






程序相关说明
程序使用说明
1、 为了显示出(使用selenum)程序的运行过程,没有将操作浏览器的过程隐藏掉
2、 程序开始会受到selenum的控制,所以会弹出浏览器,将其关闭即可
3、 第一次运行程序时,请将jingdong.py的main()方法中的两个删除表的方法注释掉程,关闭之前运行的程序,(取消注释删除表)重新运行,因为删除数据id作为自增长不能回到初始状态。
4、 程序如果卡顿,可能是正在启动浏览器(启动浏览器耗时),
5、 程序如果卡顿,可能是正在启动浏览器(启动浏览器耗时)
6、 程序如果卡顿,可能是正在启动浏览器(启动浏览器耗时)
7、 因为涉及到图形化界面,看了图形化界面的内容后,请关闭界面程序才能继续运行
重要的事情说三遍
请关闭前一次正在运行的jingdong程序,再重复运行,否则会出现异常
请关闭前一次正在运行的jingdong程序,再重复运行,否则会出现异常
请关闭前一次正在运行的jingdong程序,再重复运行,否则会出现异常
数据库
只需要创建数据库名字未jingdong的即可,第一次运行键使用说明第三点,程序中有表的创建
关于文件路径问题(图片下载到了F:\python\img)
删除这个文件夹
path='F:\\python\\img'
Deletefolder.deleteFile()#删除文件夹
Jingdong中的mian()函数中,如果想要更改路径也是可以的
source="F:\\python\\img\\"+inputNumber.strip()
ImgView.main(source)#这里传入的是图片的路径
知识分享
爬虫中所用的库
Pymysql-----------用于操作mysql数据库,当然还有其他的方法
Requests----------用于爬取指定网页的信息
Time--------------(只要涉及到日期时间都会用到)
selenium(from selenium import webdriver) ----------用于控制浏览器
我这里控制的是chrome浏览器
bs4 (from bs4 import BeautifulSoup)-----------配合request做一些简单的爬虫
urllib------------是 Python 内置的 HTTP 请求库,我这里主要是图片下载的时候用到了
tkinter-----------用于python的图形化界面
os---------------- os模块提供了多数操作系统的功能接口函数,这里在读取文件夹的时候用到了
import shutil-------这里用来彻底删除文件夹中的内容
Matplotlib --------Matplotlib 能够创建多数类型的图表,如条形图,散点图,条形图,饼图,堆叠图,3D 图和地图图表
爬虫流程:
图片: 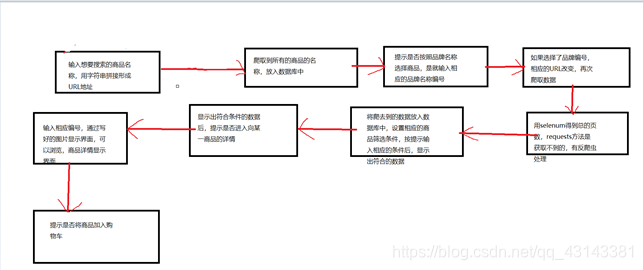
编码中所有的类
Jingdong.py-------------------------------爬虫的主要类
Message-----------------------------------将相应的list数据界面画显示在滚动面板中
DetailMessageView.py--------------将详细信息界面显示在滚动面板中
ImgView.py--------------------------用于显示指定文件夹下面的所有图片,实现界面化显示
DownLoadImg.py-------------------用于将图片下载到指定路径
tubiao.py------------------------------用于生成直方图
其中所有的类,以main()函数作为程序的入口
基础技术
1、Requests和BeautifulSoup的使用
2、使用pymysql操作数据库(数据库的增删查改,表的创建与销毁)
3、图片的下载以及打开,以及图片的尺寸处理
特色技术
1、Selenium的操作,用于操作浏览器的方式,获取页面数据,以及一些自动化操作
webdriver.Chrome()需要安装,搜一下相关的博客就可以找到
这个链接是webdriver.Chrome()的版本对应以及下载
https://blog.csdn.net/huilan_same/article/details/51896672
常用的操作使用方法总结可以参考这篇文档
https://www.cnblogs.com/Undo-self-blog/p/8432406.html?tdsourcetag=s_pcqq_aiomsg
2、tkinter 的一些常用操作可以参考菜鸟教程和一些博客
3、使用设置时间撮的方式实现获取动态加载的数据(直接使用request请求只能获取前面30条的数据)
`
for i in range(1,2):
print("这是第"+str(i)+"页"+"@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@")
a = time.time()
b = '%.5f' % a
url=url+"&page="+str(i*2-1)+"&s=58&click=0"
soupfirst=getSoup(url)
findAllGoods(soupfirst)
url2=url+"&page=" + str(
i * 2 ) + "&s=58&click=0"+ '&s=' + str(48 * i - 20) + '&scrolling=y&log_id=' + str(b)
souplast=getSoup(url2)
findAllGoods(souplast)
4、Matplotlib 库中图表的使用
直方图。 直方图非常像条形图,倾向于通过将区段组合在一起来显示分布
代码以及过程讲解
## 1、 创建表
```javascript
def CreatTable(cur):#建立品牌表
cur.execute("CREATE TABLE IF NOT EXISTS Brand(Id INT PRIMARY KEY AUTO_INCREMENT,BrandName VARCHAR(50))")
def CreatCommodityTable(cur):#创建商品表
cur.execute("CREATE TABLE IF NOT EXISTS Commodity(CId INT PRIMARY KEY AUTO_INCREMENT,CommodityName VARCHAR(300),Price VARCHAR(20),StoreName VARCHAR(40),Comment VARCHAR(20),goodicon VARCHAR(100),DetaileUrl VARCHAR(100))")
1、 创建表
path='F:\\python\\img'
Deletefolder.deleteFile()#删除文件夹
2、 通过字符串拼接方法得到url地址,得到BeautifulSoup对象
inputCommodity = input("请输入你想要查询的商品")
url = "https://search.jd.com/Search?keyword=" + inputCommodity + "&enc=utf-8&wq=" + inputCommodity
def getSoup(url):#得到soup对象
try:
r=requests.get(url)
r.encoding="UTF-8"
r.raise_for_status()#编码如果不是200就会引发异常
soup=BeautifulSoup(r.text,"html.parser")
return soup
except:
return ''
3、是否想要按照品牌结果进行赛选,再原有URL后面继续拼接&ev=exbrand_+品牌名称的即可实现
if flag == False:
YesOrNo=input("您是否想要选择您想要的品牌,如果想要选择请输入yes,不想要选择请输入no>>>>>>")
if YesOrNo=="yes":
brandlist = seletBrand()
BrandMessage=[]
for singleBrand in brandlist:
print("编号>>>>>"+str(singleBrand[0]), end='')
print("品牌>>>>>>"+singleBrand[1])
BrandMessage.append("编号>>>>>"+str(singleBrand[0])+" "+"品牌>>>>>>"+singleBrand[1])
Message.main(BrandMessage)
idNumber=input("请输入你想要选择的品牌编号>>>>")
print(brandlist[eval(idNumber)-brandlist[0][0]][1])
url=url+"&ev=exbrand_"+brandlist[eval(idNumber)-brandlist[0][0]][1]
print(url)
soup=getSoup(url)

4、输入相应的编号后,系统操作得到总的页数并设置相应的,因为使用selenum操作浏览器得到总的页数,所以会有启动浏览器的过程,请耐心等待
def getPages(url):
browser = webdriver.Chrome()
try:
browser.get(url)
pages = browser.find_element_by_xpath("//*[@id='J_bottomPage']/span[2]/em[1]/b").text
finally:
browser.close()
return pages
5、加载所有页面的数据,因为一般情况下,页面数量比较多,所以代码中for循环只循环了一次,爬取所有的数据只需要,将循环中的2改为pages即可
for i in range(1,2):
print("这是第"+str(i)+"页"+"@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@")
a = time.time()
b = '%.5f' % a
url=url+"&page="+str(i*2-1)+"&s=58&click=0"
soupfirst=getSoup(url)
findAllGoods(soupfirst)
url2=url+"&page=" + str(
i * 2 ) + "&s=58&click=0"+ '&s=' + str(48 * i - 20) + '&scrolling=y&log_id=' + str(b)
souplast=getSoup(url2)
findAllGoods(souplast)
goodslist=selectGoods()
6、设置相应的赛选条件
isprice=input("是否按照价格筛选,是请输入yes,不是请输入no")
maxprice=10000000
minprice=0
if isprice=="yes":
maxprice=eval(input("请输入最高价格:"))
minprice = eval(input("请输入最低价格:"))
isstorename=input("是否按照店铺筛选,是请输入yes,不是请输入no")
storeName=""
if isstorename=="yes":
storeName = input("请输入你想要的店铺名称")
feature=""
isfeature=input("是否按照以下特点进行赛选,是请输入yes,不是请输入no")
if isfeature=="yes":
feature=input("为了避免赛选结果有误请输入以下赛选条件:自营,京东配送,新品,险,免邮")
ViewMessage=[]
for singleBrand in goodslist:
price=eval(singleBrand[2][1:])
if price>maxprice or price<minprice:
continue
if storeName!="":
if storeName!=singleBrand[3].strip():
continue
if feature!="":
if feature not in singleBrand[5]:
continue
print("编号>>>>>"+str(singleBrand[0]))
print(singleBrand[1])
print(singleBrand[2])
print(singleBrand[3])
print(singleBrand[4])
print(singleBrand[5])
print("-------------------------------------------------------------------")
string="编号>>>>>"+str(singleBrand[0])+"\n"+singleBrand[1]+"\n"+singleBrand[2]+"\n"\
+singleBrand[3]+"\n"+singleBrand[4]+"\n"+singleBrand[5]+"\n"\
+"------------------------------------------------------------"
ViewMessage.append(string)
Message.main(ViewMessage)

7、设置循环查看详情
图中标注出分别表示
下载图片
图片界面化展示
商品详情界面化展示
添加进购物车

1、 创建表
path='F:\\python\\img'
Deletefolder.deleteFile()#删除文件夹
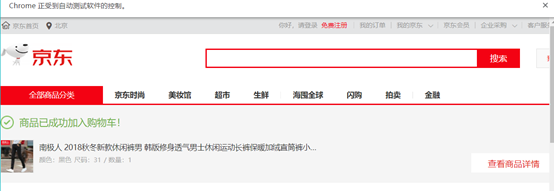
依次的效果如下图所示
(图片因为被强行设置尺寸,所以比较模糊,尺寸适应的代码,以后再加)



















 3912
3912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









