









01 LR(Linear regression)
Definition:
The case of only one independent variable is called univariate regression, and the case of more than one independent variable is called multiple regression。In the above formula, x is the independent variable (characteristic component) and y is the dependent variable, θ Represents the weight of the feature component。
The product of the transpose of a column vector and the feature yields our predicted results. However, it is obvious that the results obtained by our model may have errors, as shown in the figure below.

1.1 Loss function
There is a certain error between the real results and our predicted results. We measure the error by loss function. Usually we choose a non negative number as the error, and the smaller the value is, the smaller the error is. A common choice is the square function. here, we use hθ(x) to measure the quality of the real value y.
1.2 Algorithms
To make J( θ) In order to minimize the error, the following two methods can be used: one is to make the normal equation solution (only applicable to simple linear regression), the other is to use the gradient descent algorithm.
-
Normal equation
X is the eigenvalue matrix and Y is the objective matrix
Disadvantages: when the feature is too complex, the solution speed is too slow
For complex algorithm, normal equation can not be used to solve (logistic regression, etc.) -
Gradient descent algorithm
Assumed linear function form is:
the loss function is given by:
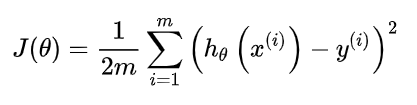
Gradient descent is an algorithm used to find the minimum value of the function. Gradient descent algorithm will be used to find the minimum value of the loss function.
Gradient descent idea: at the beginning, we randomly select a combination of parameters to calculate the loss function, and then we find the next parameter combination that can reduce the value of the loss function the most. We continue to do this until we find a local minimum. Because we haven’t tried all the parameter combinations, we can’t determine whether the local minimum we get is the global minimum. If we choose different initial parameter combinations, we may find different local minimum.
Understanding of gradient descent: imagine that you are standing on the point of the mountain, on the red mountain of the park you imagine. In the gradient descent algorithm, all we have to do is rotate 360 degrees, look around us, and ask yourself to go down the mountain as quickly as possible with small steps in a certain direction. What direction do these little steps need to go? If we stand on the hillside, if you look around, you will find the best downhill direction. You look around again, and then think again, from what direction should I take small steps downhill? Then you take another step according to your own judgment and repeat the above steps. From this new point, you look around and decide which direction is the fastest way to go down the mountain. Then you take another small step and so on until you are close to the local lowest point.

02 MLP(Muti-Layer Perception)
An important feature of multilayer perception is multilayer. We call the first layer input layer, the last layer output layer, and the middle layer hidden layer. MLP does not specify the number of hidden layers, so we can choose the appropriate number of hidden layers according to their needs. There is no limit on the number of neurons in the output layer.

Therefore, neural network has three basic elements: weight, bias and activation function
Weight: the connection strength between neurons is represented by weight, and the weight represents the possibility
Bias: the bias setting is for the correct classification of samples. It is an important parameter in the model, that is, to ensure that the output value calculated through the input can not be activated casually.
Activation function: it plays the role of nonlinear mapping. It can limit the output amplitude of neurons to a certain range, generally between (- 1-1) or (0-1). The most commonly used activation function is sigmoid function, which can map the number of (- ∞, + ∞) to the range of (0-1).

2.1 activation function
The reason of introducing activation function in multi-layer perception is that the expression ability of multiple linear layers without activation function is the same as that of a single linear layer.
One way to solve the problem is to introduce nonlinear transformation, which is called activation function.
Several commonly used activation functions:
- Relu(rectified linear unit)
The relu (rectified linear unit) function provides a very simple nonlinear transformation.
The relu function retains only positive elements and clears negative elements.


2.Sigmoid

It can be seen from the above that the relationship between the value of a single neuron in the lower layer and all inputs in the upper layer can be expressed in the following way, and so on.

03 DT(Decision Tree)
Decision tree is a kind of decision from root node to leaf node.
It can be used for classification and regression.
Leaf node is the final decision result.
The decision tree consists of nodes and directed edges. There are two types of nodes: inner node and leaf node. The inner node represents a feature or attribute, and the leaf node represents a class. Generally, a decision tree contains a root node, several internal nodes and several leaf nodes. The leaf node corresponds to the decision result, and each other node corresponds to an attribute test. The sample set contained in each node is divided into sub nodes according to the result of attribute test. The root node contains the complete sample set, and the path from the root node to each leaf node corresponds to a decision test sequence. In the figure below, circles and boxes represent inner nodes and leaf nodes, respectively. The purpose of decision tree learning is to produce a decision tree with strong generalization ability, that is, the ability to deal with no examples.

3.1 Hypothetical space
The basic principle of decision tree algorithm is described from three aspects: hypothesis space, objective function and optimization algorithm.
The assumption space is our prior assumption of the model form, and the model we get must conform to our prior assumption of the model form.
The prior form of decision tree model can be expressed as follows:

Where q [x] is a function mapped from the feature space to the node number space. The key of decision tree model is to divide the feature space into disjoint sub regions, and the samples in the same sub region have the same prediction value.
In order to determine the complete structure of a decision tree, it is necessary to define the following two aspects: one is how to divide the molecular region, and the other is how much the prediction value of the sub region is.
3.2 objective function
Objective function is the standard we use to evaluate a model. The objective function determines our preference to choose models from the hypothesis space.
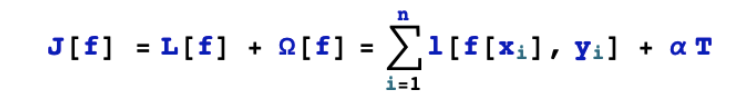
The objective function of decision tree can be used to evaluate a decision tree. This objective function should include two aspects. The first is the loss term of the fitting accuracy of the sample data points by the response decision tree, and the second is the regularization term of the complexity of the response decision tree model.
The regularization term can take the number of leaf nodes of the model. That is to say, the more disjoint sub regions the decision tree model can get, the more complex the model is.
For the loss item, if it is a regression problem, the loss item can be squared. If it is a classification problem, we can use the impure as the measurement standard.
Why not use it? Because all samples on the same leaf node of the decision tree take the same prediction value, if the real label of these samples has only one value, then the samples on this leaf node are very “pure”. We can directly specify the prediction value as the value of the label on this leaf node, and the prediction error is 0. On the contrary, if the label values of different samples on the leaf node are very messy, the so-called consensus is difficult to adjust, then no matter how we specify the prediction value on the leaf node, there will always be a large prediction error.
So, how to measure the impurity? There are generally three methods, information entropy, Gini impure, and classification error rate. The classification error rate is the error rate when the category with the most label values is used as the leaf node prediction value. Information entropy and Gini impure will be introduced later.
3.3 Supplementary knowledge
Training and testing
In the training stage, a tree is constructed according to the given data set, and the most valuable feature segmentation node is selected from the root node; The test phase is based on the decision tree model.

The measure standard of Feature Segmentation – entropy
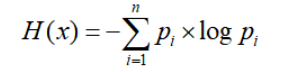
Entropy is used to represent the uncertainty of random variables.
References:
https://www.jianshu.com/p/a31091d5acbb
https://www.jianshu.com/p/f25a4cc98e6f
https://blog.csdn.net/weixin_43910854/article/details/105841484
https://www.sohu.com/a/333961303_100099320
https://www.chinait.com/ai/30661.html















 2144
2144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









