







目录
mysql 存储过程
mysql 触发器
mysql 索引
索引的分类与创建
mysql中索引分为几种:
- 主键索引
常用
主键自带索引效果,性能是非常好
- 普通索引
为普通列创建的索引
创建索引的命令:
# 格式
create index 索引名称 on 表名(列名)
# 例子
create index idx_name on employees(name)
- 唯一索引
就像是唯一列,列中的数据是唯一的。比普通索引的性能要好
创建唯一索引的命令:
# 格式
create unique index 索引名称 on 表名(列名)
# 例子
create unique index idx_unique_name on employees(name)
- 联合索引(组合索引)
常用
- 一次性为表中的多个字段一起创建索引。遵循最左前缀法则(如何命中联合索引中的索引列)
- 一个联合索引建议不要超过5个列
创建联合索引的命令:
# 格式
create index 索引名称 on 表(列1,列2,列3)
# 例子
create index idx_name_age_position on employees(name,age,position)
- 全文索引
进行查询的时候,数据源可能来自于不同的字段或者不同的表。比如去百度中查询数据-苍老师,数据可能来自于网页的标题或者网页的内容 。MyISAM存储引擎支持全文索引,在实际生产环境中,并不会使用MySQL提供的MyISAM存储引擎的全文索引功能来是实现全文查找,而是会使用第三方的搜索引擎中间件比如ElasticSearch(多)、Solr
索引使用的数据结构
使用索引查找数据性能很快,但是我们发现使用索引时也需要在索引文件中查找数据,并且索引文件和源数据文件大小基本一致,那索引凭什么就能那么快呢?
这就跟索引使用哪种数据结构有关了。mysql中索引使用的数据结构主要有2种,B+树和哈希表。在绝大多数需求为单条记录查询的时候,可以选择哈希表,查询性能最快,其余大部分场景建议选择B+树,为什么?
因为哈希表虽然可以快速查询单条记录,但是对范围查找很不友好(区间访问),例如根据下图查询出大于23的数据,需要做很多次的hash运算,才能把数据全部查询完毕

那为什么使用B+树查询的速度就快呢?这里先来了解一下B+树的特点:
- 一个结点可以存放多个数据
- 非叶子结点冗余了叶子结点中的数据
- 叶子结点是从小到大、从左到右排列的
- 只有叶子结点存放数据,非叶子结点是不存放数据的
- 叶子结点之间提供了指针,提高了区间访问的性能(当需要对所有数据进行遍历的时候,B+树只需要花费O(logN)(树的深度)时间找到最小的一个节点,然后通过指针,再花费O(N)时间顺序遍历即可找到全部数据)
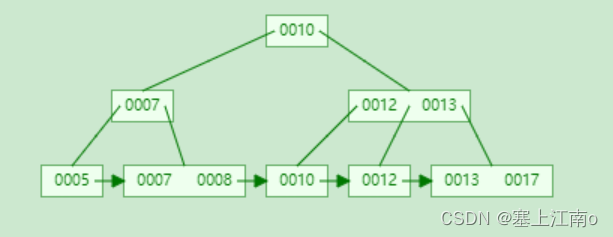
在mysql中,mysql 中的索引是一个键值对,键:索引列(大小为8b),值:简单来说一行数据(大小为1kb)
假设有一张用户表,为其中的id列创建了索引
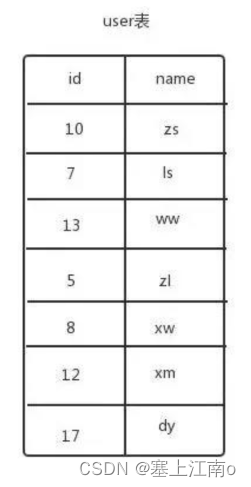
那索引中会存放 键+值,这些键+值,在b+树中的存放形式为:

上图为什么能存放那么多键呢?

总结:
- 一个结点可以存放多个键
- 非叶子结点冗余了叶子结点中的键
- 叶子结点是从小到大、从左到右排列的
- 只有叶子结点存放数据(键+值),非叶子结点是不存放数据的,只存放键
- 叶子结点之间提供了指针,提高了区间访问的性能
由于B+树的内部节点只存放键,不存放值,因此,一次读取,可以在内存页中获取更多的键,有利于更快地缩小查找范围,并且当需要对所有数据进行遍历的时候,B+树只需要花费O(logN)(树的深度)时间找到最小的一个节点,然后通过指针,再花费O(N)时间顺序遍历即可找到全部数据
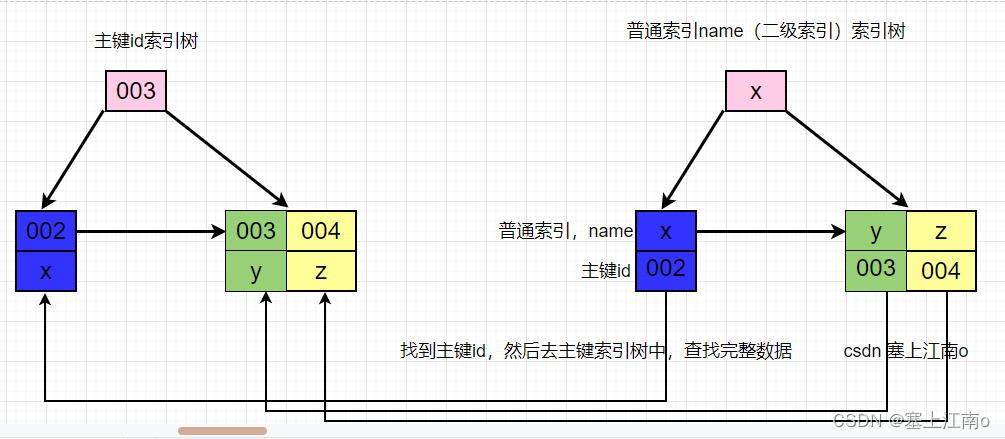
二级索引
除了主键索引(聚簇索引)外,其他的索引都是二级索引
二级索引采用的数据结构一般也为B+树,B+树的叶子结点存放的是键+值,不过值不是具体的数据行了,而是主键的值
mysql 存储引擎InnoDB&MyISAM
mysql表的存储引擎主要有2种,InnoDB(常用)和MyISAM
2者区别
| InnoDB存储引擎 | MyISAM存储引擎 | |
|---|---|---|
| 索引和数据 | 我们通常把InnoDB存储引擎使用的索引叫做聚集索引,原因是因为它把数据和索引存放在了一个文件中,找到索引后直接就能获得完整的数据 | 我们通常把MyISAM存储引擎使用的索引叫做非聚集索引,原因是因为它把数据和索引分别存放在了二个文件中,导致查找到索引后还要去另一个文件中找数据,性能会慢 |
| 全文索引 | 不支持(但可以用插件来实现相应的功能) | 支持 |
| 锁 | 支持表锁、行锁 | 天然支持表锁、不支持行锁 |
| 主键 | 设不设置都有,不设置的话会有虚拟主键 | 没有,但是索引就是行的地址 |
| 事务 | 支持事务 | 不支持 |
| 使用场景 | 绝大多数场景 | 系统查询的情况占绝大多数(例如报表系统)就可以使用MyISAM来存储 |
| 底层文件格式 | 使用InnoDB存储引擎的表,文件后缀名xx.ibd | 使用MyISAM存储引擎的表,2个文件后缀名分别为–索引:xx.MYI; 数据:xx.MYD |
InnoDB引擎的底层原理
mysql 最左前缀
最左前缀用来干什么的?
它让我们知道,我们写的sql语句有没有在联合索引中走索引
怎么用?
mysql 建立联合索引时会遵守最左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配
- 创建联合索引
create index idx_a_b_c on table1(a,b,c);
- 判断下列sql语句有没有命中索引
select * from table1 where a = 10;
select * from table1 where a = 10 and b=20;
select * from table1 where a = 10 and b=20 and c=30;
select * from table1 where b = 10;
select * from table1 where b = 10 and c=30;
select * from table1 where a = 10 and c=30;
select * from table1 where c = 30;
select * from table1 where a = 10 and c = 30 and b = 20; (abc全走)=》mysql有一个内部优化器 会做一次内部优化。
根据以下的结论,可快速得出上述结果:
#### 结论:
如果有一个 2 列的索引 (a, b),则已经对 (a)、(a, b) 上建立了索引;
如果有一个 3 列索引 (a, b, c),则已经对 (a)、(a, b)、(a, b, c) 上建立了索引;
#### 结果:
select * from table1 where a = 10; # 命中索引 a
select * from table1 where a = 10 and b=20; # 命中索引 a b
select * from table1 where a = 10 and b=20 and c=30; # 命中索引 a b c
select * from table1 where b = 10; # NO
select * from table1 where b = 10 and c=30; # NO
select * from table1 where a = 10 and c=30; # 命中索引 a
select * from table1 where c = 30; # NO
# mysql有一个内部优化器 会做一次内部优化 使之优化为where a = 10 and b=20 and c=30
select * from table1 where a = 10 and c = 30 and b = 20; # 命中索引 a b c
mysql 锁机制
锁简介
锁是用来解决多个任务(线程、进程)在并发访问同一共享资源时带来的数据安全问题,虽然使用锁解决了数据安全问题,但是会带来性能的影响
锁的分类
1)从性能上划分:乐观锁和悲观锁
- 悲观锁
悲观的认为当前的并发是非常严重的,所以这种情况下任何操作都是互斥的。它保证了线程的安全,但牺牲了并发性
- 乐观锁:
乐观的认为当前的并发并不严重,因此对于读的情况,大家都可以进行,但是对于写的情况,会进行上锁
2)从数据操作的粒度上划分:表锁和行锁
- 表锁:对整张表上锁
MyISAM存储引擎天然支持表锁,换句话说,在MyISAM存储引擎的表中如果出现并发的情况,将会出现表锁的效果。MyISAM不支持事务,InnoDB支持事务
在InnoDB中上表锁:
# 对一张表上读锁/写锁格式:
lock table 表名 read/write;
# 例子
lock table t_user read;
# 查看当前会话对所有表的上锁情况
show open tables;
# 释放当前会话的所有锁
unlock tables;
- 行锁:对表中的某一行上锁
MyISAM只支持表锁,但不支持行锁,InnoDB可以支持行锁
在并发事务里,每个事务的增删改的操作都相当于是上了行锁
上行锁的方式:
# 方式1
# 对id是8的这行数据上了行锁
update t_user set name='zs' where id=8;
# 方式2
# 对id是8的这行数据上了行锁
select * from t_user where id=8 for update;
3)从数据库操作类型上划分:读锁和写锁
这两种锁都是属于悲观锁
- 读锁(共享锁)
可以同时对一行数据读,但是不能同时对一行数据写
- 写锁(排它锁)
在上了写锁之后,及释放写锁之前,整个过程中其他任务是不能进行任何的并发操作,如读和写
mysql死锁
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象
常见的解决死锁的方法:
- 在不同程序会并发存取多个表时,尽量约定以相同的顺序访问表,这样可以降低死锁机会,另外就是在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁产生概率
- 对于非常容易产生死锁的业务部分,可以尝试升级锁定颗粒度,通过表级锁定来减少死锁产生的概率
mysql 事务
什么是事务?
在数据库中,我们将一条 SQL 语句称为一次基本的操作。将若干条 SQL 语句“打包”在一起,共同执行一个完整的任务,这就是事务。比如说,在人员管理系统中,你删除一个人员,你既需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务
事务的特性
- 原子性
一个事务是一个最小的操作单位(原子),多条sql语句在一个事务中要么同时成功,要么同时失败,如果失败,则进行回滚
- 一致性
事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到
- 持久性
事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚
- 隔离性
同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰(比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账)。多个事务在并发访问下,提供了一套隔离机制,不同的隔离级别会有不同的并发效果
事务的隔离级别
- read uncommitted(读未提交)
在一个事务中读取到另一个事务还没有提交的数据,这种情况称之为脏读
- read committed(读已提交)
在一个事务中只会读取另一个事务已提交的数据,解决了脏读问题,但是这种情况下会出现不可重复读的问题,换句话说就是:在事务中重复读数据,数据的内容是不一样的
- repeatable read(可重复读)
在一个事务中每次读取的数据都是一致的,不会出现脏读和不可重复读的问题,但是这种情况下会出现幻读的问题
幻读举例:
在同一时刻,张三和李四各自开启了事务对同一张表进行操作,事务称之为a, b,在事务a中,张三插入了一条主键id为22的数据,随后进行了提交,在事务b中,李四在张三提交事务后,立即也插入了一条主键id为22的数据,但是mysql告诉它,因主键重复不能插入,李四查看自己的数据后,发现没有主键id为22的数据,这时候李四骂道:我草,活见鬼了,明明没有主键id为22的数据,你却提示我不能插入
解决幻读方案:
什么是MVCC?
MVCC(Multi-Version Concurrency Control)多版本并发控制,一般在数据库管理系统中,实现对数据库的并发访问,换句话来说就是寻求用更好的方式去处理读-写冲突,做到即使有读写冲突,也可以做到在不加锁的情况下进行非阻塞的并发读
在MySQL中,MySQL对于读,做了并发性的保障,让所有的读都是快照读,对于写,进行了MVCC版本控制,就是如果真实数据的版本比快照版本要新,那么写之前要进行一次快照更新,这样的话,既能够让读的并发性不受影响,又能够保证写数据的安全















 660
660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









