







BIO
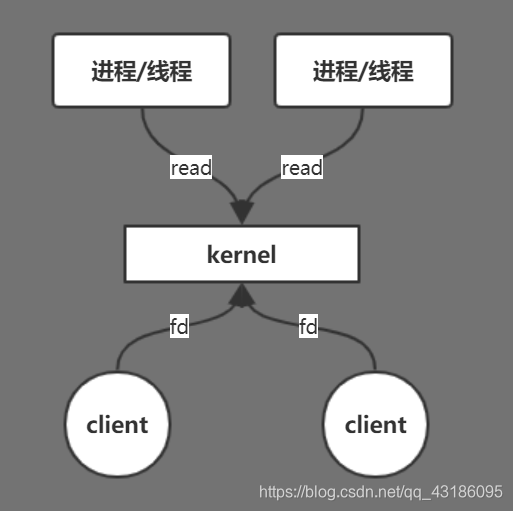
在BIO模型里,当客户端将文件描述符通过内核发送给进程/线程时,如果进程/线程还没读到这个文件描述符,那么他会在那一直阻塞着,下面代码执行不了,如果这时候又有一个客户端发送一个请求的话,那么只能抛出一个新的进程/线程来处理新的客户端请求。另外,假如此时只有一个CPU,它在一个时间片内只能处理一个线程,那么新来的线程只能等待CPU给他分配时间片,无法处理客户端请求,造成了资源的浪费,并且线程多了之后,线程上下文切换开销也是比较大的。现在这种模型并不适合去使用,因此对他进行了改进,让他变为非阻塞的。
NIO
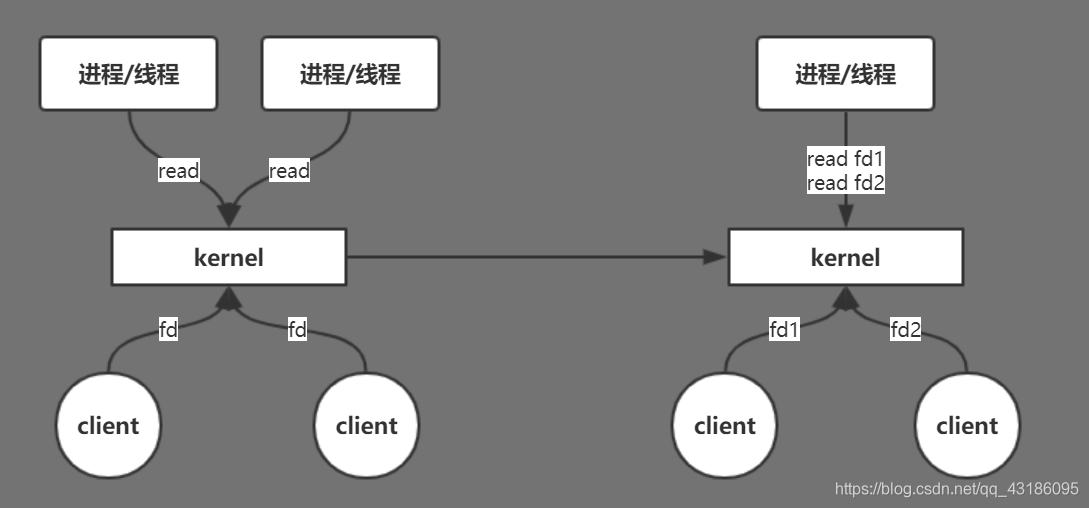
既然线程多了,会有弊端,那么在一个CPU的情况下就只用一个线程写个死循环轮询(发生在用户空间)去处理这些请求,先读fd1如果为空,就去读fd2,如果不为空就处理,处理完了继续读fd1,如此循环。在这个模型中显然是同步非阻塞的,即NIO
但是上述模型依旧存在弊端,假如此时有10000个fd,那么线程需要轮询调用10000次内核,用户态到内核态的切换十分的频繁,显然这个成本是非常大的。那么如何改进?
我们在linux下执行man 2 select 看select指令的描述

select()和pselect()允许程序监视多个文件描述符,直到一个或多个文件描述符“准备好”进行某些类型的I/O操作。如果可以在不阻塞的情况下执行相应的I/O操作,则认为文件描述符已经准备好了。
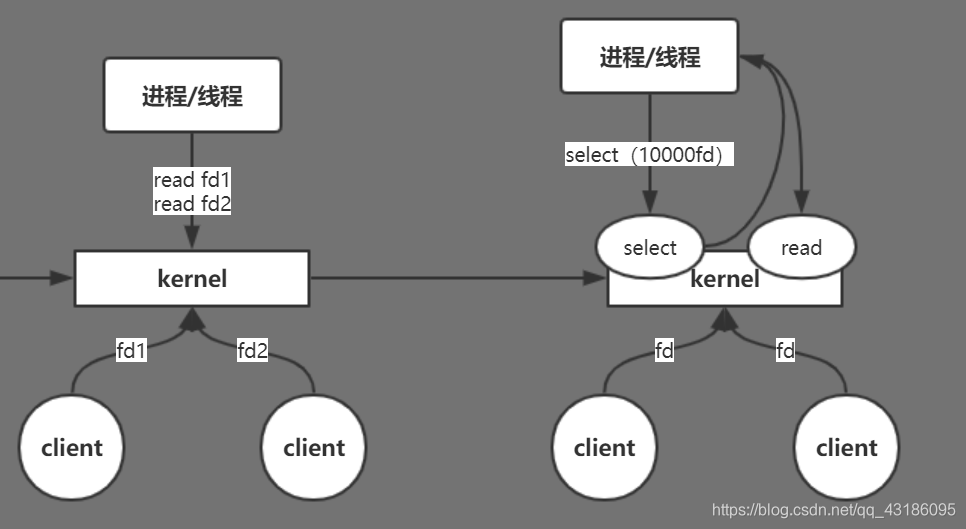
因此改进的新模型就是用select指令,在内核收集有内容的fd再返回给线程,然后线程对这些有内容的fd进行read。这就是多路复用(epoll)
不过上述模型依旧存在弊端。一是每次select的fd的集合大小有限制,最高为1000;二是性能上的弊端,从select到read这一过程过于复杂,处理速度慢
针对弊端一,解决方案为使用poll,poll和sellect没有太大区别,主要的区别就是poll没有fd集合大小的限制
针对弊端二,解决方案为,共享空间
首先我们来明确一下处理速度慢的原因:上述模型说到线程对有内容的fd进行read,那么有内容是如何断定的?显然用户线程需要和内核通信,确定fd中是否有内容,因此在这个环节,fd成为累赘,造成了我们处理速度慢,因此接下来我们要对文件描述符进行改进。
解决这个问题的关键就在于共享空间
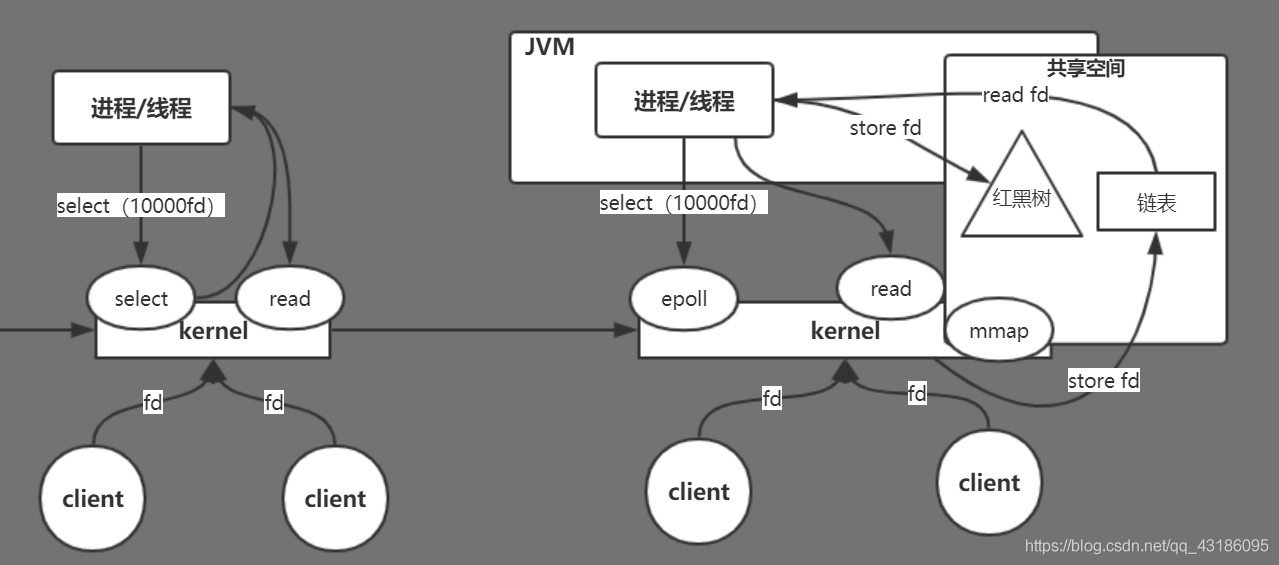
这个共享空间通过mmap系统调用来实现,在共享空间中存储着两种数据结构,分别是红黑树和链表。红黑树用来存储线程拥有的文件描述符,内核通过红黑树中的文件描述符和client请求和文件描述符进行比照,如果两者匹配,那么就把client发过来的fd存放到链表里,线程就可以读取链表中的文件描述符调用read操作了。
select、poll、epoll之间的区别
https://www.cnblogs.com/aspirant/p/9166944.html
https://www.cnblogs.com/gaorong/p/7496993.html















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









