







 文章详细阐述了Java中String对象的创建和内存分配过程,包括字面量赋值、new关键字创建以及“+”运算和intern()方法的使用。通过实例展示了不同情况下JVM内存中字符串的存储位置,强调了字符串常量池和堆内存的区别,以及如何影响对象引用的指向。
文章详细阐述了Java中String对象的创建和内存分配过程,包括字面量赋值、new关键字创建以及“+”运算和intern()方法的使用。通过实例展示了不同情况下JVM内存中字符串的存储位置,强调了字符串常量池和堆内存的区别,以及如何影响对象引用的指向。
String str = “test”
用一段代码来举例:为一个String对象赋值一个字符串字面量“test”:
在启动项目时,在JVM类加载过程的“加载”阶段,当扫描到字节码文件中的“test”字面量时,JVM会把这个字面量存放在运行时常量池中。
然后在“解析”阶段,JVM会根据运行时常量池中的这个字符串字面量,在堆中创建出对应的String类对象,然后再把它的引用值存入到字符串常量池中。
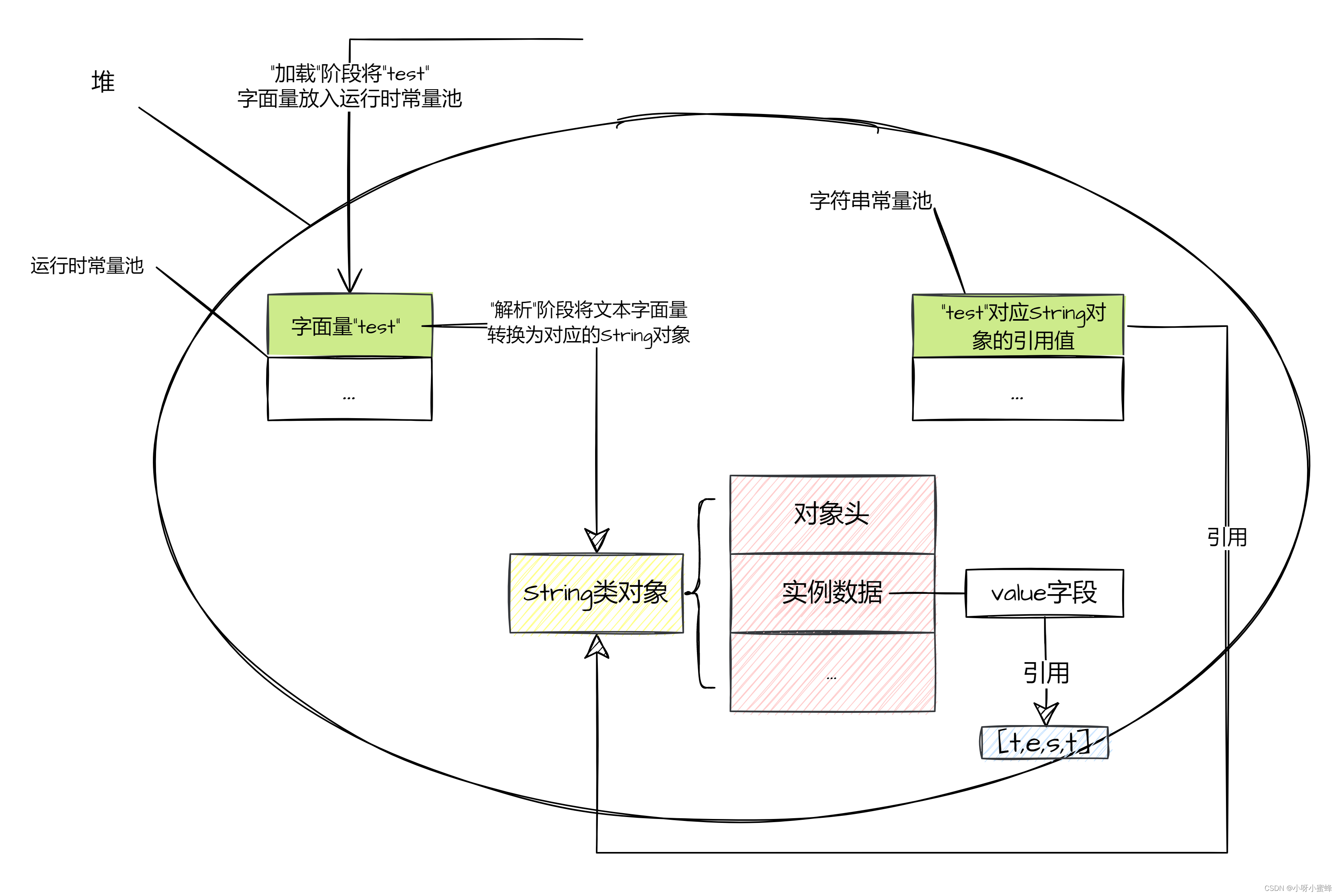
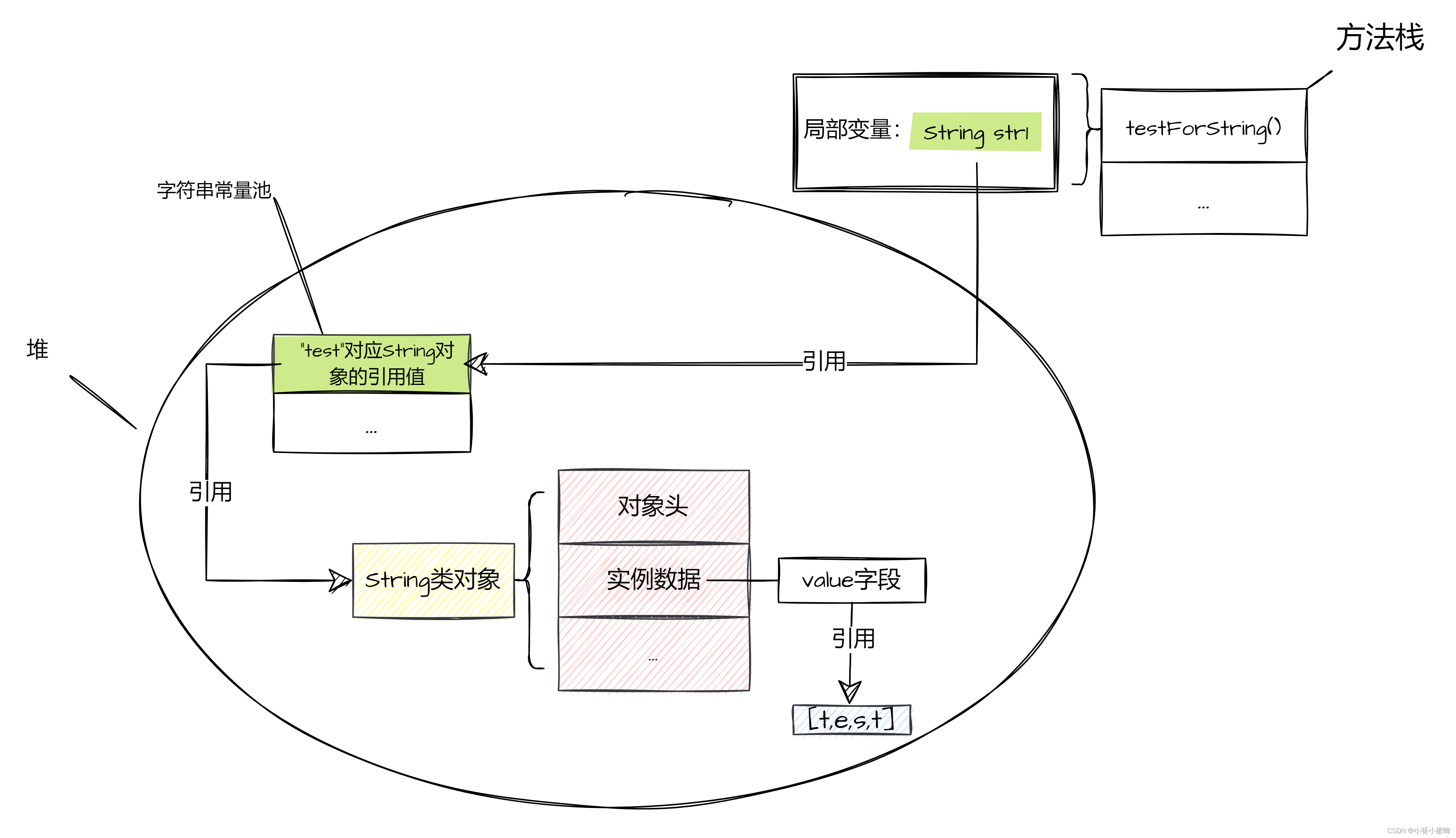
当JVM在执行如上的testForString()方法时,会将testForString()方法入栈,然后在对应的栈帧中存上局部变量String str1。
其中,str1被赋值的是字符串常量池中内容为“test”的String类对象的引用。
现在举例下面的代码,我们定义两个变量str1和str2,并且都为它们赋值同一个字面量“test”,通过str1==str2这段代码来看看这两个变量是不是都指向的是同一个内存空间。

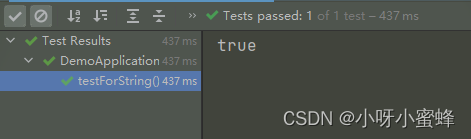
可以看到输出结果为true,这说明str1和str2指向的是同一个内存空间。
我们来图解一下此时JVM内存的数据分布:
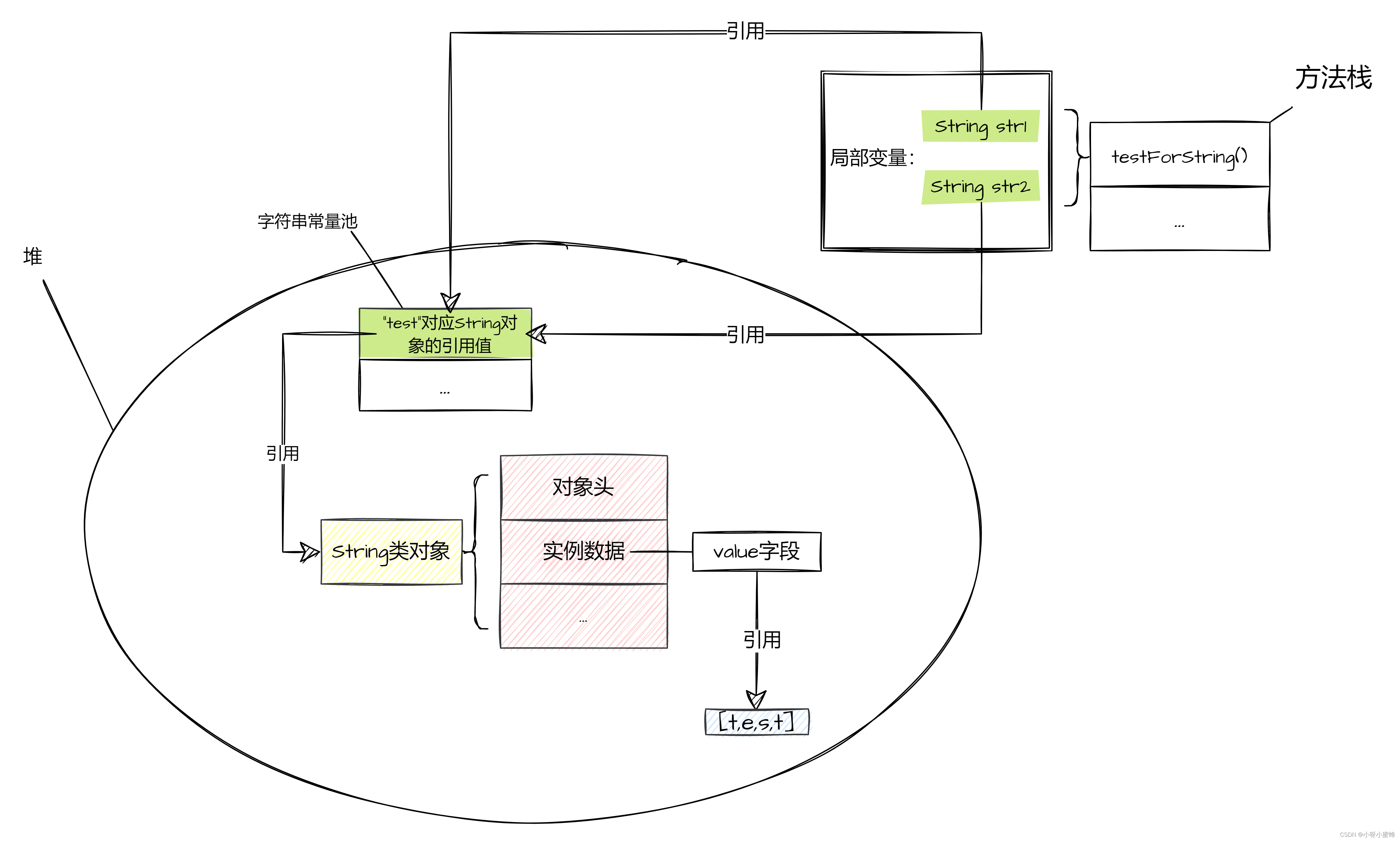
可以看到,此时变量str1和str2被赋值的都是同一个内存空间的引用地址。
String str = new String()
对String对象的赋值还有一种情况,那就是: new String()。
我们来看看下面这段代码:
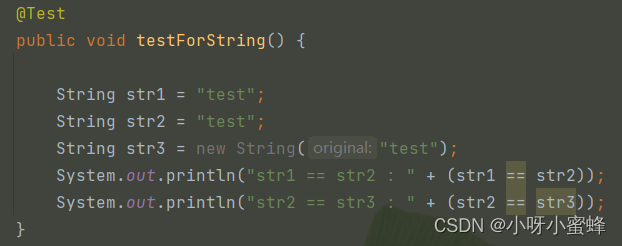
输出看一下结果:
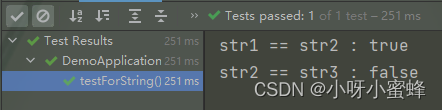
可以注意到,str1和str2指向的都是同一个内存的空间,而str3却单独指向了一个别的内存空间。
来找找原因。
看如下代码:
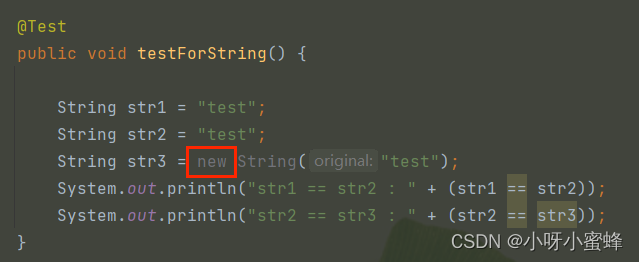
在执行new关键词时,JVM会在堆中创建一个类型为String的对象,然后执行这个对象的构造方法。
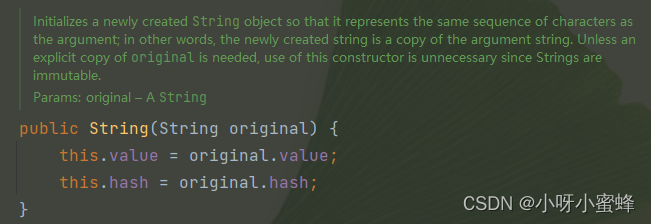

从java.lang.String#String(java.lang.String)方法中可以看到,形参的value字段被赋值给了这个String类对象的value字段。
可以知道,此时JVM的内存分布大概是这个样子:
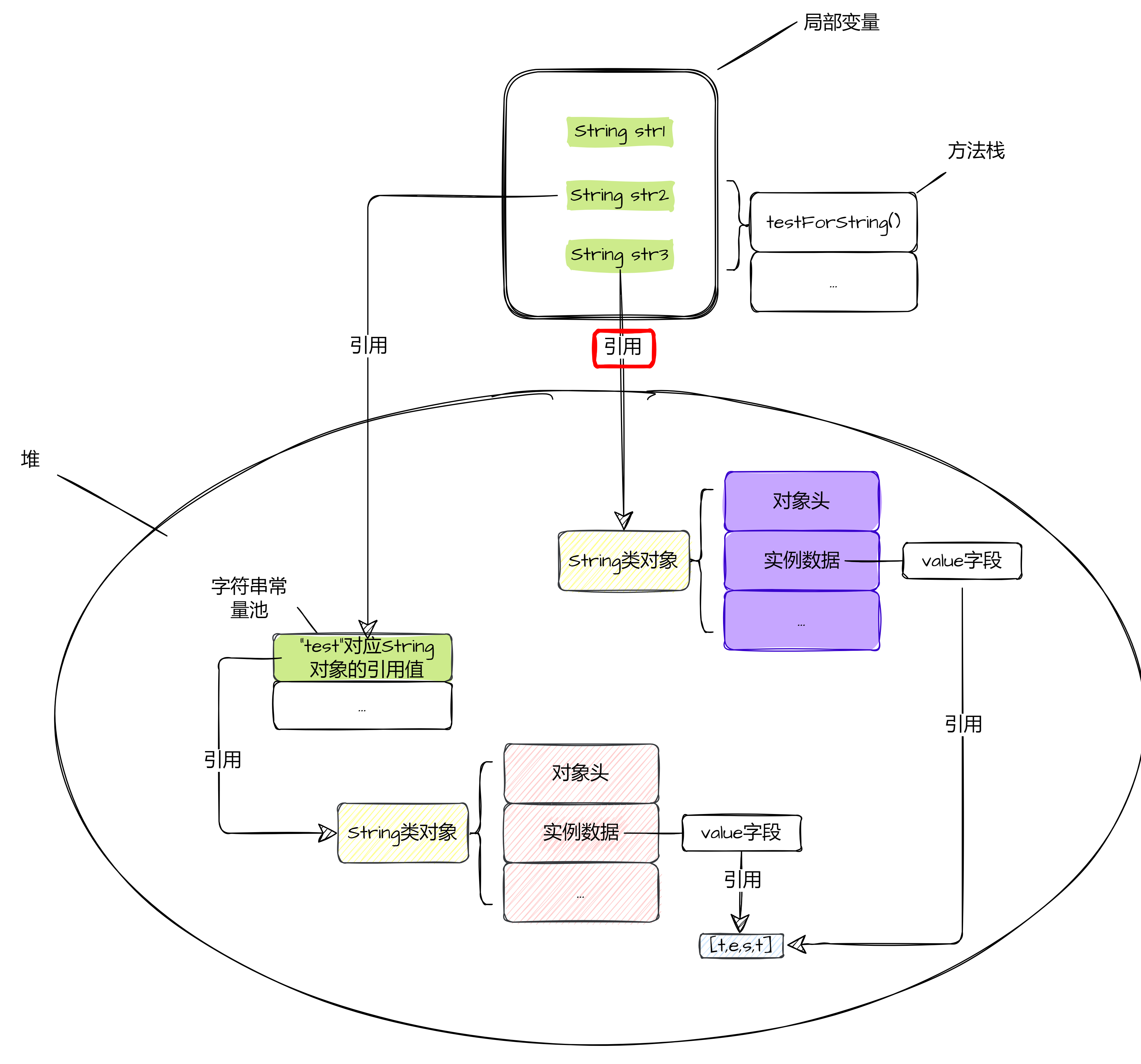
所以可以得知,str3变量实际上引用的是堆中的一个新被创建的String类对象,所以这也就解释了为什么变量str3和str2指向的不是同一个内存空间的原因。
这是因为,str3指向的是堆中的新对象,而str2则是指向的字符串常量池中的引用地址。
它们的共同点,也就只有value字段引用的是同一个内存的空间。
“+”运算
对String对象的赋值还可以使用“+”运算。
在讲解之前,我们需要先要了解JVM对于字符串的“+”运算会做哪些处理。
JVM中,字符串的“+”运算有2个规则:
- 如果“+”字符串运算的操作数不是在编译期间就被确定的,那么JVM就会自动把“+”替换成StringBuilder的append和toString方法。
- 如果两个操作数在编译期间都已经被完全确定,比如操作数都是String字面量,那么JVM就不会把“+”转换为StringBuilder的append()方法,而是会直接将这2个字面量连接起来,然后根据连接的结果字面量再在堆中创建一个新的String对象,最后再将这个引用地址存到字符串常量池里。
现在我们举例如下代码:
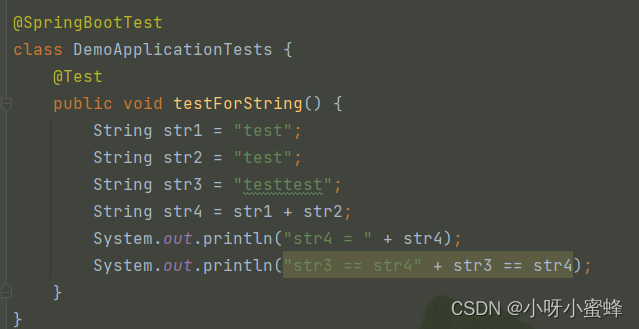
输出结果:
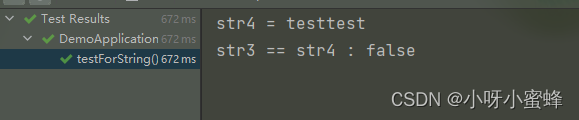
可以看到,变量str4的值是“testtest”,而str3的值也是“testtest”,但是这2个变量指向的却不是同一个内存空间。
这是为什么呢?
由于字符串“+”运算的规则,对于代码String str4 = str1 + str2,由于操作数str1和str2并不是在编译期间就被确定的,所以JVM就会自动把“+”替换成StringBuilder的append和toString方法。
也就是说,代码:
String str4 = str1 + str2;
被替换成了:
String str4 = new StringBuilder().append(str1).append(str2).toString();
所以代码编译后,实际上源代码的内容大概变成了下面这个样子:
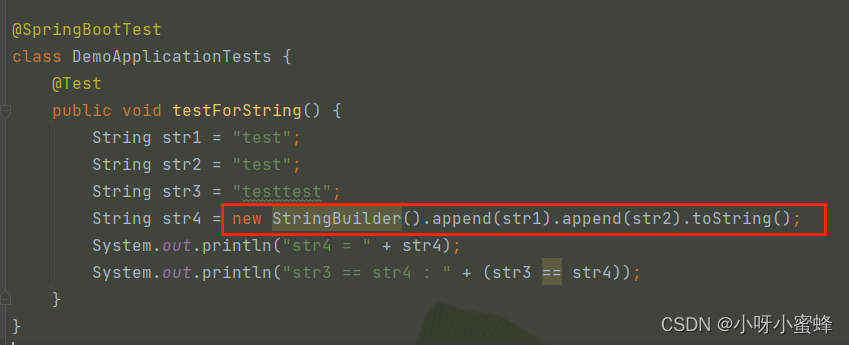
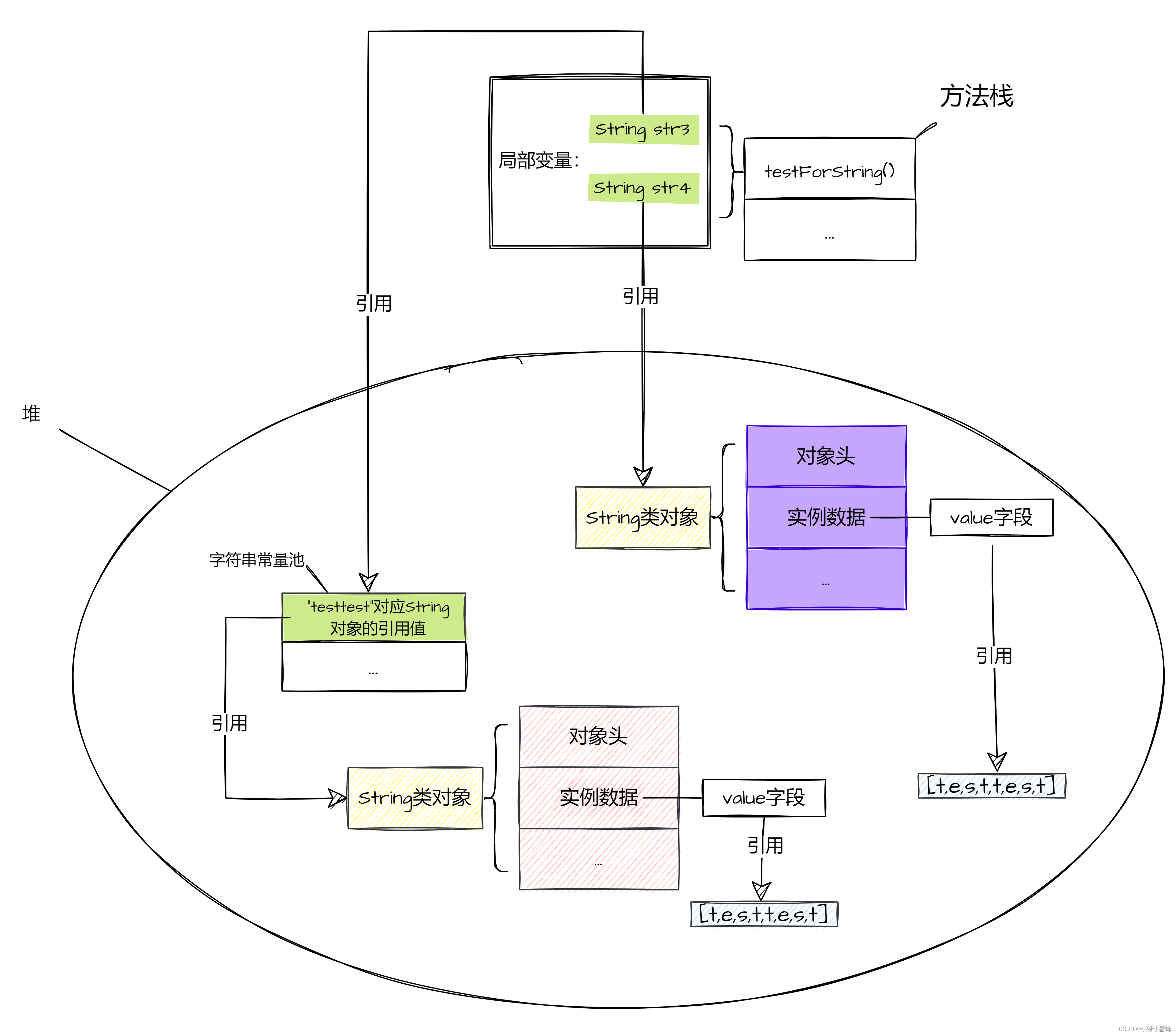
所以可以知道,str1 + str2运算实际上会为变量str4在内存堆中新建一个StringBuilder类型的对象,然后通过这个对象的toString()方法,在内存堆中再新建一个String类对象,最后让str4引用这个对象。
这就是为什么str3和str4不是指向的同一个内存空间的原因。
因为str3引用的是字符串常量池的String类对象,而str4则是引用的堆中的一个新String类对象:
注意,Java编译器中还有一个优化特性:常量折叠。
“常量折叠”的作用就是在代码编译期间将用到final变量的地方替换成这个变量对应的实际值。
比如如下这个代码:
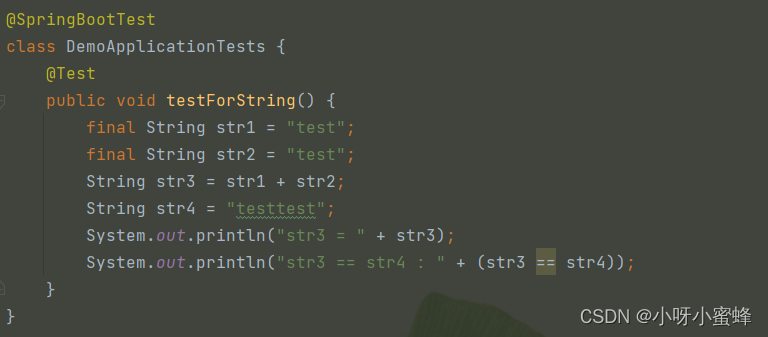
那么在项目编译时,原代码:
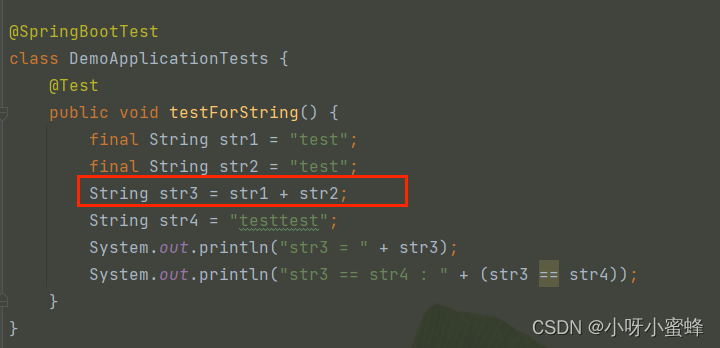
就变成了:
现在我们来执行一下上面的代码,看看此时的结果会是怎样的:
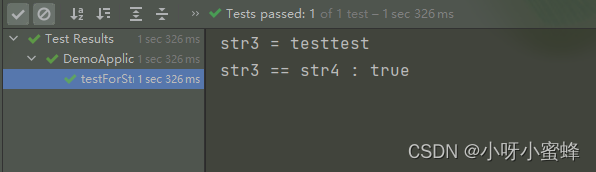
可以看到str3和str4指向的是同一个内存空间。
这是为什么呢?
对于代码String str3 = “test” + “test”,由于这2个操作数在编译期间就被确定为"test",所以JVM就不会把“+”转换为StringBuilder的append()方法,而是会直接将这2个字面量连接起来,然后再把对应的引用地址保存到字符串常量池里。
所以此时的内存数据布局大概如下所示:
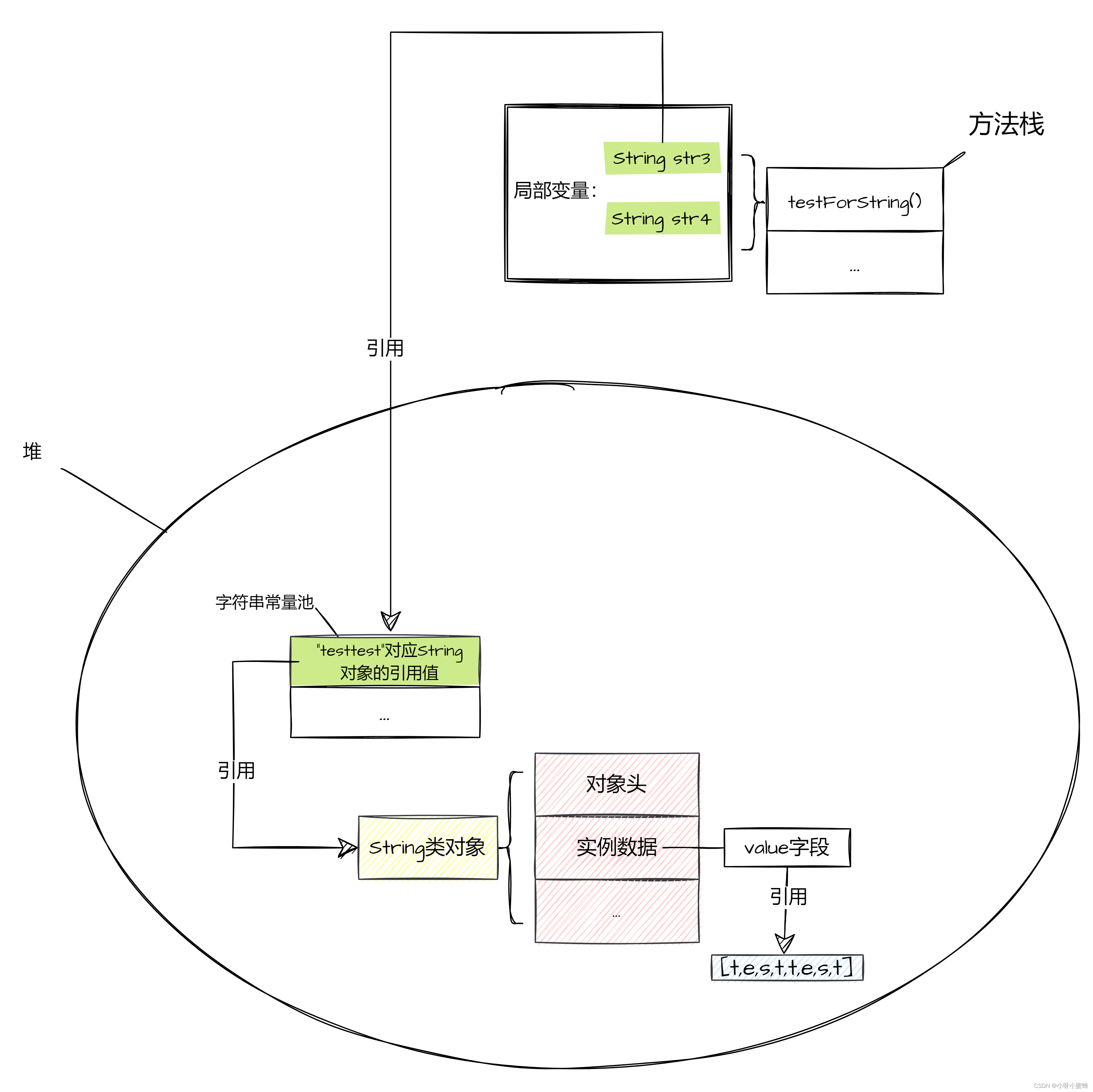
可以看到这个时候字符串常量池中已经有了“testtest”内容的String对象的引用了,所以当执行String str4 = "testtest"代码时,就可以直接把常量池中的这个引用拿来直接赋值给str4。
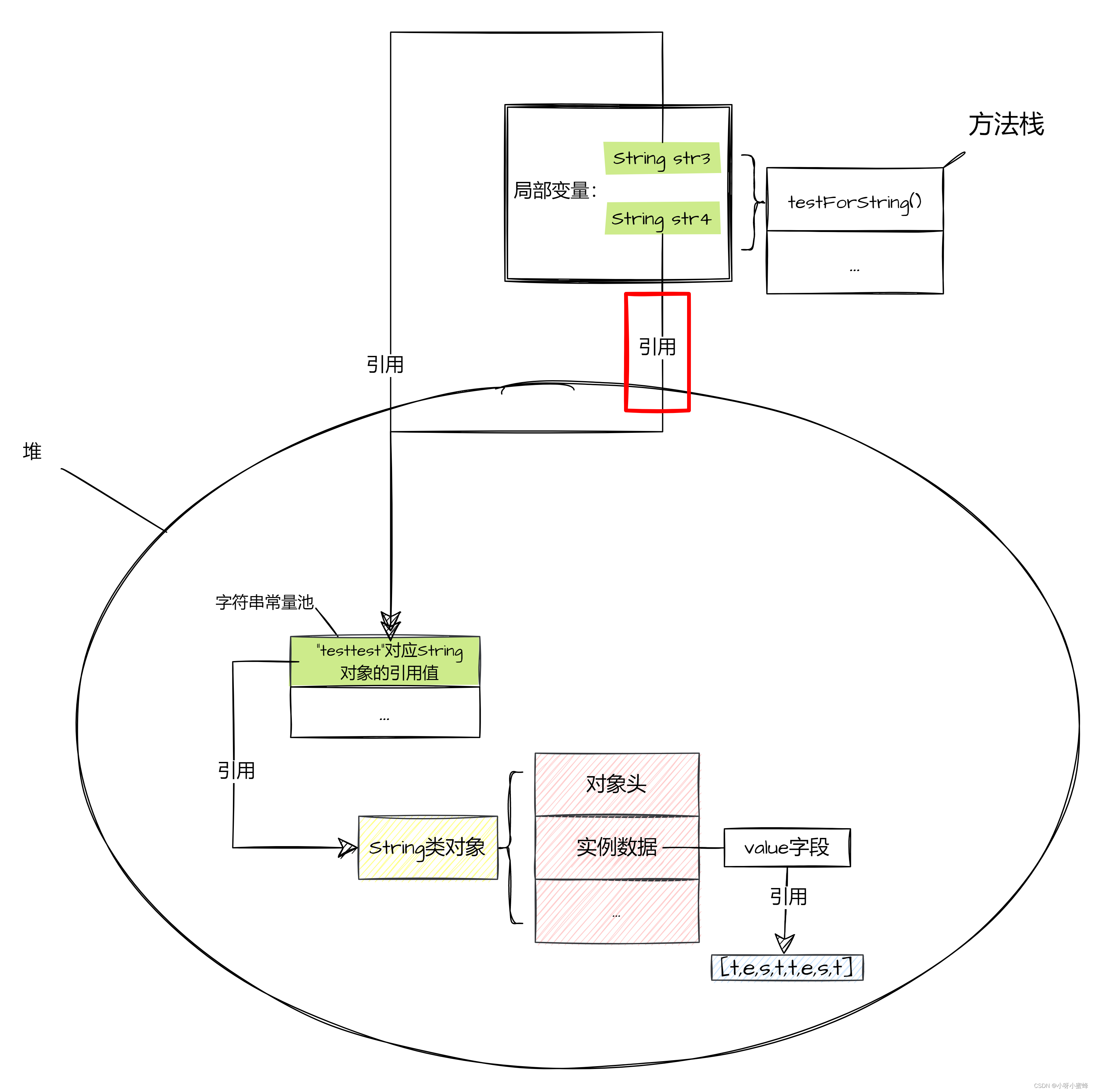
这就是为什么str3和str4指向的是同一个内存空间的原因。
.intern()
String变量还可以使用java.lang.String#intern方法类来赋值。
我们来看看这个方法的源码:

官方文档解释:当intern方法被调用时,如果此时常量池中已经包含有和String类对象同样文本内容的String,那么就会返回常量池中的这个String,如果没有包含,那么就会在常量池中存入这个文本内容的String,然后返回它的引用。
我们以下面代码举例:
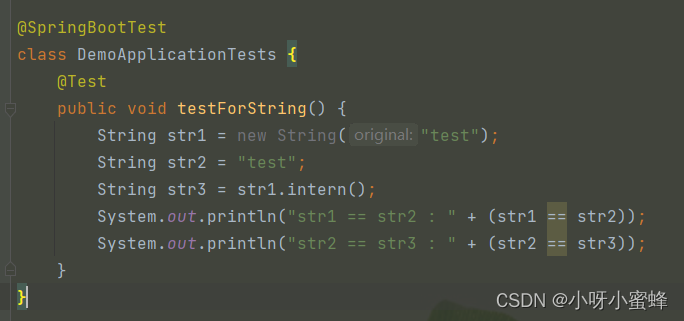
输出结果:
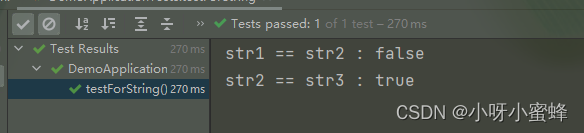
可以看到,str1和str2指向的不是同一个内存空间,而str2和str3则是指向的同一个内存空间。
我们来解释一下为什么会导致这种结果。
我们知道,在类加载过程结束后,JVM内存数据布局大概会是如下所示:
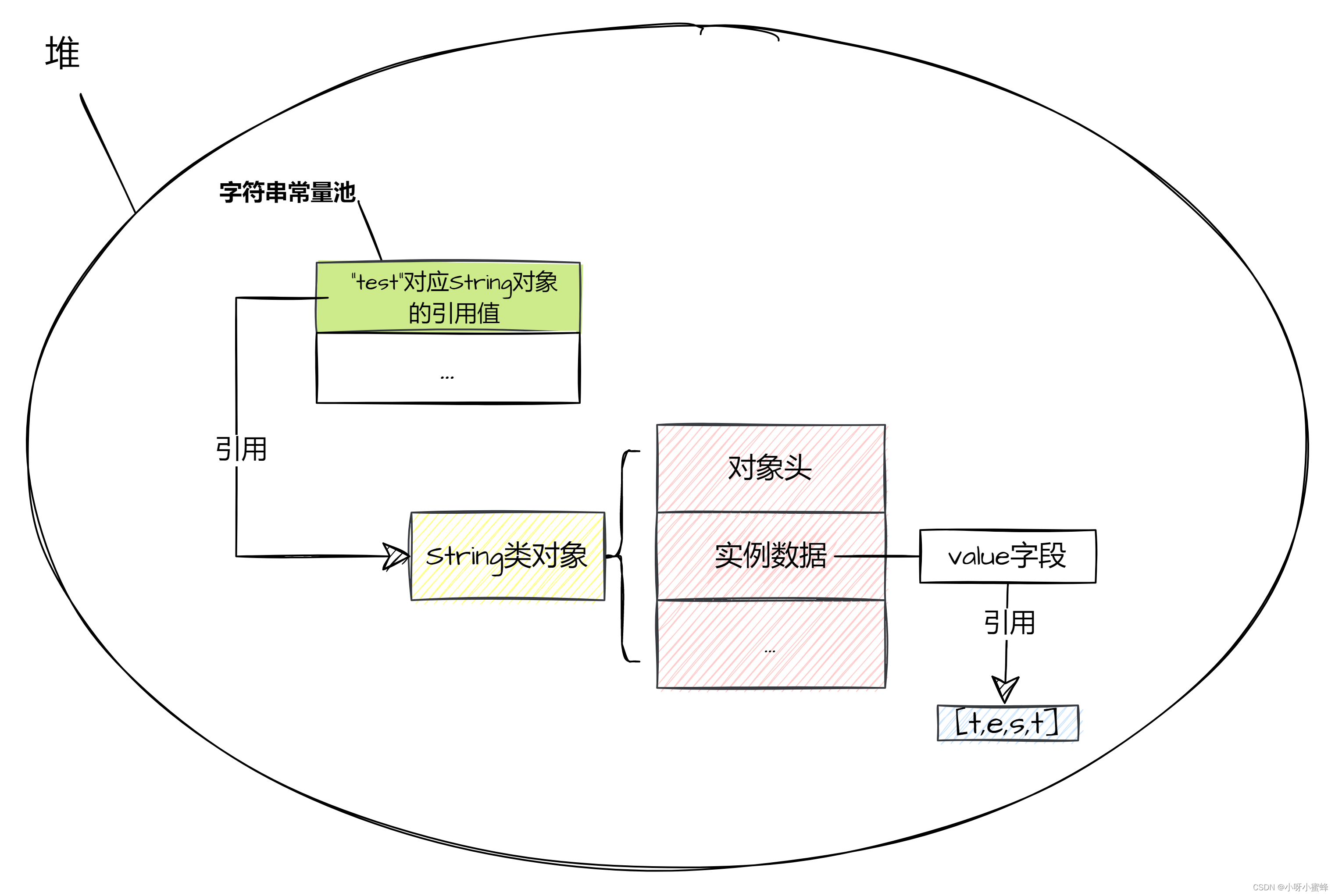
可以看到,此时字符串常量池中已经存放有了对“test”内容的String类对象的引用。
然后JVM开始准备执行方法。
将方法入栈,先执行这段代码:

此时JVM会在堆内存中新建一个String对象,并让str1变量引用这个对象的引用:
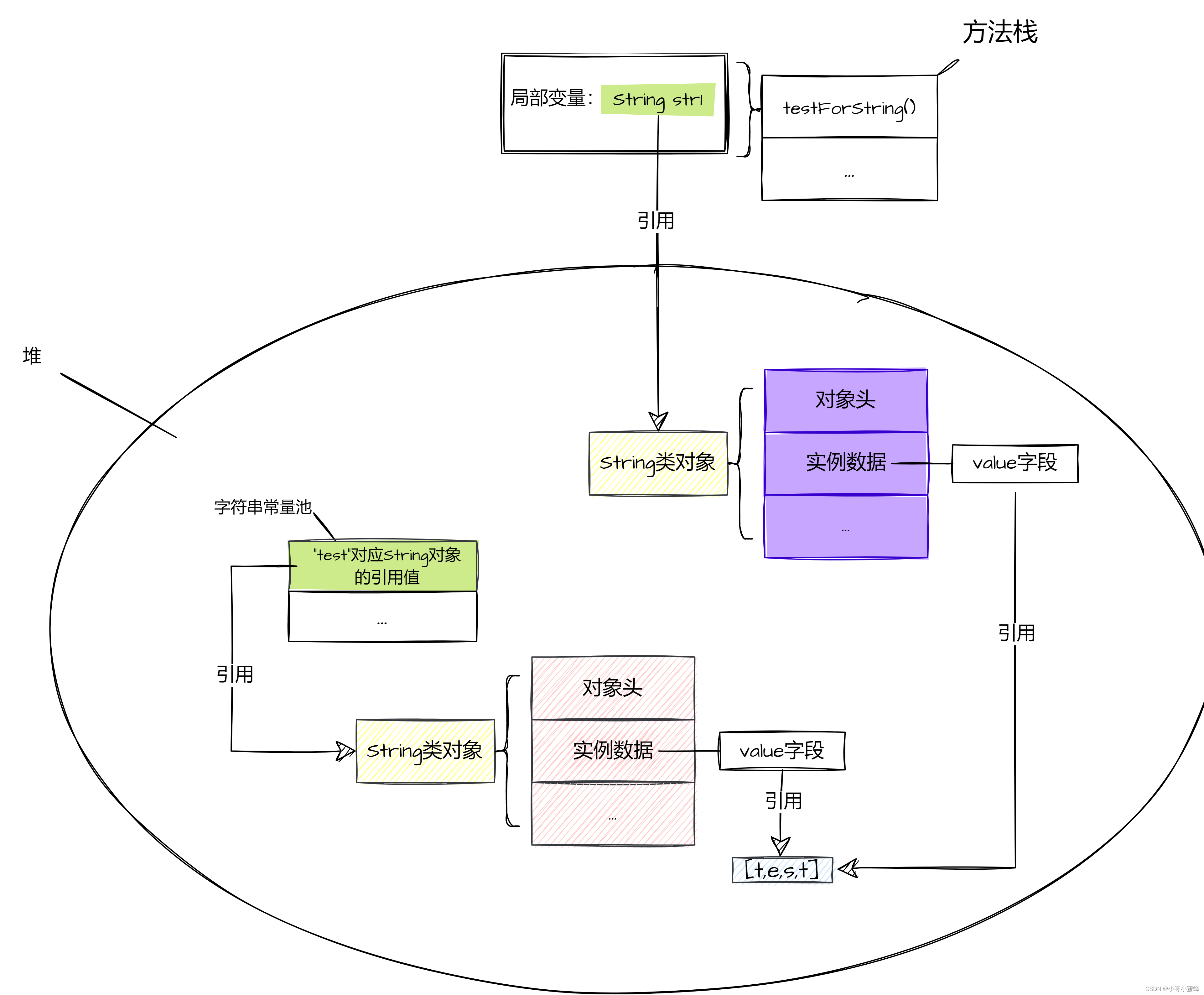
在赋值完变量str1后,JVM接着执行代码:

str2会直接引用常量池中的“test”内容String类对象的引用值:
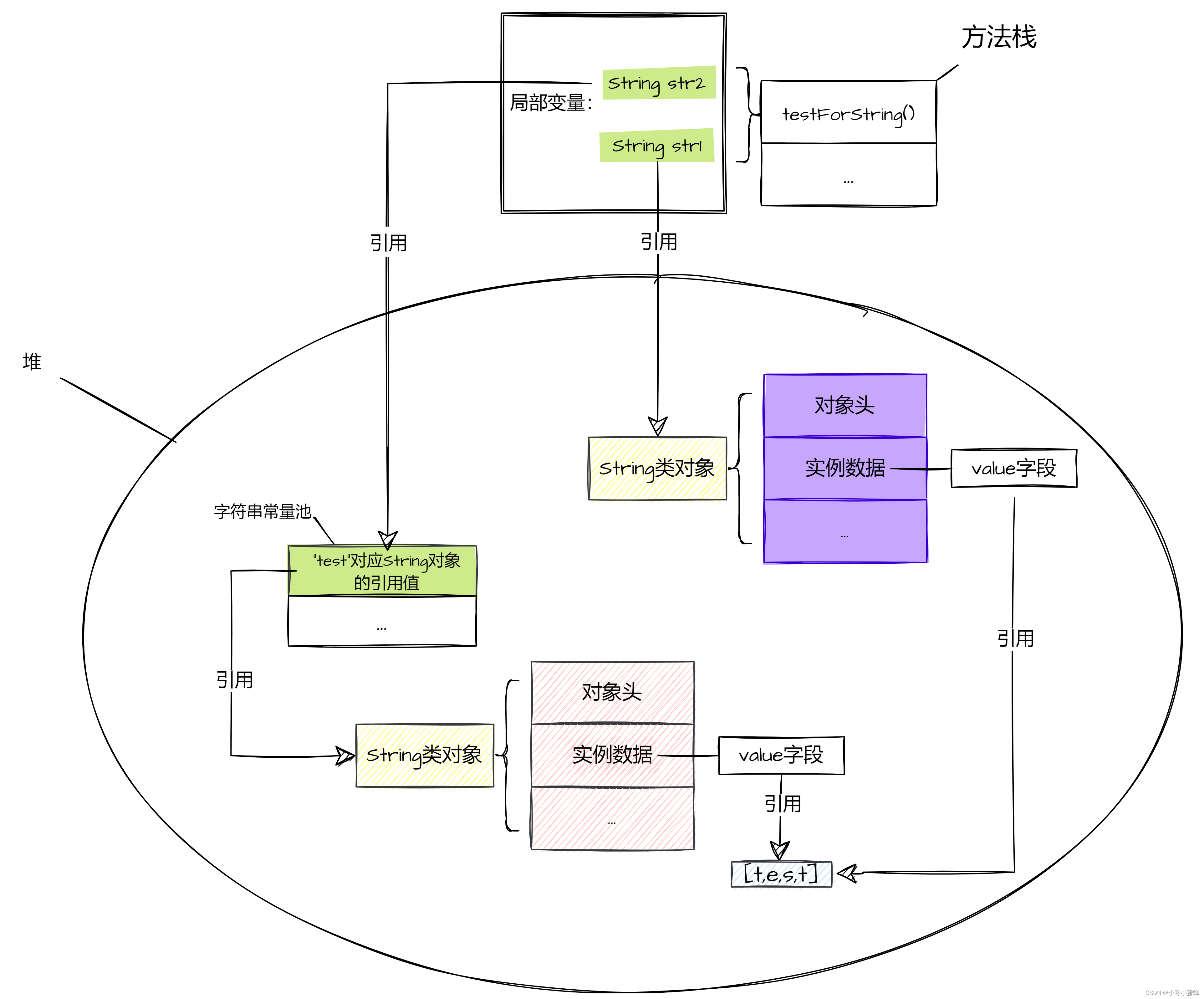
然后,接着执行代码:
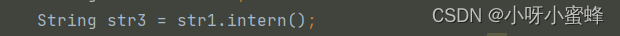
由于执行intern方法,所以JVM会先去常量池中查找有没有和str1同样文本内容的String类对象的引用。就像查表一样,通过文本内容来查找是否能够匹配到具有相同文本内容的记录。
由于在类加载的时候,常量池中就已经有了对“test”内容的String类对象的引用,所以此时intern方法就会直接返回常量池中的这个引用值,然后赋值给变量str3:
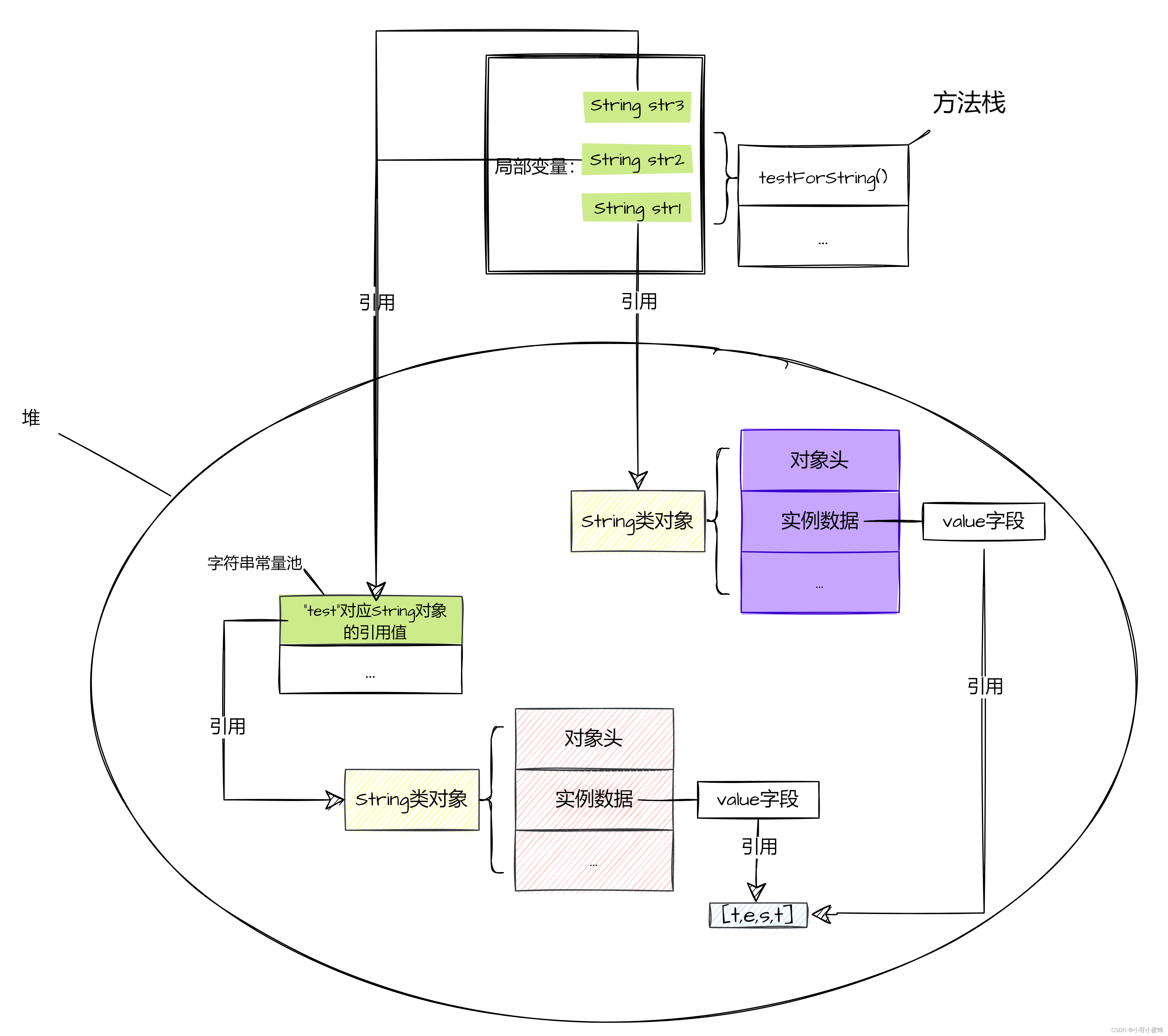
所以这就是为什么变量str2和str3指向的是同一个内存空间的原因。

















 1485
1485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









