







我的想法:
按常规思路保存之前的前缀和,结果超时
class Solution:
def subarraysDivByK(self, nums: List[int], k: int) -> int:
list_sum=0
pre_sum_list=[]
ans=0
for num in nums:
list_sum+=num
if list_sum%k==0:
ans+=1
pre_sum_list.append(list_sum)
for pointer in range(0,len(pre_sum_list)-1):
if (list_sum-pre_sum_list[pointer])%k==0:
ans+=1
return ans
标准解法:
class Solution:
def subarraysDivByK(self, nums: List[int], k: int) -> int:
cnt = [1]+[0]*(k-1)
som,ans = 0,0
for num in nums:
som += num
cnt[som%k]+=1
for i in cnt:
ans += i*(i-1)//2
return ans
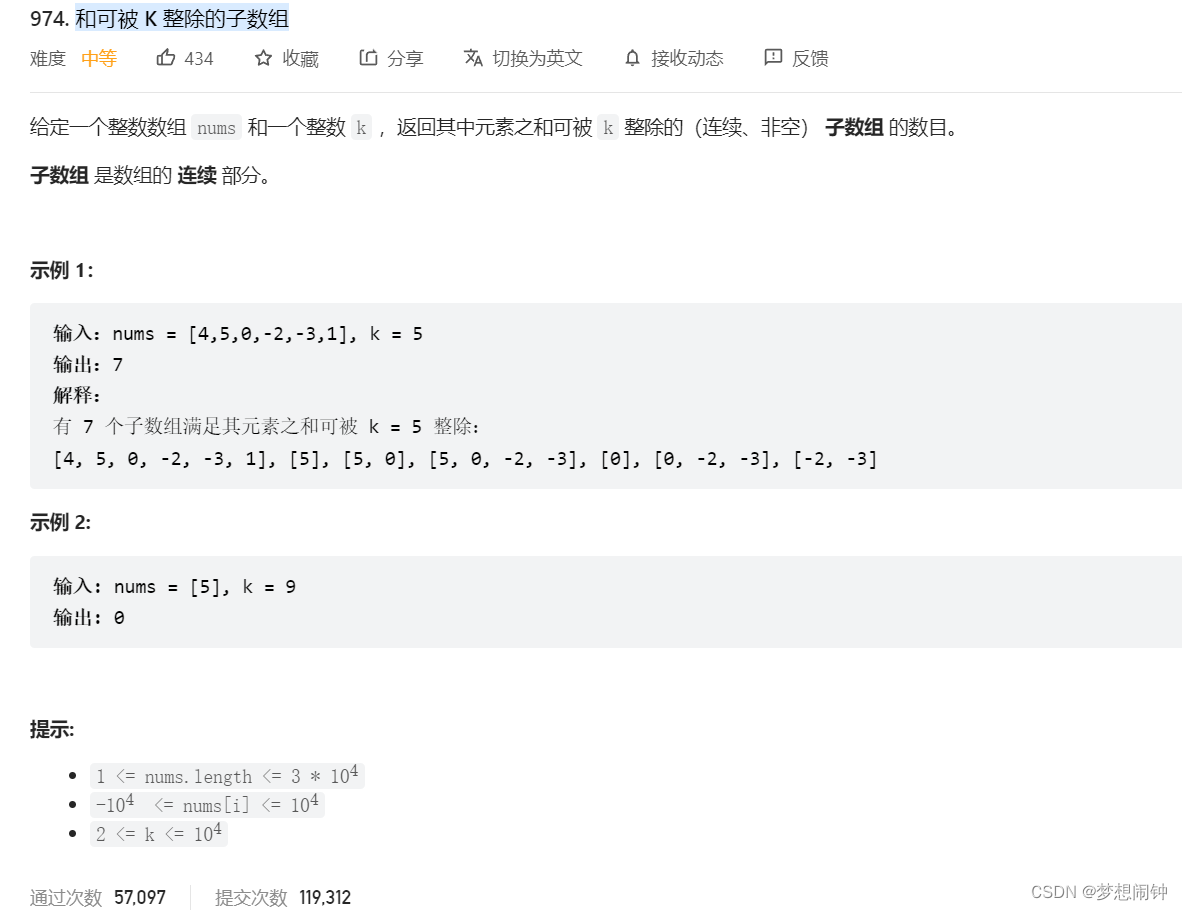
其他思路:
需要推出p[j] % k = p[i - 1] % k是关键
class Solution:
def subarraysDivByK(self, nums: List[int], k: int) -> int:
# 用hash表记录模值出现的次数
records = dict({0: 1})
prefix_sum = 0
result = 0
for num in nums:
# 求出每个元素对应的的前缀和
prefix_sum += num
# 求出每个元素对K的模
mod = prefix_sum % k
# 模值出现的次数
count = records.get(mod, 0)
# 累加次数
result += count
# 更新hash表中保存的次数
records[mod] = count + 1
return result














 320
320











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









