RW_R 0 // R/W 属性位值, 读/执行
#define PG_RW_W 2 // R/W 属性位值, 读/写/执行
#define PG_US_S 0 // U/S 属性位值, 系统级
#define PG_US_U 4 // U/S 属性位值, 用户级
kernel/memory.c:
#define PG_SIZE 4096
#define PDT_IDX(addr) ((addr & 0xffc00000) >> 22) // 获取 addr 的高 10 位
#define PTE_IDX(addr) ((addr & 0x003ff000) >> 12) // 获取 addr 的中间 10 位
/* 0xc0000000是内核从虚拟地址3G起. 0x100000意指跨过低端1M内存,使虚拟地址在逻辑上连续 */
#define K_HEAP_START 0xc0100000
// 内存池结构
struct pool {
struct bitmap pool_bitmap; // 该内存池所用到的位图结构,用于管理物理内存
uint32_t phy_addr_start; // 该内存池所管理物理内存的起始地址
uint32_t pool_size; // 该内存池字节容量
};
struct pool kernel_pool, user_pool; // 内核物理内存池和用户物理内存池
struct virtual_addr kernel_vaddr; // 用于给内核分配虚拟地址
// 在 pf 所表示的内存池中申请 pg_cnt 个虚拟页
// 成功时返回虚拟页的起始地址,失败则返回 NULL
static void* vaddr_get(enum pool_flags pf, uint32_t pg_cnt) {
int vaddr_start = 0, bit_idx_start = -1;
uint32_t cnt = 0;
if(pf == PF_KERNEL) { // 内核内存池
bit_idx_start = bitmap_scan(&kernel_vaddr.vaddr_bitmap, pg_cnt);
if(bit_idx_start == -1) {
return NULL;
}
while(cnt < pg_cnt) {
bitmap_set(&kernel_vaddr.vaddr_bitmap, bit_idx_start + cnt++, 1);
}
vaddr_start = kernel_vaddr.vaddr_start + bit_idx_start * PG_SIZE;
} else { // 用户内存池
// ...
}
return (void*) vaddr_start;
}
// 得到虚拟地址 vaddr 对应的 PTE 指针
uint32_t* pte_ptr(uint32_t vaddr) {
// 访问页目录的最后一个 PDE,将当前页目录表当成页表
// 利用 vaddr 的高 10 位,去找到真正的页表的物理地址(按处理器的思想,这步得到的应该是物理页的物理地址,但这里我们将其看成真正的页表物理地址)
// 利用 vaddr 的中间 10 位,作为页表的偏移量,从而找到 vaddr 对应的 PTE
uint32_t* pte = (uint32_t*)(0xffc00000 + \
((vaddr & 0xffc00000) >> 10) + \
PTE_IDX(vaddr) * 4);
}
// 得到虚拟地址 vaddr 对应的 PDT 指针
uint32_t* pde_ptr(uint32_t vaddr) {
uint32_t* pde = (uint32_t*) ((0xfffff000) + PDT_IDX(vaddr) * 4);
return pde;
}
// 在 m_pool 指向的物理内存池中分配一个物理页
// 返回页框的物理地址,否则返回 NULL
static void* palloc(struct pool* m_pool) {
// 扫描或设置位图要保证原子操作
int bit_idx = bitmap_scan(&m_pool -> pool_bitmap, 1); // 找到一个物理页
if(bit_idx == -1) return NULL;
bitmap_set(&m_pool -> pool_bitmap, bit_idx, 1); // 设置该位使用状态为:已使用
uint32_t page_phyaddr = ((bit_idx * PG_SIZE) + m_pool -> phy_addr_start);
return (void*) page_phyaddr;
}
// 页表中添加虚拟地址 _vaddr 与物理地址 _page_phyaddr 的映射
static void page_table_add(void* _vaddr, void* _page_phyaddr) {
uint32_t vaddr = (uint32_t) _vaddr, page_phyaddr = (uint32_t) _page_phyaddr;
uint32_t* pde = pde_ptr(vaddr);
uint32_t* pte = pte_ptr(vaddr);
// 判断页目录项中的 P 位是否为 1,即判断 PDE 是否存在
if(*pde & 0x00000001) { // 存在
ASSERT(!(*pte & 0x00000001));
// 判断 PTE 是否存在
if(!(*pte & 0x00000001)) { // 不存在
*pte = (page_phyaddr | PG_US_U | PG_RW_W | PG_P_1);
} else {
// 这个分支,我个人感觉压根没存在的必要
// 因为 PTE 是不存在才创建,而这个分支表示已存在,那还创建个屁?
PANIC("pte repeat");
*pte = (page_phyaddr | PG_US_U | PG_RW_W | PG_P_1);
}
} else { // 不存在
// 页表中用到的页框一律从内核内存池分配
// PDE 不存在,自然 PTE 页不存在则需要创建一个新的页表
uint32_t pde_phyaddr = (uint32_t) palloc(&kernel_pool);
*pde = (pde_phyaddr | PG_US_U | PG_RW_W | PG_P_1);
memset((void*)((int)pte & 0xfffff000, 0, PG_SIZE)); // 避免脏读
ASSERT(!(*pte & 0x00000001));
*pte = (page_phyaddr | PG_US_U | PG_RW_W | PG_P_1);
}
}
// 分配 pg_cnt 个页空间,返回虚拟地址,否则 NULL
void* malloc_page(enum pool_flags pf, uint32_t pg_cnt) {
ASSERT(pg_cnt > 0 && pg_cnt < 3840);
void* vaddr_start = vaddr_get(pf, pg_cnt);
if(vaddr_start == NULL) return NULL;
uint32_t vaddr = (uint32_t) vaddr_start, cnt = pg_cnt;
struct pool* mem_pool = pf & PF_KERNEL ? &kernel_pool : &user_pool;
// 因为虚拟地址是连续的,但物理地址可以是不连续的,所以要逐个做映射
while(cnt-- > 0) {
void* page_phyaddr = palloc(mem_pool);
if(page_phyaddr == NULL) { // 若其中一块分配失败,则回滚之前分配的空间
// 待实现...
return NULL;
}
page_table_add((void*) vaddr, page_phyaddr); // 在页表中做映射
vaddr += PG_SIZE; // 下一个虚拟页
}
return vaddr_start;
}
// 从内核物理内存池中申请 pg_cnt 页内存,返回虚拟地址,否则返回 NULL
void* get_kernel_pages(uint32_t pg_cnt) {
void* vaddr = malloc_page(PF_KERNEL, pg_cnt);
if(vaddr != NULL) { // 若分配的地址不为空,先将页框清 0,避免脏读
memset(vaddr, 0, pg_cnt * PG_SIZE);
}
return vaddr;
}
kernel/main.c:
int main(void) {
put_str("I am kernel\n");
init_all();
void* addr = get_kernel_pages(3); // 申请三个页的内核空间
put_str("\n get_kernel_get start vaddr is ");
put_int((uint32_t) addr);
put_str("\n");
while(1);
return 0;
}















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









