







论文1
原论文来自
A Deep Learning Ensemble Approach for
Diabetic Retinopathy Detection
S. Qummar et al., “A Deep Learning Ensemble Approach for Diabetic Retinopathy Detection,” in IEEE Access, vol. 7, pp. 150530-150539, 2019, doi: 10.1109/ACCESS.2019.2947484.
文章发表在 IEEE access.
摘要
摘要主要介绍了使用眼底图片(retina image) DR 检测的重要性,同时,当前的自动检测方法的检测精度很低,尤其是对于早期阶段的检测。论文使用 Kaggle 上的数据集,训练五个卷积神经网络(Resnet50, InceptionV3, XException, Dense121, Dense169)的组合模型,实验表明这种模型的预测方法比当前的方法要好。
相关工作
介绍了一些前人 DR 检测的工作,主要是有两类,一类是二分类问题,判断是不是患病,一类是多分类问题,判断患病的阶段。但是很多的工作都判断不准,尤其是早期的阶段,而 DR 预测在早期又非常的重要。
论文提出了使用 Kaggle 数据集来预测 DR 的 mild stage,并且表现比较好。另外,文章还提到了数据的不均衡对预测结果的影响。
方法
总共是 35126 张图片,而且类别很不均衡,大多是 0 类(未患病)。论文进行了上采样和下采样来进行训练。


首先将图片裁剪为 786 x 512 的尺寸,并且针对上采样的情况,还进行了图片增强,包括 crop, flip, rotate. 然后训练每个模型上的输出。
组合模型

将每个模型的结果输出,然后取平均值。
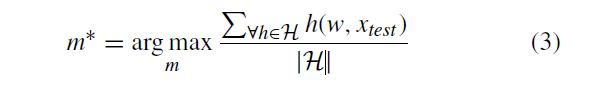

结果和讨论
这里主要介绍了一些性能评价指标,以及一些讨论。
准确率:分类正确的样本占总体样本的数量。这个其实并不太能够反映真实情况,因为总共三万多的样本,其中正常的就有两万多,非常不均衡。
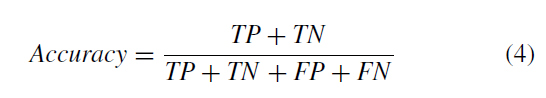
召回率:所有患病的样本中,预测正确的占多少。
这个应该是非常重要的指标,应该尽可能的高,因为这种情况对应着漏诊。
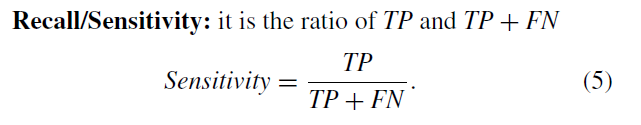
Specificity: 所有不患病的样本中,预测正确的占了多少。
这个对应着误诊的情况,可以效果差一些。
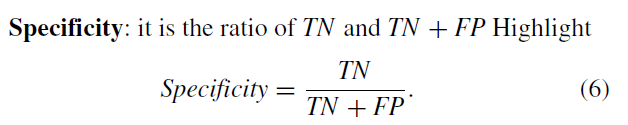
Precision:所有预测患病的样本中,预测正确的占多少。
这个就对应着我预测的精准度,而且比 accuracy 更能说明情况,因为患病的样本才是我们真正关注的。
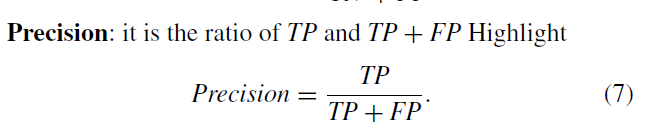
F1 得分:这个就是按照公式理解即可,当然得分越高越好。

ROC 和 AUC 曲线:具体介绍可以查看ROC,AUC 可以理解为 ROC 的面积。

可以看到在不均衡的数据集上,结果如下:


在上采样的数据集上,结果如下:


在下采样的结果如下所示:

分析
上采样之后,确实会有一些性能的改善,但是 Recall 这个参数,还远远达不到精度,这个是基本上两个人中,就会有一个漏诊,这是非常不能够忍受的。
或者说,这种卷积的模型根本没有学到这些细微的特征。















 4704
4704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









