









索引用于帮助快速过滤或查找数据。
目前 Doris 主要支持两类索引:内建的智能索引,包括前缀索引和ZoneMap索引。用户创建的二级索引,包括Bloom Filter索引和Bitmap倒排索引。
其中ZoneMap索引是在列存格式上,对每一列自动维护的索引信息,包括Min/Max,Null值个数等等。这种索引对用户透明,不在此介绍。以下主要介绍其他三类索引。
前缀索引
原理
本质上,Doris 的数据存储在类似 SSTable(Sorted String Table)的数据结构中。该结构是一种有序的数据结构,可以按照指定的列进行排序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。
而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。
前缀索引是以Block为粒度创建的稀疏索引,一个Block包含1024行数据,每个Block,以该Block的第一行数据的前缀列的值作为索引。
我们将一行数据的前 36 个字节 作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。我们举例说明:
以下表结构的前缀索引为 user_id(8Byte) + age(4Bytes) + message(prefix 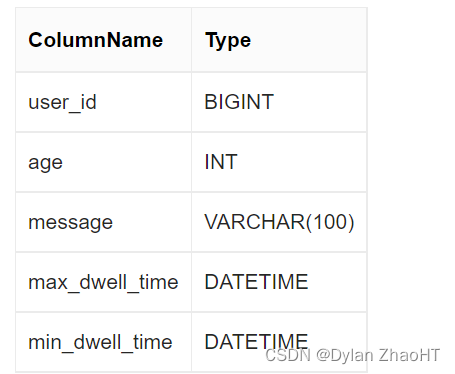
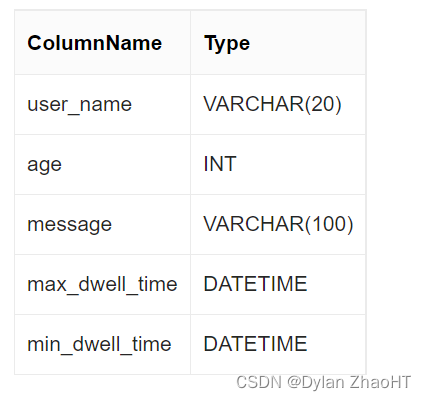
以下表结构的前缀索引为 user_name(20 Bytes)。即使没有达到 36 个字节,因为遇到 VARCHAR,所以直接截断,不再往后继续。
使用场景
当我们的查询条件,是前缀索引的前缀时,可以极大的加快查询速度。比如在第一个例子中,我们执行如下查询:
SELECT * FROM table WHERE user_id=1829239 and age=20;
该查询的效率会远高于如下查询:
SELECT * FROM table WHERE age=20;
所以在建表时,正确的选择列顺序,能够极大地提高查询效率。
Bloom Filter 索引
原理
用户可以在建表时指定在某些列上创建Bloom Filter索引(以下简称BF索引)。也可以在运行时通过 ALTER TABLE 命令新增BF索引。
Bloom Filter本质上是一种位图结构,用于快速的判断一个给定的值是否在一个集合中。这种判断会产生小概率的误判。即如果返回 False,则一定不在这个集合内。而如果范围 True,则有可能在这个集合内。
BF索引也是以Block为粒度创建的。每个Block中,指定列的值作为一个集合生成一个BF索引条目,用于在查询是快速过滤不满足条件的数据。
适用场景
由于Bloom Filter数据结构的特性,BF索引比较适合创建在高基数的列上,比如UserID。因为如果创建在低基数的列上,比如”性别“列,则每个Block几乎都会包含所有取值,导致BF索引失去意义。
Bitmap 索引
原理
用户可以在建表时指定在某些列上创建Bitmap索引。也可以在运行时通过 [ALTER TABLE](TODO) 命令新增Bitmap索引。
Bitmap索引是一种特殊的数据库索引技术,其索引使用bit数组(或称bitmap、bit set、bit string、bit vector)进行存储与计算操作。位置编码中的每一位表示键值对应的数据行的有无。一个位图可能指向的是几十甚至成百上千行数据的位置。
这种方式存储数据,相对于 B*Tree 索引,占用的空间非常小,创建和使用非常快。当根据键值查询时,可以根据Bitmap索引快速定位到具体的行号。而当根据键值做 and/or 或 in(x,y,…) 查询时,直接用索引的位图进行或运算,快速得出结果行数据。
Doris 中的Bitmap索引有如下限制
Bitmap 索引仅在单列上创建。
bitmap 索引支持的数据类型如下:
TINYINT
SMALLINT
INT
UNSIGNEDINT
BIGINT
CHAR
VARCHAR
DATE
DATETIME
LARGEINT
DECIMAL
BOOL
适用场景
适用于低基数的列上,建议在100到100000之间,如:职业、地市等。基数太高则没有明显优势;基数太低,则空间效率和性能会大大降低。
对于特定类型的查询例如count、or、and等逻辑操作因为只需要进行位运算。如:通过类似 select count(*) from table where city = ‘beijing’ and job = ‘teacher’ 这种多个条件组合查询场景,如果在每个查询条件列上都建立了bitmap索引,则可以进行高效的位运算,精确定位到需要的数据,数据扫描量。当筛选出的结果集越小,bitmap索引的优势越明显。















 535
535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









