






1.为什么学习Python?
说到这个问题,就觉得有点难以启齿。自己对学习Java一直很抗拒,Python相对Java来说比较简单,再加上硕士期间一直都是使用Python进行数据挖掘和人工智能方面的实验,所以就选择了Python这门语言。
2.通过什么途径学习Python?
主要是自学,通过B站和Python方面的资料,Python基础强烈推荐黑马程序员[黑马程序员]python3.7从入门到入门(零基础)_哔哩哔哩_bilibili,Django推荐达内的课程Django+Redis全套视频教程(含项目实战)_达内Python进阶_哔哩哔哩_bilibili和银角大王-武沛齐的课程最新Python的web开发全家桶(django+前端+数据库)_哔哩哔哩_bilibili等等。通过一段时间的学习,发现这些老师讲的都比较通俗易懂,适合初入Python学习的小白。
3.Python和Java、C、C++等其他语言的区别?
C++、Java和Python都是⾯向对象的编程语⾔。其中C++和Java都是强类型语⾔,⽽Python是⼀种弱类型语⾔。
1)Python:快速开发应⽤程序
Python⽐较容易学习,语法很简单,融⼊了很多现代编程语⾔的特性。python的库⾮常丰富,可以迅速地开发程序,⽆论是⽹站还是⼩游戏都⾮常⽅便。不过,python的脚本的运⾏效率较低,不适合对运⾏效率要求较⾼的程序。
Python是⼀种脚本语⾔。它更适合⽤来做算法。Python简单易学,基于C++创造的,它们的区别主要体现在,C++效率⾼,编程难;Python效率低,编程简单。
(1)⽤途:爬⾍,Web开发,视频游戏开发,桌⾯GUIs(即图形⽤户页⾯),软件开发,架构等。
(2)优势:拥有强⼤的开源类库,开发效率⾼。
(3)缺点:运⾏速度低于编译型语⾔,在移动计算领域乏力。
2)Java:健壮的⼤型软件
Java的语法⽐较规则,采⽤严格的⾯向对象编程⽅法,同时有很多⼤型的开发框架,⽐较适合企业级应⽤。Java的学习曲线较长,不仅要学习语⾔相关的特性,还要⾯向对象的软件构造⽅法,在此之后要学习⼀些框架的使⽤⽅法。
(1)⽤途:Android & IOS 应⽤开发,视频游戏开发,桌⾯GUIs(即图形⽤户页⾯),软件开发,架构等。
(2)优势:市场需求旺盛,拥有强⼤的类库。
(3)缺点:占⽤⼤量的内存,启动时间较长,不直接⽀持硬件级别的处理。
3)C++:需求效率的软件
C++更接近于底层,⽅便直接操作内存。C++不仅拥有计算机⾼效运⾏的实⽤性特征,同时还致⼒于提⾼⼤规模程序的编程质量与程序设计语⾔的问题描述能⼒。C++不仅是C和Java特点的结合。实际上C++是多范式编程语⾔,不仅⽀持传统的⾯向过程编程,也⽀持⾯向对象编程。
4. 简述解释型和编译型编程语言
a.编译型语言
编译型语言在执行之前要先经过编译过程,编译成为一个可执行的机器语言的文件,比如exe。因为翻译只做一遍,以后都不需要翻译,所以执行效率高。
典型代表:C语言,C++。
优缺点:执行效率高,缺点是跨平台能力弱,不便调试。
b.解释型语言
解释性语言编写的程序不进行预先编译,以文本方式存储程序代码。执行时才翻译执行。程序每执行一次就要翻译一遍。
代表语言:python,JavaScript。
优缺点:跨平台能力强,易于调,执行速度慢。
5.Python解释器种类以及特点
CPython:由C语言开发,而且使用范围最为广泛
IPython:基于CPython的一个交互式计时器。
PyPy:采用JIT技术,对Python代码进行动态编译,可以显著提高Python代码的执行速度。
JPython:运行在Java平台上的解释器,直接把Python代码编译成Java字节码执行。
IronPython:运行在微软 .NET 平台上的解释器,把Python编译成 .NET的字节码。
6.位和字节的关系
1字节=8位
二进制数系统中,位简记为b,也称为比特,每个二进制数字0或1就是一个位(bit)。位是数据存储的最小单位,其中8 bit 就称为一个字节(Byte)。
字节(Byte )是计算机信息技术用于计量存储容量的一种计量单位,作为一个单位来处理的一个二进制数字串,是构成信息的一个小单位。
7.b、B、KB、MB、GB的关系
1 B = 8 b
1 KB = 1024 B
1 MB = 1024 kB
1 GB = 1024 MB
8.PEP8规范
PEP是Python Enhancement Proposal的缩写,通常翻译为“Python增强提案” —— 写 Python 代码需要遵循的要求。
1、缩进,4个空格的缩进(编译器都可以完成此功能),不适用Tab,更不能混合使用Tab和空格;
2、每行最大长度为79,换行可以使用反斜杠。最好使用圆括号,换行点再操作符的后边敲回车;
3、不要在import中同时导入多个库。比如import os,sys;
4、模块命名尽量短小,使用全部小写的方式,可以使用下划线;
5、包命名尽量短小,使用全部小写的方式。不可以使用下划线;
6、类的命名使用CapWords的方式,模块内部使用的类采用--CapWords的方式;
7、函数命名使用全部小写的方式,可以使用下划线;
8、异常命名使用CapWords+Error后缀的方式;
9、常量命名使用全部大写的方式,可以使用下划线;
10、类的属性(方法和变量)命名使用全部小写的方式,可以使用下划线;
11、类方法第一个参数必须是self,而静态方法第一个参数必须是cls;
9.Python递归的最大层数
Python的最大递归层数是可以设置的,默认的在window上的最大递归层数是 998。可以通过sys.setrecursionlimit()进行设置,但是一般默认不会超过3925-3929这个范围。
10.ASCII、Unicode、UTF-8、GBK
ASCII:在计算机内部,所有信息最终都表示为一个二进制的字符串。8位一个字节,1个字节表示一个字符。每一个二进制位有0和1两种状态,因此8个二进制位可以组合出256种状态。ASCII码一共规定了128个字符的编码。它的范围基本只有英文字母、数字和一些特殊符号 。
Unicode:又称万国码,将世界上所有的符号都纳入其中,每一种符号都给予独一无二的编码,防止乱码。unicode码一般是用两个字节表示一个字符,特别生僻的用四个字节表示一个字符。
UTF-8:变长码,UTF-8是在互联网中使用最多的对Unicode的实现方式。如果是英文字符,则采用ascii编码,占用一个字节。如果是常用汉字,就占用三个字节,如果是生僻的字就占用4~6个字节。
GBK:GBK编码是对GB2312的扩展,完全兼容GB2312,GB2312是对ASCII码的中文扩展。使用双字节码,是用来编码汉字的。字符占用两个字节,英文占用一个字节。
11.字节码和机器码的区别
机器码 是计算机可以直接执行,并且执行速度最快的代码。
字节码 是一种中间状态的(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码;字节码通常情况下已经经过编译,但与特定机器码无关。字节码与特定的硬件环境无关;字节码的实现方式是通过编译器和虚拟机器。编译器将源码编译成字节码,特定平台上的虚拟机器将字节码转译为可以直接执行的指令。对比字节码与机器码
机器码就是说计算机能读懂的代码,简单点说就是给计算机执行的二进制代码;
字节码,是JAVA语言专有的,它是让JVM来执行的二进制代码;
机器码和字节码都是二进制代码,但是由于执行它的环境不一样,所以它们存在一些指令集上的区别。
12.三元运算规则以及应用场景
三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值。
格式:
[true] if [expression] else [false]
result = 值1 if 条件 else 值213.用一行代码实现数值交换: a = 1,b = 2
a = 1
b = 2
a, b = b, a14.Python3和Python2中 int 和 long的区别
Python3 int类型的范围是动态长度的。
Python2 long类型的范围是无限大小。
15.xrange和range的区别
python中
1)range 是生成一个列表;
2)xrange 用法与 range 完全相同,不同的是生成的不是一个list对象,而是一个生成器;
3)在生成很大的数字序列时候,用 xrange 会比 range 性能优很多,因为不需要一上来就开辟一块很大的内存空间;
4)xrange 和 range 都在循环的时候使用。
16.文件操作时:xreadlines和readlines的区别
二者使用时相同,但返回类型不同,xreadlines返回的是一个生成器,readlines返回的是list。
17.列举布尔值为False的常见值
bool(0) bool(-0) bool(None) bool() bool(False)
bool([]) bool(()) bool({}) bool(0.0)python中元素为假:
0,空字符串,空列表,空字典,空元组,None,Flase
18.字符串、列表、元组、字典中常用的5个方法
字符串:不可变类型
1)find 通过元素找索引,可切片,找不到返回-1
2)index 找不到报错
3)split 由字符串分割成列表,默认按空格
4)upper 全大写,lower 全小写
5)startswith endswith 判断以什么为开头、结尾
6)format 格式化输出
7)strip 默认去掉两侧空格,有条件,lstrip,rstrip
8)count 查找元素的个数,若没有返回0
9)replace(old, new,次数)
字典:字典的键必须是可哈希的 不可变类型,在同一个字典中,键(key)必须是唯一的。
1)无序(不能索引)2)数据关联性强
key: 输出所有的键
clear:清空
dic:删除的键如果没有则报错
pop:键值对删,有返回,没有原来的键会报错(自行设置返回键就不会报错)
popitem:随机删键值对
del:删除的键如果没有则报错
列表:
append:在后面添加。
Insert:按照索引添加,
expend:迭代着添加。
pop:删除 有返回值
remove:可以按照元素去删
clear:清空列表
del:删除
count():统计某个元素在列表中出现的次数
index():从列表中找出某个值第一个匹配项的索引位置
reverse() :反向
sort():对原列表进行排序
列表是有序的对象集合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
元组:不可变类型
len():计算元组元素个数
max():返回元组中元素最大值
min():返回元组中元素最小值
tuple(list1):将列表转换为元组
注意
1、与字符串一样,元组的元素不能修改
2、元组也可以被索引和切片
3、注意构造包含0或1个元素的元组的特殊语法规则
4、元组也可以使用 + 操作符进行拼接
Set(集合):是一个无序不重复元素的序列
可以使用大括号 { } 或者 set() 函数创建集合注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
19.lambda表达式格式以及应用场景
lambda表达式 常用来声明匿名函数,即没有函数名字的临时使用的函数。lambda表达式只可以包含一个表达式,不允许包含其他复杂的语句,但在表达式中可以调用其他函数,并支持默认值参数和关键参数,该表达式的计算结果相当于函数的返回值。
f = lambda x, y, z: x+y+z
print(f(1, 2, 3))20.pass的作用
pass的主要作用就是占位,让代码整体完整。
21.*arg和**kwarg作用
*args和**kwargs都是用于函数定义时的功能性标识,其主要作用是参数传递。
*args:位置参数,输出元组格式
**kwargs:关键字参数,输出字典格式
22. is 和 == 的区别
Python是一种面向对象的语言,Python中对象包含三种基本要素:id(返回的是对象的地址)、type(返回的是对象的数据类型)及value(对象的值)。
is 和 == 都可以对两个对象进行比较,而且它们的返回值都是布尔类型。但是它们比较的内容是不同的。
is 比较的是两个对象的id是否相等,也就是比较两个对象是否为同一个实例对象,是否指向同一内存地址。
== 比较两个对象的内容是否相等,默认会调用对象的 __eq__ 方法。
23.Python的可变类型和不可变类型
可变类型:List(列表)、Dictionary(字典)、Sets(集合)
不可变类型:Number(数字)、String(字符串)、Tuple(元祖)
24.简述Python的深浅拷贝以及应用场景
L1 = [1, 2, 3] # L1变量指向的是一个可变对象(列表)
L2 = L1 # 将L1值赋值给L2,两者共同引用同对象
L1[0] = 10 # 列表可变,改变L1中的第一个元素的值
id(L1)
id(L2) # 指向同一内存地址
L1
L2 # 改变后 L1 L2 同时改变,因为对象本身值发生改变
# 如果不想改变列表L2的值,有两种方法:切片和copy
L2 = L1[1:]
id(L1)
id(L2) # 不是指向同一个内存地址切片可以应用于所有的序列,包括列表、字符串、元组等,但切片不能应用于字典,字典只能使用拷贝方法——深浅拷贝,可用于序列,也可用于字典。
import copy
L2 = copy.copy(L1) # 浅拷贝 只拷贝顶级的对象(父级对象)
L2 = copy.deepcopy(L1) # 深拷贝 拷贝所有对象,顶级对象及其嵌套对象(父级对象及其子对象)
深浅拷贝的区别:
深浅拷贝都是对源对象的复制,占用不同的内存空间;
如果源对象只有一级目录的话,源做任何改动,不影响深浅拷贝对象;
如果源对象不止一级目录的话,源做任何改动,都要影响浅拷贝,但不影响深拷贝;
序列对象的 切片其实是浅拷贝,即只拷贝顶级的对象。
25.Python垃圾回收机制
Python的垃圾回收机制采用的是引用计数机制为主、标记清除和分代回收为辅的结合机制,当对象的引用计数变为0时,对象将被销毁,除了解释器默认创建的对象外(默认对象的引用计数永远不会变成0)。
在Python中,主要通过引用计数进行垃圾回收;通过 “标记-清除” 解决容器对象可能产生的循环引用问题;通过 “分代回收” 以空间换时间的方法提高垃圾回收效率。
26.dict.fromkeys()
fromkeys 时的连坐机制
Python 字典 fromkeys() 函数用于创建一个新字典,以序列 seq 中元素做字典的键,value 为字典所有键对应的初始值。
fromkeys() 语法:
dict.fromkeys(seq[, value])v = dict.fromkeys(['k1', 'k2'], [])
print(v)
v['k1'].append(666)
print(v)
v['k1'] = 777
print(v)运行结果:
{'k1': [], 'k2': []}
{'k1': [666], 'k2': [666]}
{'k1': 777, 'k2': [666]}27.列举常见的内置函数






28.filter、map、reduce的作用
map:根据函数对指定序列做映射
作用:生成一个新数组,遍历原数组,将每个元素拿出来做一些变化然后放入到新的数组中。
参数:函数、序列(可迭代对象)
返回值:返回列表(Python2)、返回迭代器(Python3)
list(map(abs, [-5, 7, -2])) # [5, 7, 2]
filter:过滤函数,新的内容少于等于原内容时,才能使用filter
作用:过滤序列,过滤不符合条件的元素,返回由符合条件元素组成的新列表
参数:函数、可迭代对象
返回值:列表
def s(x):
if x > 5:
return True
print(list(filter(s, [4, 5, 6])))reduce:对于序列内所有元素进行累计操作
作用:将数组中的元素通过回调函数最终转换为一个值
参数:函数、可迭代对象
返回值:累计结果
from functools import reduce
def add(x, y):
return x + y
print(reduce(add, [1, 2, 3]))29.一行代码实现九九乘法表
print("\n".join("\t".join(["%s*%s=%s" % (y, x, x * y) for y in range(1, x + 1)]) for x in range(1, 10)))30.如何安装卸载第三方模块?
pip install 第三方模块=版本号
pip uninstall 第三方模块31.至少列举8个常见的模块?
1)time模块
time.time() 用于数据的唯一标识 从1970年开始算的
time.sleep() 几秒之后才去执行
time.localtime() 当前时区时间time.strftime(fmt[,tupletime]) 格式化时间
2)os模块:负责程序与操作系统的交互,提供了访问操作系统底层的接口
os.mkdir('dirname') 生成单级目录
os.makedirs('dirname1/.../dirnamen2') 生成多层目录
os.listdir('dirname') 列举目录下所有资源
os.romeve('file_path') 删除文件
os.rmdir('dirname') 删除单层空目录
os.removedirs('dirname1/.../dirnamen') 移除多层空目录
3)random模块
random.random() # 0 到 1 之间的随机小数
random.randint(a, b) # [a, b] 之间的随机整数
random.randrange((a, b) # [a, b)
random.uniform(a, b) # (a, b) 之间的小数
4)json:序列化
json语言主要用来存放数据,是各语言之间的数据交互的媒介,最常见与前后端交互。
1.就是 {} 和 [] 的组合,字典和列表
2.{} 的 key 必须是字符串,并且用 ""
3.{},[] 中的值支持的类型:dict | list | int | float | bool | str | null
5)hashlib 加密
md5 是一种不可逆加密
解密方式:碰撞解密
lock_obj = hashlib.md5()
lock_obj.update(b'...')
lock_obj .hexdigest()6)re模块
正则:有语法的字符串,用来匹配目标字符串
应用场景:爬虫、判断字符串内容是否满足某种规则...
7)datetime模块
datetime.datetime.now() 当前时间
datetime.datetime.now() + datetime.timedelta(days=-1) 昨天
datetime_obj.replace([...]) 修改时间
datetime.date.fromtimestamp(timestamp) 格式化时间戳
8)sys模块:负责程序与Python解释器的交互,提供了一系列的函数和变量,用于操控Python的运行时环境。
sys.exit() 退出程序
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.maxunicode 最大的Unicode值
sys.modules 返回系统导入的模块字段,key是模块名,value是模块
sys.path 返回模块的搜索路径
sys.platform 返回操作系统平台名称
sys.stdout 标准输出
sys.stdin 标准输入
sys.stderr 错误输出
sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
sys.api_version 解释器的C的API版本
32.re的match和search的区别
re.match:只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search:匹配整个字符串,直到找到一个匹配。
33.什么是正则的贪婪匹配
1)贪婪匹配
匹配尽可能多的字符
2)非贪婪匹配
匹配尽可能少的字符
import re
data = "adcadcabcabchlililjoljilabcadc"
print(re.findall('adc.*adc', data)) # 贪婪匹配
print(re.findall('adc.?adc', data)) # 非贪婪匹配
结果:
['adcadcabcabchlililjoljilabcadc']
['adcadc']
34.1 < 2 == 2
1 < 2 == 2 # 链式比较 # 1 < 2 and 2 == 235.def func(a, b=[]) 存在的坑
def func(a, b=[]):
b.append(a)
print(b)
func(1)
func(1)
func(1)
func(1)
结果:
[1]
[1, 1]
[1, 1, 1]
[1, 1, 1, 1]
函数的第二个默认参数是一个list,第一次执行时实例化一个list,第二次执行还是用第一次执行时实例化的地址存储(list 是可变类型,每次调用不会重新初始化 [])。每次结果只输出 [1],默认参数应设置为 None(默认参数必须执行不可变类型)。
36. “1,2,3” 变成 [‘1’,’2’,’3’] [‘1’,’2’,’3’]变成[1,2,3]
a = '1,2,3'
print(a.split(',')) # ['1', '2', '3']a = ['1', '2', '3']
print([int(i) for i in a])37.比较:a = [1, 2, 3] 和 b = [(1), (2), (3)] 以及c = [(1,), (2,),(3,)]
a = [1,2,3] 正常的列表
b = [(1),(2),(3)] 列表中的元素加上括号,但是括号内只有一个元素(没有逗号),其数据类型是元素本身的数据类型
c = [(1,),(2,),(3,)] 列表中的元素类型都是元组类型
38.删除列表中重复值
a = [1, 1, 2, 2, 4, 5, 6, 6]
print(list(set(a)).sort()) # 利用 set 集合的特点,无序、去重复39.如何在函数中设置一个全局变量
global 变量40.常用的字符串格式化
a = 3
print(f"a = {a}")
print("a = %s" % a)
print("a = {}".format(a))41.用代码简述stack
栈和队列是两种基本的数据结构,同为容器类型,两者的根本区别在于栈是先进后出,队列是先进先出。
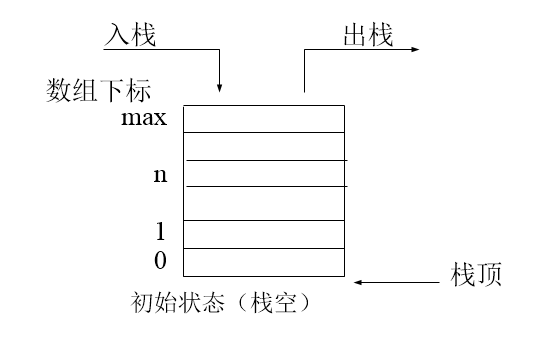
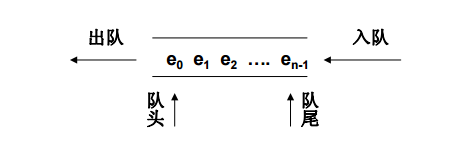
42.简述生成器、迭代器、可迭代对象以及它们的应用场景
可迭代对象:
字符串、列表、集合、字典、元祖、range都是可迭代对象,迭代器本身也是可迭代对象。
可以通过dir() 查看其内部有没有__iter__方法,如果有这个方法就是可迭代对象。
可迭代对象的特点:
可以使用for循环、in判断、生成迭代器操作
isinstance(obj, Iterable) # 判断一个对象是否是可迭代对象迭代器:
含有__iter__和__next__ 方法的可迭代对象就是迭代器。迭代器一定是可迭代对象,是一个可以记住遍历位置的对象。
生成器:
含有field关键字,生成器也是迭代器,调用__next__把函数变成迭代器。
装饰器:在Python中,一边循环一边计算的机制
装饰器本身就是一个函数,可以用来装饰类、类的方法和属性。
装饰器有助于检查某个人是否被授权使用一个web应用端点。
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。能够在不修改原函数代码的的基础上,在执行前后进行定制操作。
def decor(func):
def inner(*args, **kwargs):
ret = func(*args, **kwargs)
return ret
return inner应用场景:
1.日志打印器
2.时间计时器
def time_decor(func):
def wrapper(*args, **kwargs):
t1 = time.time()
func(*args, **kwargs)
t2 = time.time()
expend_time = t2 - t1
print(f"花费的总时间:{expend_time }")
return wrapper43.什么是闭包
局部变量无法共享和长久保存,而全局变量可能造成变量污染,由此产生闭包。
闭包是由函数及其相关的引用环境组合而成的实体。
闭包,是引用了自由变量的函数,就是能够读取其它函数内部变量的函数。其指的是一个拥有许多变量和绑定了这些变量的环境表达式(通常是一个函数),因而这些变量也是该表达式的一部分。
特点:
占用更多内存
不容易被释放
44.如何生成一个随机数
import random
random.randomint(0, 9) # 生成[0, 9]之间的随机数45.使用Python删除一个文件
使用Python删除一个文件或文件夹,使用os模块
import os
os.remove(path) # path是文件的路径
os.rmdir(path) # path是文件夹路径,注意文件夹需要为空的才能被删除46.什么是面向对象
面向对象是一种思想,是相对面向过程而言的。面向对象就是把现实中的事物都抽象成为程序设计中的“对象”(将功能等通过对象实现,将功能封装进对象中,让对象去实现具体细节),其基本思想是一切皆对象,是一种自上而下的设计语言,先设计组件,在进行拼接。
面向对象的三大特征:封装、继承、多态
面向对象 - 封装
将一类事物的属性和行为抽象成一个类,使其属性私有化,行为公开化,提高了数据的隐私性的同时,使代码模块化,提高了代码的复用性。
意义:
1)将属性和方法放到一起作为一个整体,然后通过实例化对象来处理;
2)隐藏内部实现细节,只需要和对象及其属性和方法进行交互;
3)对列的属性和方法增加访问权限控制。
面向对象 - 继承
继承描述的是多个类之间的所属关系,进一步提高了代码的复用性。继承是多态的前提。即一个派生类继承基类的属性和方法。
面向对象 - 多态
定义时的类型和运行时的类型不一样,是父类或接口定义的引用变量可以指向子类或具体实现类的实例对象。
优点:提高了程序的扩展性
缺点:当父类引用指向子类对象时,虽提高了扩展性,但只能访问父类中具备的方法,不可访问子类中的访问,即访问的局限性。
47.面向对象的深度优先和广度优先
深度优先:就是往深的地方优先查找或遍历。
广度优先:就是往广的地方优先查找或遍历。(一层一层遍历)
48.面向对象中的super的作用
super() 函数是用于调用父类的一个方法。
super 可以解决多重继承问题的,单继承时可以直接使用类名调用父类方法,但是多继承中,会会出现查找顺序(MRO,就是类的方法解析顺序,其实也就是继承父类方法时的顺序表)、重复调用(钻石继承)等问题。
49.functools中的函数
functools 模块主要是为函数式编程而设计的,用于增强函数功能。为可调用对象定义高阶函数或操作。
update_wrapper
使用 partial 包装的函数是没有 __name__ 和 __doc__ 属性。
update_wrapper 作用:将被包装函数的 __name__ 等属性,拷贝到新的函数中去。
wraps
warps 函数作用:在装饰器拷贝被装饰函数的__name__。就是在update_wrapper上进行包装。
reduce
作用:将一个序列归纳为一个输出。
# 语法
reduce(function, sequence, startValue)
from functools import reduce
print(reduce(lambda x, y: x + y, (1, 2))) # 3cmp_to_key
在 list.sort 和内建函数 sorted 中都有一个 key 参数
x = ['aaa', 'aa', 'a']
x.sort(key=len)
print(x)50.面向对象中带双下划线的魔术方法
__new__ :生成实例
__init__ :生成实例的属性
__call__ :生成对象加 () 触发执行
__del__ :析构方法,当对象在内存中被释放时,自动触发执行
__str__ :打印对象时,默认输出该方法的返回值
__doc__ :类的描述信息,该描述信息无法被继承
__len__ :len() 调用对象会返回 __len__ 方法 return的值
51.如何判断是函数和方法
函数可以被直接调用,方法通过对象调用。
52.静态方法和类方法的区别
Python会自动绑定类方法的第一个参数,类方法的第一个参数(通常参数名是cls)会自动绑定到类本身;但对于静态方法则不会自动绑定。
类方法通过 @classmethod 装饰器实现,类方法和普通方法的区别是,类方法只能访问类变量,不能访问实例变量。
静态方法通过 @staticmethod 进行装饰,静态方法不需要多定义参数,可以通过实例对象和类对象来访问。静态方法只能调用静态成员或方法,不能调用非静态方法或者成员。
53.反射及应用场景
反射的定义:主要是应用于类的对象上,在运行时,将对象中的属性和方法反射出来。
使用场景:可以动态的向对象中添加属性和方法。也可以动态的调用对象中的方法或者属性。
反射的常用方法:
1.hasaattr(obj,str)
判断输入的str字符串在对象obj中是否存在(属性或方法),存在返回True,否则返回False
2.getattr(obj,str)
将按照输入的str字符串在对象obj中查找。如找到同名属性,则返回该属性;如找到同名方法,则返回方法的引用,
想要调用此方法得使用 getattr(obj,str)()进行调用。
如果未能找到同名的属性或者方法,则抛出异常:AttributeError。
3.setattr(obj,name,value)
name为属性名或者方法名,value为属性值或者方法的引用
1) 动态添加属性。如上
2)动态添加方法。首先定义一个方法。再使用setattr(对象名,想要定义的方法名,所定义方法的方法名)
4.delattr(obj,str)
将你输入的字符串str在对象obj中查找,如找到同名属性或者方法就进行删除
54.Metaclass作用及应用场景
元类就是类的类。创建类就是为了创建类的实例对象,元类用来创建类(对象)。
作用:指定类是由谁创建的。
类的 Metaclass 默认是 type,可以指定类的 metaclass 值。
type 就是 Python 用来创建所有类的元类。
55.单例模式的实现方法
单例模式(Singleton Pattern)是一种简单的对象创建型模式。该模式保证一个类仅有一个实例,并提供一个访问它的全局访问点。
实现单例模式:
将构造方法私有化,杜绝使用构造器创建实例;
自身创建唯一的一个实例,并提供全局访问点。
优点:
节约空间(对象都指向同一内存地址)
方法一:
实例化一个对象,需要时直接import导入这个对象,而不再是实例化一个对象。
方法二:
实例化一个对象时,首先执行类的 __new__ 方法实例化对象,然后再执行 __init__ 方法对这个对象进行初始化。
class SingPat(object):
def __init__(self):
print("初始化对象")
def __new__(cls, *args, **kwargs):
# 实例化一个对象
cls.obj = object.__new__(cls)
return cls.obj
SingPat()方法三:
通过装饰器 @Sing_Class 实现
def Single_Class(cls):
class_dict = {} # 存储类对象
def single(*args, **kwargs):
if cls not in class_dict:
class_dict[cls] = cls(*args, **kwargs)
return class_dict[cls]
else:
return class_dict[cls]
return single
@Single_Class
class SingPat(object):
pass
s1 = SingPat()
s2 = SingPat()
print(s1) # <__main__.SingPat object at 0x000001A10D3711D0>
print(s2) # <__main__.SingPat object at 0x000001A10D3711D0>56.异常处理
try:
# 需要执行的主体函数
except Exception as e:
print(f'抛出异常:{e}')
# 主动抛出异常
raise TypeError("自定义异常信息")57.面向对象的MRO
MRO(Method Resolution Order),方法解析顺序,它指的是一棵类继承树,当调用最底层类对象所对应的方法时,Python解释器在类继承树上搜索方法的顺序。对于一棵类继承树可以通过最底层方法 mro() 或是 __mro__ 的属性获得它的MRO。
class A(object):
def f(self):
print("A.f")
class B(A):
def f(self):
print("B.f")
class C(A):
def f(self):
print("C.f")
class D(B, C):
def f(self):
print("D.f")
print(D.mro())
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
58.isinstance作用以及应用场景
isinstance() 是Python中的一个内建函数,用来判断一个对象的变量类型。
print(isinstance(1, int))
print(isinstance(1, str))59.json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
可以处理的数据类型包括:string、int、list、tuple、dict、bool、null# 自定义时间序列化转换器
import json
from json import JSONEncoder
from datetime import datetime
class ComplexEncoder(JSONEncoder):
def default(self, obj):
if isinstance(obj, datetime):
return obj.strftime('%Y-%m-%d %H:%M:%S')
else:
return super(ComplexEncoder,self).default(obj)
d = { 'name':'alex','data':datetime.now()}
print(json.dumps(d,cls=ComplexEncoder))60.json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
json.dumps将一个Python数据结构转换为JSON
import json
data = {
'name' : 'myname',
'age' : 20,
}
json_str = json.dumps(data)
在dumps函数中添加参数ensure_ascii=False即可解决
61.什么是断言,及其应用场景
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。
>>> assert True # 条件为 true 正常执行
>>> assert False # 条件为 false 触发异常
Traceback (most recent call last):
File "E:/PycharmProjects/sass/test.py", line 18, in <module>
assert False
AssertionError62.列举目录下的所有文件
import os
print(os.listdir())63.简述 yield 和 yield from 关键字
def generator():
for i in range(3):
yield i
def generator2():
yield from generator() # yield from iterable本质上等于 for item in iterable: yield item的缩写版
yield from [1, 2, 3]
yield from range(3)
print()
for i in generator():
print(i, end=' ') # 0 1 2
for i in generator2():
print(i, end=' ') # 0 1 2 1 2 3 0 1 264.with statement 的作用及优点
with 语句的作用是通过某种方式简化异常处理,上下文管理器的一种
with open(file='test.txt', mode='w') as f:
f.write('Hello world!')with 语句会在嵌套的代码执行之后,自动关闭文件。优点是无论嵌套的代码是以何种方式结束的,它都自动关闭文件。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









