







一、简介
这篇文章主要是使用python中的requests和BeautifulSoup库来爬取上万篇的新闻文章。我这里以科技类新闻为例来爬取2000篇新闻文章http://news.chinairn.com/News/moref9fff1.html
二、爬取网页源代码
在python中爬取网页源代码的库主要有urllib、requests,其中requests使用得比较多,另外说明下urllib这个库,在python2中存在urllib2、urllib两个库来爬取网页源代码,但是在python3中将这两个库合并了,就只有urllib这一个库了,但是使用的人相对没有那么多。
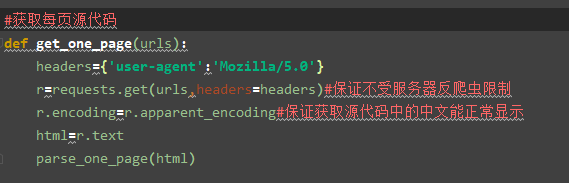
上图源代码就是使用requests中得get函数来获取,其中变量html就是源代码了。
三、解析网页源代码
这一步主要就是利用BeautifulSoup库来解析,在python中还有re、lxml、PyQuery等库,下一步会使用PyQuery库来解析。在获取到网页得源代码之后,最重要的就是如何在网页代码中提取我们所需要的信息(新闻标题和新闻链接),先上代码:

这个代码里面最重要的的一行代码就是news=soup.select(’.list ul li dl da a’),可以打开简介中的链接:http://news.chinairn.com/News/moref9fff1.html按下F12键进入审查元素,找到我们需要获取的新闻标题和新闻链接。然后根据网页源代码中的class(.)、id(#)、标签(空)等来定位新闻标题和新闻链接。这一步我觉得是最重要的,你们要是爬取其他网址,select里面是不一样的,看到class就使用(.),看到id就使用(#)、标签就不需要加什么。最后再使用一个for循环将第一页中的20篇文章的标题和链接保存到变量news_link、news_title。
四、获取每篇新闻内容
根据上一步得到的新闻链接来获取这个链接里的新闻内容。

这里面可以看到doc=pq(texts)中的pq就是使用了PyQuery库来解析,这个库在使用时其实更加好用,我就在这里试了以下。new_content=doc(’.nylt .article p’).text()这一步就类似于上一步中soup.select()。然后每页中的20篇文章保存下来。
五、循环多页
根据上面几步已经成功的将20篇文章下载了,接下来就是循环下载100页了。
最后再根据这一步循环多页了。
六、全部代码
最后就是上全部源代码了。
import requests
from bs4 import BeautifulSoup
import time
from pyquery import PyQuery as pq
#获取全部页的网址
def All_url(url):
page=1
while page<=100:
urls = r"http://news.chinairn.com/News/moref9fff"+str(page)+".html"
print(“正在爬取第%d页。”%(page))
print(urls)
page=page+1
get_one_page(urls)
#获取每页源代码
def get_one_page(urls):
headers={‘user-agent’:‘Mozilla/5.0’}
r=requests.get(urls,headers=headers)#保证不受服务器反爬虫限制
r.encoding=r.apparent_encoding#保证获取源代码中的中文能正常显示
html=r.text
parse_one_page(html)
#解析每页网页源代码,并获取新闻链接与新闻标题
def parse_one_page(html):
count=0
soup=BeautifulSoup(html,‘html.parser’)
news=soup.select(’.list ul li dl dt a’)
for new in news:
link = new[‘href’]#获取html中所需要部分的新闻链接
news_link=‘http://news.chinairn.com’+link
news_title = new.string#获取html中所需要部分的新闻名字
print(news_link)
print(news_title)
count = count + 1 #统计每页爬取的的数量
print(‘正在爬取第%d篇’%(count))
parser_more_page(news_link,news_title)
#获取所有页数的新闻内容
def parser_more_page(news_link,news_title):
res=requests.get(news_link)
res.encoding=res.apparent_encoding
texts=res.text
doc=pq(texts)
new_content=doc(’.nylt .article p’).text()
file_path=‘D:/technology.txt’
file=open(file_path,“a”,encoding=‘utf-8-sig’)
#加上encoding参数,保证存储在txt与csv文件中中文字符不乱码
file.write(new_content + ‘\n’ + ‘\n’)
file.close()
print(“成功一个文件”)
def main():
url=‘http://news.chinairn.com/News/moref9fff1.html’
All_url(url)
if name == ‘main’:
s=time.time()
main()
e=time.time()
print(“完成!!时间为:{}”.format(e-s))
以上就结束了所有的介绍啦,我也只是看书看视频看博客学的,里面确实还存在很多的不足之处有大神看到的话,可以帮忙指出来。万分感谢!!!也希望能为正在学习爬虫的你,提供一点点思路或者看法。谢谢啦!















 2281
2281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









