







文章目录
MergeTree系列共有的特性
1)分区【建表时可选】
可以手动合并分区
2)主键【建表时可选】
(1) ck主键可以重复
(2) ck主键中使用的索引是稀疏索引。默认8192
(3) 主键字段若和order by 字段有交集,则必须和order by字段顺序一致。比如 order by 字段是 (id,sku_id),那么主键必须是id 、(id,sku_id),不能是(sku_id,id)、sku_id
3)order by【建表时必须指定】
(1) 排序是分区内排序
(2) 为什么 order by 建表时必须指定
例如稀疏索引就依托于order by
4)建表时,表引擎必须指定
5)TTL【可选】
(1) 列级别的TTL
(2) 表级别的TTL
6)三大特有
(1) 只有MergeTree引擎,才支持对列的修改操作
(2) 只有MergeTree擎,才支持数据的更新和删除
(3) 只有MergeTree擎,才支持分区表
去重表:RepalcingMergeTree
1)去重时依据order by字段
2)以分区为单位进行去重
3)去重时机:分区合并时,但什么时候合并分区无法预知;同一批数据插入时(新版本v20.1.2.4以后)
4)数据去重策略有两种:
(1)如果没有指定ver版本号,则保留同一组中,最后插入的那个
(2)如果指定了ver版本号,则保留同一组中ver最大的
5)因为分区内的数据已经基于order by进行了排序,所以能够快速找到那些相邻的重复数据
drop table tb_replacingmergetree;
create table tb_replacingmergetree
(
uid UInt32,
name String,
city String,
ctime Datetime
) engine = ReplacingMergeTree(ctime) -- 将ctime字段,作为去重时的版本字段
partition by (city)
primary key (uid)
order by (uid, city);
insert into tb_replacingmergetree
values (1, 'zs', 'BJ', '2001-08-08 11:12:13'),
(1, 'zsss', 'BJ', '2001-12-11 11:12:13'),
(1, 'zss', 'BJ', '2001-10-11 12:12:13');
select * from tb_replacingmergetree;

聚合表:AggregatingMergeTree
1)聚合的key为order by字段
2)分区合并时触发汇总逻辑
3)以分区为单位聚合数据
4)聚合列如果未在引擎中指定,则会聚合主键以外的所有数值列,非数值列取第一个插入的
5)因为分区内的数据已经基于order by 排序,所以能够快速找到相邻且相同key的数据
6)AggregatingMergeTree是SummingMergeTree的升级版本
查询数据时使用:xxxMerge
插入数据时用:xxxState
求和表:SummingMergeTree
1)分区合并时触发聚合逻辑,但什么时候合并分区无法预知
2)分区内聚合
3)聚合列如果未在引擎中指定,则会聚合主键以外的所有数值列,非数值列取第一个插入的
4)因为分区内的数据已经基于order by 排序,所以能够快速找到相邻且相同key的数据
更新表:CollapsingMergeTree
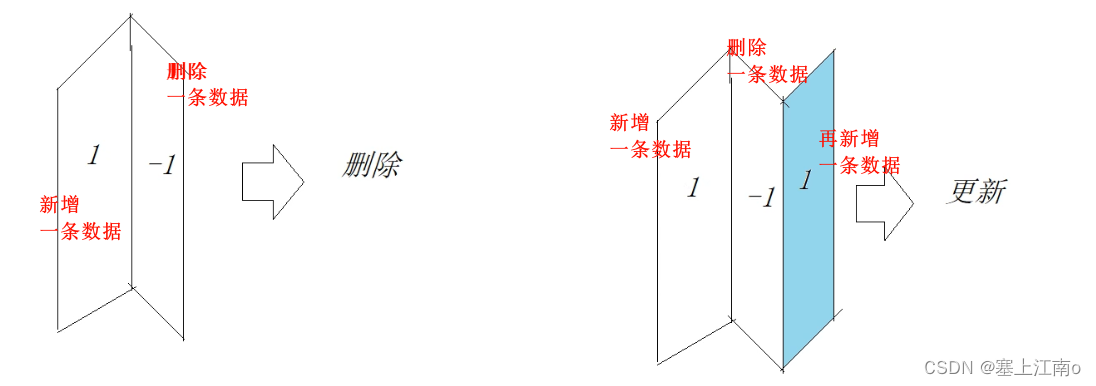
功能:主要用《以增代删》的思想,来实现行级数据的修改和删除
实现思想:定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除
drop table tb_collapsingmergetree_1;
create table tb_collapsingmergetree_1
(
uid UInt32,
name String,
city String,
sign Int8
) engine = CollapsingMergeTree(sign)
partition by city
primary key uid
order by (uid, name);
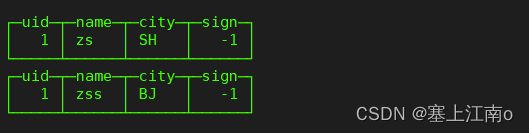
insert into tb_collapsingmergetree_1
values (1, 'zs', 'BJ', 1),
(1, 'zss', 'BJ', -1),
(1, 'zs', 'SH', -1),
(1, 'zs', 'BJ', -1);
select *
from tb_collapsingmergetree_1;
特点:
1)折叠数据时依据order by字段
2)以分区为单位进行折叠
3)折叠时机:分区合并时,但什么时候合并分区无法预知;同一批数据插入时(新版本v20.1以后)
4)因为分区内的数据已经基于order by进行了排序,所以能够快速找到那些相邻的重复数据
缺点: 只能从后往前抵消数据(即1、-1能抵消;-1、1不能抵消)
drop table tb_collapsingmergetree_1;
create table tb_collapsingmergetree_1
(
uid UInt32,
name String,
city String,
sign Int8
) engine = CollapsingMergeTree(sign)
order by (uid, name);
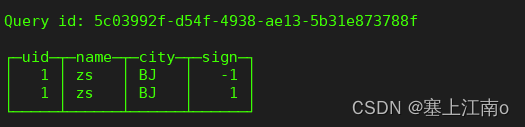
insert into tb_collapsingmergetree_1
values (1, 'zs', 'BJ', -1),
(1, 'zs', 'BJ', 1);
select *
from tb_collapsingmergetree_1;
使用VersionedCollapsingMergeTree引擎解决该问题:
drop table tb_versionedcollapsingmergetree;
create table tb_versionedcollapsingmergetree
(
uid UInt32,
name String,
ver UInt8,
sign Int8
) engine = VersionedCollapsingMergeTree(sign,ver)
order by (uid, name);
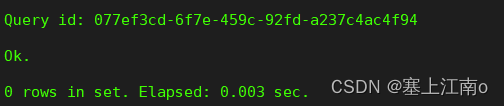
insert into tb_versionedcollapsingmergetree
values (1, 'zs', 7, -1),
(1, 'zs', 7, 1);
select *
from tb_versionedcollapsingmergetree;














 2304
2304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









