







一. 学习率
- 学习率 learning_rate: 表示了每次参数更新的幅度大小。学习率过大,会导致待优化的参数在最小值附近波动,不收敛;学习率过小,会导致待优化的参数收敛缓慢
- 在训练过程中,参数的更新向着损失函数减小的方向
- 参数的更新公式为:
Wn+1 = Wn - learning_rate▽ -
假设损失函数 loss = (w + 1)^2。梯度是损失函数 loss 的导数为 ▽ = 2w + 2 。
-
如参数初值为5,学习率为 0.2,则参数和损失函数更新如下:
1次 ·······参数w: 5 ·················5 - 0.2 * (2 * 5 + 2) = 2.6
2次 ·······参数w: 2.6 ··············2.6 - 0.2 * (2 * 2.6 + 2) = 1.16
3次 ·······参数w: 1.16 ············1.16 - 0.2 * (2 * 1.16 +2) = 0.296
4次 ·······参数w: 0.296 - 损失函数loss = (w + 1) ^2的图像为:
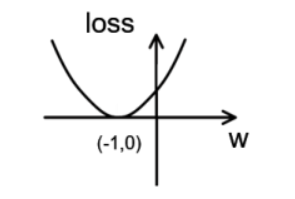
由图可知,损失函数 loss 的最小值会在(-1,0)处得到,此时损失函数的导数为 0,得到最终参数 w = -1。
具体代码实现:
#设损失函数 loss=(w+1)^2, 令w初值是常数5.反向传播就是求最优w,即求最小loss对应的w值
import tensorflow as tf
#定义待优化参数w初值5
w = tf.Variable(tf.constant(5, dtype=tf.float32))
#定义损失函数,二次函数,w作为横轴,loss作为纵轴
loss = tf.square(w+1)
#定义反向传播方法,学习率为0.2,可以自由设定
#学习率过大,会使得待优化的参数在最优解附近震荡
#学习率过小,会使得待优化的参数收敛过慢
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss)
#生成会话,训练40轮
with tf.Session() as sess:
#初始化参数
init_op = tf.global_variables_initializer()
sess.run(init_op)
#迭代40轮
for i in range(40):
sess.run(train_step)
w_val = sess.run(w) #输出w真实值
loss_val = sess.run(loss) #输出loss真实值
print("After %s steps: w is %f, loss is %f" % (i, w_val, loss_val))运行结果:
After 0 steps: w is 2.600000, loss is 12.959999
After 1 steps: w is 1.160000, loss is 4.665599
After 2 steps: w is 0.296000, loss is 1.679616
After 3 steps: w is -0.222400, loss is 0.604662
After 4 steps: w is -0.533440, loss is 0.217678
After 5 steps: w is -0.720064, loss is 0.078364
After 6 steps: w is -0.832038, loss is 0.028211
After 7 steps: w is -0.899223, loss is 0.010156
After 8 steps: w is -0.939534, loss is 0.003656
After 9 steps: w is -0.963720, loss is 0.001316
After 10 steps: w is -0.978232, loss is 0.000474
After 11 steps: w is -0.986939, loss is 0.000171
After 12 steps: w is -0.992164, loss is 0.000061
After 13 steps: w is -0.995298, loss is 0.000022
After 14 steps: w is -0.997179, loss is 0.000008
After 15 steps: w is -0.998307, loss is 0.000003
After 16 steps: w is -0.998984, loss is 0.000001
After 17 steps: w is -0.999391, loss is 0.000000
运行结果分析:
由结果可知可知,随着神经网络训练次数的迭代,w无限接近-1,损失值也接近0
二. 学习率的设置
- 学习率的正确设置对神经网络的收敛速度起着至关重要的作用
- 学习率设置的过大导致梯度下降一直在损失值最低点附近跳跃,始终无法到达损失之最低点,不收敛
- 学习率设置的过小导致梯度下降收敛速度非常慢,得经过很长时间才能达到最小损失值
(1) 对于上例的损失函数loss = (w + 1) ^2,则将上述代码中学习率改为1,其余内容不变
实验结果:
After 0 steps: w is -7.000000, loss is 36.000000
After 1 steps: w is 5.000000, loss is 36.000000
After 2 steps: w is -7.000000, loss is 36.000000
After 3 steps: w is 5.000000, loss is 36.000000
After 4 steps: w is -7.000000, loss is 36.000000
After 5 steps: w is 5.000000, loss is 36.000000
After 6 steps: w is -7.000000, loss is 36.000000
After 7 steps: w is 5.000000, loss is 36.000000
After 8 steps: w is -7.000000, loss is 36.000000
After 9 steps: w is 5.000000, loss is 36.000000
After 10 steps: w is -7.000000, loss is 36.000000
After 11 steps: w is 5.000000, loss is 36.000000
After 12 steps: w is -7.000000, loss is 36.000000
After 13 steps: w is 5.000000, loss is 36.000000
After 14 steps: w is -7.000000, loss is 36.000000
After 15 steps: w is 5.000000, loss is 36.000000
After 16 steps: w is -7.000000, loss is 36.000000
After 17 steps: w is 5.000000, loss is 36.000000结果分析:
(2) 对于上例的损失函数loss = (w + 1) ^2,则将上述代码中学习率改为0.0001,其余内容不变
实验结果:
After 0 steps: w is 4.988000, loss is 35.856144
After 1 steps: w is 4.976024, loss is 35.712864
After 2 steps: w is 4.964072, loss is 35.570156
After 3 steps: w is 4.952144, loss is 35.428020
After 4 steps: w is 4.940240, loss is 35.286449
After 5 steps: w is 4.928360, loss is 35.145447
After 6 steps: w is 4.916503, loss is 35.005009
After 7 steps: w is 4.904670, loss is 34.865124
After 8 steps: w is 4.892860, loss is 34.725803
After 9 steps: w is 4.881075, loss is 34.587044
After 10 steps: w is 4.869313, loss is 34.448833
After 11 steps: w is 4.857574, loss is 34.311172
After 12 steps: w is 4.845859, loss is 34.174068
After 13 steps: w is 4.834167, loss is 34.037510
After 14 steps: w is 4.822499, loss is 33.901497
After 15 steps: w is 4.810854, loss is 33.766029
After 16 steps: w is 4.799233, loss is 33.631104
After 17 steps: w is 4.787634, loss is 33.496712三. 指数衰减学习率
- 指数衰减学习率:学习率随着训练轮数变化而动态更新

其中,LEARNING_RATE_BASE 为学习率初始值,LEARNING_RATE_DECAY 为学习率衰减率,global_step 记录了当前训练轮数,为了不可训练型参数。学习率 learning_rate 更新频率为输入数据集总样本数除以每次喂入样本数。若 staircase 设置为 True 时,表示 global_step / learning rate step 取整数,学习率阶梯型衰减;若 staircase 设置为 False 时,学习率会是一条平滑下降的曲线。
具体代码:
在本例中,模型训练过程不设定固定的学习率,使用指数衰减学习率进行训练。其中,学习率初值设置为0.1,学习率衰减值设置为0.99,BATCH_SIZE 设置为1。
#设损失函数 loss=(w+1)^2, 令w初值是常熟10,反向传播就是求最优w,即求最小loss对应的w值
#使用指数衰减的学习率,在迭代初期得到较高的下降速度,可以在较小的训练轮数下取得最优收敛速度
#学习率随着训练轮数的变化而动态更新
import tensorflow as tf
LEARNING_RATE_BASE = 0.1 #最初学习率
LEARNING_RATE_DECAY = 0.99 #学习率的衰减率
LEARNING_RATE_STEP = 1 #喂入多少轮BATCH_SIZE后,更新一次学习率,一般设为:总样本数/BATCH_SIZE
#运行了几轮BATCH_SIZE的计数器,初值为0,设为不被训练
global_step = tf.Variable(0, trainable=False)
#定义指数下降学习率,学习率每经过一轮BATCH_SIZE,更新一次
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step,
LEARNING_RATE_STEP, LEARNING_RATE_DECAY, staircase=True)
#定义待优化参数,初值为10
w = tf.Variable(tf.constant(5, dtype=tf.float32))
#定义损失函数loss
loss = tf.square(w+1)
#定义反向传播方法
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
#生成会话session,训练40轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(20):
sess.run(train_step)
learning_rate_val = sess.run(learning_rate) #更新学习率
global_step_val = sess.run(global_step) #不被更新,false
w_val = sess.run(w)
loss_val = sess.run(loss)
print("After %s steps: global_step is %f, w is %f, learning rate is %f, loss is %f" % (i, global_step_val,
w_val,
learning_rate_val,
loss_val))
运行结果:
After 0 steps: global_step is 1.000000, w is 3.800000, learning rate is 0.099000, loss is 23.040001
After 1 steps: global_step is 2.000000, w is 2.849600, learning rate is 0.098010, loss is 14.819419
After 2 steps: global_step is 3.000000, w is 2.095001, learning rate is 0.097030, loss is 9.579033
After 3 steps: global_step is 4.000000, w is 1.494386, learning rate is 0.096060, loss is 6.221961
After 4 steps: global_step is 5.000000, w is 1.015167, learning rate is 0.095099, loss is 4.060896
After 5 steps: global_step is 6.000000, w is 0.631886, learning rate is 0.094148, loss is 2.663051
After 6 steps: global_step is 7.000000, w is 0.324608, learning rate is 0.093207, loss is 1.754587
After 7 steps: global_step is 8.000000, w is 0.077684, learning rate is 0.092274, loss is 1.161403
After 8 steps: global_step is 9.000000, w is -0.121202, learning rate is 0.091352, loss is 0.772287
After 9 steps: global_step is 10.000000, w is -0.281761, learning rate is 0.090438, loss is 0.515867
After 10 steps: global_step is 11.000000, w is -0.411674, learning rate is 0.089534, loss is 0.346128
After 11 steps: global_step is 12.000000, w is -0.517024, learning rate is 0.088638, loss is 0.233266
After 12 steps: global_step is 13.000000, w is -0.602644, learning rate is 0.087752, loss is 0.157891
After 13 steps: global_step is 14.000000, w is -0.672382, learning rate is 0.086875, loss is 0.107334
After 14 steps: global_step is 15.000000, w is -0.729305, learning rate is 0.086006, loss is 0.073276
After 15 steps: global_step is 16.000000, w is -0.775868, learning rate is 0.085146, loss is 0.050235
After 16 steps: global_step is 17.000000, w is -0.814036, learning rate is 0.084294, loss is 0.034583
After 17 steps: global_step is 18.000000, w is -0.845387, learning rate is 0.083451, loss is 0.023905
After 18 steps: global_step is 19.000000, w is -0.871193, learning rate is 0.082617, loss is 0.016591
After 19 steps: global_step is 20.000000, w is -0.892476, learning rate is 0.081791, loss is 0.01156
结果分析:
由结果可知,随着训练次数的增加,参数w不断接近-1,学习率也在不断减小,损失值不断减小
四. 滑动平均
- 滑动平均:记录了一段时间内模型中所有参数 w 和 b 各自的平均值,利用滑动平均值可以增强模型的泛化能力
- 滑动平均值(影子)计算公式:影子 = 衰减率 * 参数
- 其中衰减率 = min{AVERAGEDECAY(1+轮数/10+轮数)},影子初值 = 参数初值
-
用 Tensorflow 函数表示:
ema = tf.train.ExpoentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
-
其中 MOVING_AVERAGE_DECAY 表示滑动平均衰减率,一般会赋予接近1的值,global_step 表示当前训练了多少轮
ema_op = ema.apply(tf.trainable_varables())
-
其中 ema.apply() 函数实现对括号内参数的求滑动平均,tf.trainable_variables() 函数实现把所有待训练参数汇总为列表
with tf.control_dependencies([train_step, ema_op]):
train_op = tf.no_op(name='train') - 其中,该函数实现滑动平均和训练步骤同步运行
- 查看模型中参数的平均值,可以用 ema.average() 函数
具体例子:
- 在神经网络中将 MOVING_AVERAGE_DECAY 设置为 0.9,参数 w1 设置为 0,w1 滑动平均值设置为 0
-
(1)开始时,轮数 global_step 设置为 0,参数 w1 更新为 1,则滑动平均值为:
w1 滑动平均值 = min(0.99, 1/10)0+(1-min(0.99,1/10))1 = 0.9
-
(2)当轮数 global_step 设置为 0,参数 w1 更新为 10,以下代码 global_step 保持 100,每次执行滑动平均操作影子更新,则滑动平均值变为:
w1 滑动平均值 = min(0.99, 101/110)0.9+(1-min(0.99,101/110))10 = 0.826+0.818 = 1.644
-
(3)再次运行,参数 w1 更新为 1.644,则滑动平均值变为:
w1 滑动平均值=min(0.99,101/110)*1.644+(1– min(0.99,101/110)*10 = 2.328
代码实现:
#滑动平均:记录了一段时间内模型所有参数w和b各自的平均值,利用滑动平均值可以增强模型的泛化能力
#滑动平均值追随着参数,随着参数的变化而变化
import tensorflow as tf
#1.定义变量以及滑动平均值
#定义一个32位浮点变量,初始值为0.0,这个代码就是不断更新w1参数,优化w1参数,滑动平均做了w1的影子
w1 = tf.Variable(0, dtype=tf.float32)
#定义num_updates(NN的迭代轮数),初始值为0,不可被优化(训练),这个参数不被训练
global_step = tf.Variable(0, trainable=False)
#实例化滑动平均类计算公式,滑动平均衰减率为0.99,当前轮数global_step
MOVING_AVERAGE_DECAY = 0.99
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
#ema.apply后的括号里是更新列表,每次运行sess.run(ema_op)时,对更新列表中的参数求滑动平均值
#在实际应用中会使用tf.trainable_variables()自动将所有待训练的参数汇总为列表
#eme_op = ema.apply([w1])
ema_op = ema.apply(tf.trainable_variables())
#2.查看不同迭代中变量取值的变化
with tf.Session() as sess:
#初始化参数
init_op = tf.global_variables_initializer()
sess.run(init_op)
#用ema.average(w1)获取w1滑动平均值(要运行多个节点,作为列表中的元素列出,写在sess.run中)
#打印出当前参数w1和w1的滑动平均值
print(sess.run([w1, ema.average(w1)]))
#参数w1的值为1
sess.run(tf.assign(w1, 1))
sess.run(ema_op) #求参数w1的滑动平均值
print(sess.run([w1, ema.average(w1)]))
#更新step和w1的值,模拟出100轮迭代后,参数w1变为10
sess.run(tf.assign(global_step, 100))
sess.run(tf.assign(w1, 10))
sess.run(ema_op)
print(sess.run([w1, ema.average(w1)]))
#每次sess.run会更新一次w1的滑动平均值(影子)
sess.run(ema_op)
print(sess.run([w1, ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1, ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1, ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1, ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1, ema.average(w1)]))
sess.run(ema_op)
print(sess.run([w1, ema.average(w1)]))
实现结果:
[0.0, 0.0]
[1.0, 0.9]
[10.0, 1.6445453]
[10.0, 2.3281732]
[10.0, 2.955868]
[10.0, 3.532206]
[10.0, 4.061389]
[10.0, 4.547275]
[10.0, 4.9934072]结果分析:
从运行结果可知,最初参数 w1 和滑动平均值都是 0;参数 w1 设定为 1 后,滑动平均值变为 0.9;
当迭代轮数更新为 100 轮时,参数 w1 更新为 10 后,滑动平均值变为 1.644。随后每执行一次,参数
w1 的滑动平均值都向参数 w1 靠近。可见,滑动平均追随参数的变化而变化
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









