






相关性分析
定义
相关分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个因素的的相关密切程度,相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。(来自知乎)
可能读了上述定义仍不清楚什么是相关性,我的个人理解:比如说逛淘宝购买商品的数量与性别的关系考研进行相关性分析.
类别
Pearson(皮尔逊)相关系数(用的较多)
Spearman Rank(斯皮尔曼等级)相关系数
Kendall Rank(肯德尔等级)相关系数
使用场景
Pearson(皮尔逊)相关系数
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
Spearman Rank(斯皮尔曼等级)
斯皮尔曼等级相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,
或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,
都可以用斯皮尔曼等级相关系数来进行研究。
Kendall Rank(肯德尔等级)相关系数
肯德尔相关系数与斯皮尔曼相关系数对数据条件的要求相同。
计算公式
paerson相关系数

以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
我们有了样本数据,用公式三我个人认为较为方便.
Spearman Rank(斯皮尔曼等级)
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,
两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。对X、Y进行排序(同时为升序或降序),
得到两个元素排行集合x、y,其中元素xi、yi分别为Xi在X中的排行以及Yi在Y中的排行。
将集合x、y中的元素对应相减得到一个排行差分集合d,其中di=xi-yi,1<=i<=N。
随机变量X、Y之间的斯皮尔曼等级相关系数可以由x、y或者d计算得到,其计算方式如下所示:
注意:当变量的两个值相同时,它们的排行是通过对它们位置进行平均而得到的。

Kendall Rank(肯德尔等级)相关系数
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,
两个随即变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。X与Y中的对应元素组成一个元素对集合XY,
其包含的元素为(Xi, Yi)(1<=i<=N)。
当集合XY中任意两个元素(Xi, Yi)与(Xj, Yj)的排行相同时(也就是说当出现情况1或2时;
情况1:Xi>Xj且Yi>Yj,情况2:Xi<Xj且Yi<Yj),这两个元素就被认为是一致的。
当出现情况3或4时(情况3:Xi>Xj且Yi<Yj,情况4:Xi<Xj且Yi>Yj),这两个元素被认为是不一致的。
当出现情况5或6时(情况5:Xi=Xj,情况6:Yi=Yj),这两个元素既不是一致的也不是不一致的。
举个栗子:

注意:性别已经先做处理转换成0 or 1了
针对上述表格一致性C:
比如病人1的性别0<病人2的性别1,且身高130<病人2的身高145,则病人1、2是一致性的1对,解释起来即病人1、2的性别和身高的排序或称之为序列是一致的。
同理,病人1与病人10、6、9、7都能结成一致性的对,这时一致性对数已经等于5.
那么同理,病人5与病人2、10、6、9、7,病人8与病人6、9、7,病人3与病人7,病人4与病人7都是一致的。
这么加起来C=15.
不一致性D:
比如病人2的性别1>病人8的性别0,而身高145<病人8的156,则病人2、8是不一致的一对。
就不继续往下同理了,反正加起来D=10.
即不是一致,也不是不一致:
比如病人1的性别0=病人5的性别0,比如病人2的性别1=病人10的性别1,比如病人6、9性别身高都相等,那么他们既不是一致的,也不是不一致的。
当两个样本数据不存在并列排位时:

存在并列排位时:

其中c和d则分别代表一致对和分歧对的个数,tx和ty则分别表示数据X中的并列排位个数,和数据Y中的并列排位个数。注意,如果是同时发生在X和Y中并列排位,则既不计入tx,也不计入ty。
从上述计算中得到了相关系数,之后进行假设断定,即判断这个假设能否成立,通过相关系数求t值,之后根据t界值表查询p值,如果p<0.05表名这个假设有意义;
那么如何根据相关系数求t呢?
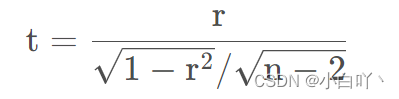
详情请参考
https://blog.csdn.net/zfqy2222/article/details/124495937?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124495937-blog-71267144.pc_relevant_landingrelevant&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-124495937-blog-71267144.pc_relevant_landingrelevant&utm_relevant_index=1
上述式子中n-2为自由度
那么自由度又是什么呢?
自由度(degree of freedom, df)指的是计算某一统计量时,取值不受限制的变量个数。
通常df=n-k。其中n为样本数量,k为被限制的条件数或变量个数,或计算某一统计量时用到其它独立统计量的个数。
自由度通常用于抽样分布中。(来自百度百科)
那为什么根据相关系数求t值被限制条件数或者变量个数要是2呢?
(我不是很理解,详情请参考上面那篇博文)
自由度详解请见这篇文章:https://zhuanlan.zhihu.com/p/81099139
以上即为我这几天对于相关性的理解,如有不对请大家更正















 230
230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









