







一、散列算法
基于主索引值将行分配给特定的AMP。
Teradata使用散列算法来确定哪个AMP获取行。
散列算法的高级图:
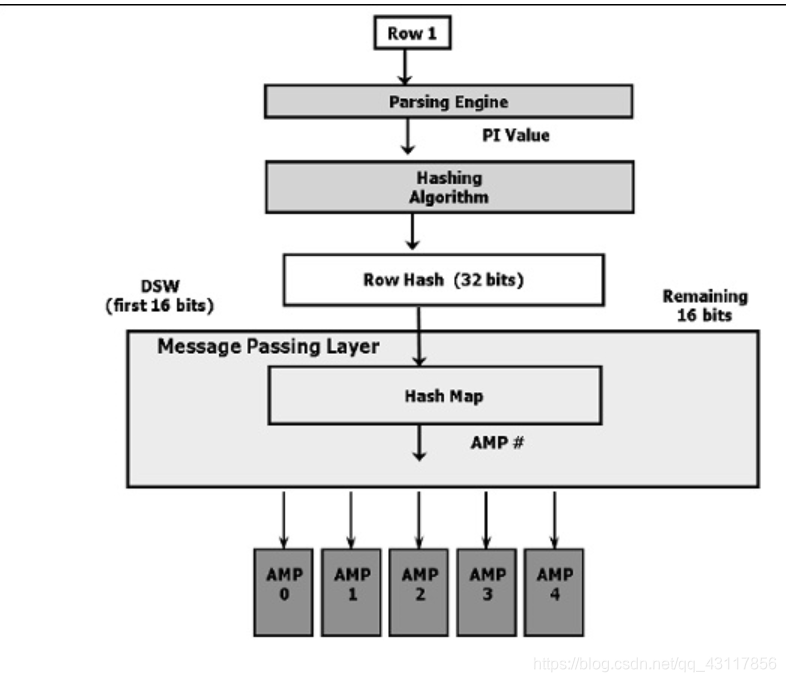
以下是插入数据的步骤:
1.客户端提交查询。
2.解析器接收查询并将记录的PI值传递给散列算法。
3.散列算法散列主索引值,并返回一个32位数,称为行散列。
4.BYNET将数据发送到标识的AMP。
5.AMP使用32位行散列来定位其磁盘中的行。
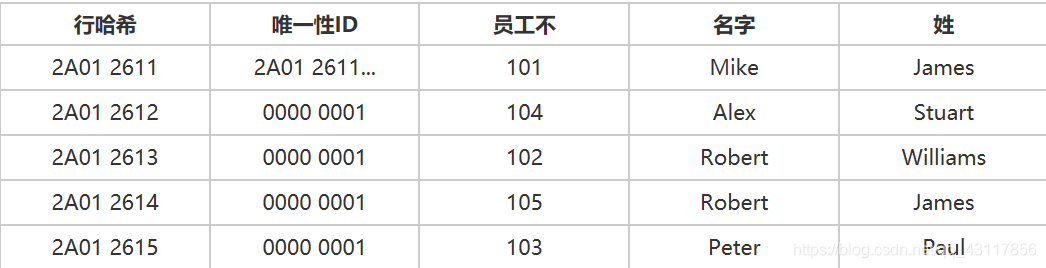
6.如果存在具有相同行散列的任何记录,则它递增作为32位数的唯一性ID。 对于新行散列,唯一性ID分配为1,并在每次插入具有相同行散列的记录时递增。行散列和唯一性ID的组合称为行ID,行ID为磁盘中的每个记录,AMP中的每个表行都按其行ID进行逻辑排序。
如何存储表
表按其行ID(行散列+唯一性id)排序,然后存储在AMP中。 行ID与每个数据行一起存储。
二、join索引
JOIN INDEX是一个物化视图。 其定义是永久存储的,并且只要更新连接索引中引用的基表,就会更新数据。
JOIN INDEX可以包含一个或多个表,并且还包含预聚合数据。 连接索引主要用于提高性能。
有不同类型的连接索引可用:
单表连接索引(STJI)
多表连接索引(MTJI)
聚合连接索引(AJI)
1.单表连接索引(STJI)
单表联接索引允许基于不同于基表中的主索引列来分区大表
语法:
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;
示例:在Employee表上创建名为Employee_JI的联接索引的示例
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);
如果用户在EmployeeNo上提交带有WHERE子句的查询,那么系统将使用唯一的主索引查询Employee表。 如果用户使用FirstName查询employee表,则系统可以使用FirstName访问连接索引Employee_JI。 连接索引的行在FirstName列上进行散列。
如果未定义连接索引且employee_name未定义为辅助索引,则系统将执行全表扫描以访问耗时的行。
可以运行以下EXPLAIN计划并验证优化程序计划
当表使用FirstName列查询时,优化程序正在使用Join Index而不是base Employee表。
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
。。。
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.
2.多表连接索引
通过连接多个表来创建多表连接索引。 多表连接索引可用于存储结果集的频繁连接的表以提高性能。
示例:
通过连接Employee和Salary表来创建一个名为Employee_Salary_JI的JOIN INDEX
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM
Employee a
INNER JOIN
Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);
每当更新基表Employee或Salary时,连接索引Employee_Salary_JI也会自动更新。
如果您正在运行连接Employee和Salary表的查询,则优化程序可以选择直接从Employee_Salary_JI访问数据,而不是连接表。
EXPLAIN计划对查询可以用来验证优化器是否会选择基表或Join索引。
3.聚合联接索引
如果表在某些列上始终聚合,则可以在表上定义聚合连接索引以提高性能。
聚合连接索引的一个限制是它仅支持SUM和COUNT函数。
示例:加入员工和工资以确定每个部门的总工资。
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);
三、视图
视图是由查询构建的数据库对象。 可以使用单个表或通过连接的多个表来构建视图。
它们的定义永久存储在数据字典中,但它们不存储数据的副本。
视图的数据是动态构建的。
视图可以包含表的行的子集或表的列的子集。
创建视图
视图是使用CREATE VIEW语句创建的
语法
CREATE VIEW <viewname>
AS
<select query>;
使用视图
可以使用常规SELECT语句从视图检索数据。
修改视图
可以使用REPLACE VIEW语句修改现有视图。
REPLACE VIEW <viewname>
AS
<select query>;
下降视图
可以使用DROP VIEW语句删除现有视图。
DROP VIEW <viewname>;
视图的优点
视图通过限制表的行或列来提供额外的安全级别。
用户只能访问视图而不是基表。
通过使用视图预联接多个表来简化其使用。
四、宏
宏是一组SQL语句,通过调用宏名称来存储和执行。
宏的定义存储在数据字典中。 用户只需要EXEC特权来执行宏。
用户不需要对宏中使用的数据库对象具有单独的特权。
宏语句作为单个事务执行。
如果宏中的某个SQL语句失败,则所有语句都将回滚。
宏可以接受参数。
宏可以包含DDL语句,但应该是宏中的最后一个语句。
创建宏
宏是使用CREATE MACRO语句创建的。
语法
CREATE MACRO <macroname> [(parameter1 data type, parameter2 data type,...)] AS (
<sql statements>
);
示例:
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);
执行宏:
使用EXEC命令执行
EXEC <macroname>;
参数化宏:
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);
EXEC Get_Emp_Salary(101);
五、存储过程
存储过程包含一组SQL语句和过程语句。
它们可能只包含程序性声明。
存储过程的定义存储在数据库中,参数存储在数据字典表中。
优点:
存储过程减少客户端和服务器之间的网络负载。
提供更好的安全性,因为通过存储过程访问数据,而不是直接访问它们。
提供更好的维护,因为业务逻辑被测试并存储在服务器中。
语法:
CREATE PROCEDURE <procedurename> ( [parameter1 data type, parameter2 data type..] )
BEGIN
<SQL or SPL statements>;
END;
考虑一下薪资表
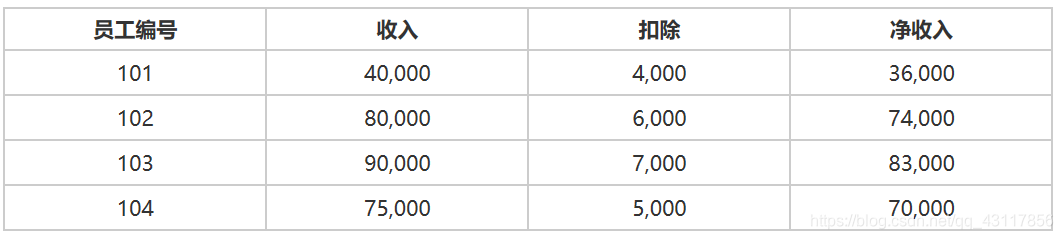
示例:
创建一个名为InsertSalary的存储过程以接受值并插入到Salary 表中
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;
执行存储过程:
CALL <procedure name> [(parameter values)];
CALL InsertSalary(105,20000,2000,18000); --在Salary表中插入行














 218
218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









