






Tcp/ip五层模型:应用层,传输层,网络层,链路层,物理层(有时候四层没有物理层)
根据每一层提供的服务以及协议接口进行讲解
应用层:http协议,自定制协议—>负责应用程序之间的沟通(如何自己定制协议)
传输层–>作用如何实现
应用层:负责应用程序之间的数据沟通
应用程序性就是应用层的程序–>之间与用户进行沟通
协议:自定制协议:–>自己约定定制的协议
知名协议:在自定义协议基础上因为应用广泛人多了就成了知名协议了http
数据的序列化与反序列化:
数据进行可持续化存储时,数据的组织就是序列化.(持续化存储–>数据存到一个地方不管断电与否都一直存在(就是直接存储到硬盘))–>将数据存储到磁盘如何组织数据就是序列化
服务端通信的时候需要获取客户端的地址信息吗?–>已经单独记录了客户端的地址信息直接进行通信(不需要send,recvfrm)
数据进行存储时序列化的,数据进行网络通信的时候也是序列化的过程(发送其实就是给网卡写数据)(数据的序列化与反序列化就是数据的组织以及解析)
typedef struct {
7 char name[32];
8 int id;
9 int sex;
10 int age;
11 }stu;
12 int main(){
13 stu s;
14 s.id=10;
15 s.age=16;
16 s.sex=1;
17 strcpy(s.name,“xiaoming”);
18 int c=200;
19 int a=100;
20 char buff[1024]={0};
21 sprintf(buff,“a=%d,c=%d”,a,c);
22 int fd=open("./tmp.txt",O_CREAT|O_RDWR,0664);
23 if(fd<0){
24 printf(“open erron\n”);
25 return -1;
}
27 write(fd,(void*)&s,sizeof(stu));//结构体存储到文件里一个stu整体长度为12+32=44
28 //个字节–>二进制形式存储,存到文件里面依次为id,age,sex–>解析的时候录一个44个
29 //字节结构体直接录就可以了(直接结构体上直接解析完毕了)
30 lseek(fd,0,SEEK_SET);//跳转,跳转到起始位置,进行读取
31 stu child;
32 read(fd,(void*)&child,sizeof(stu));
33 printf(“name:%s id:%d age:%d sex:%d\n”,child.name,child.id,child.age,
34 child.sex);
35 close(fd);
36 return 0;
38 }
发现可以运行
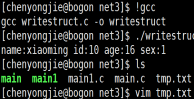
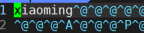
然后发现名字也写入到文件里了二进制存储标准字符串是可以看到的但是其他的都是二进制存储看不到
网络上进行数据传输的时候通常一次性不是传输一个数据.一般是数据很多,所有这些数据提前进行序列化,然后到达对端进行反序列化–>最常用的自定制方式就是结构体(用起来方便直接写读)
自定制协议:数据存储的时候第一个32个字节是name第二个4个字节是id第三个四个自己是age第四个四个字节是sex,按照这种格式提出了个约定,自定制协议然后发送过去,对方解析的时候拿前32个字节就是name接下来的4个字节就是id等等最后拿4个字节就是sex按照相同的格式解析
知名协议http:–>应用层的协议都是自定制协议只不过用的场景多人多了就成了知名协议
http协议就是其中的一种–>传输网页资源
全名–超文本传输协议
url:网址eg:www.baid.com–>统一资源定位符(网络上路径是唯一的)
Url:包含什么:
Eg:http://www.baidu.com/
http:协议名 :/间隔符,www.baidu.com是服务器的地址通常称为域名(如果知道百度的ip地址可以直接替换www.baidu.com)–>用域名表示ip地址是因为ip地址不好记 .com(顶级域名也叫一级域名)baidu为二级域名(通常为公司的名称组织来命名)www(常用用法)
www.zhidao.baidu.com–>zhidao为三级用名;www.baidu.com是服务器的地址名称通常名称输入之后进行解析解析成ip地址进行发送数据端口号65535个(0-1024不推荐使用–>一些协议 把端口使用了http就是80端口)http//www.baidu.com:80/—>把端口省略了–>因为http默认使用80所以省略了;http://www.baidu.com:80/
80后的/–>资源符(资源名称路径)
Hhtp://www.baidu.com/index.html—>就是百度首页–但是百度用的是https(在http的基础上进行加密)
/index.html–>所请求的资源路径(/根路径–>访问的根目录比如在百度服务器上面某个路径拿某个路径作为一个根目录进行访问–>代表能访问的最上层目录就是这个路径(百度服务器不是所有的文件都能访问需要指定一个路万一有隐私性数据就会被别人窃取)称为相对根目录) 根目录下的index.html请求的资源–>就是百度首页–>右键还可以查看网页源代码
一个完整的http协议应该是:
http://username:password@www.baidu.com:80/index.html -->需要用户和密码,:和@都是间隔符但是这种方式不安全被淘汰了–>是什么路径下的什么资源–>统一资源定义符
http://username:password@www.baidu.com:80/index.html?wd=c%2B%2B
https://www.baidu.com/s?wd=c%2B%2B&rsv_spt=1&rsv_iqid=0xea7ff4150002df33&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=6&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&inputT=4897&rsv_sug4=4898
以k=value形式存在wd=c%2B%2B–>查询字符串–>c2B就是c++
完整的url:http://username:password@www.baidu.com:80/index.html?wd=c%2B%2B#ch
#ch–>片段标识符–>打开某个位置直接在网站的某个位置而不是网站的起始位置,–>就是片段标识符的作用,起始就是标志了在html超文本信息里面某一个标志位(某个位置)
完整的url包含了:协议名://用户:密码@服务器地址:端口/资源路径?查询字符串#片段标识符
C%2b–>为什么+变成了%2b
如果查询c?那么就变成index.htm?wd=c?–>则出现问好间隔二义性,则不知道从后面问号开始还是从前面开始解析->不好解析–>http是明文传输的协议–>传输的就是字符串–>把数据以特殊字符间隔的–>假如提交的数据里本身携带某些特殊字符会造成特殊字符的二义性–>规定凡是自己提交的数据不能出现特殊字符–>将特殊字符进行转义%2b–>转义就是urlencode和转义编码相对应的就是urldecode(url解码)
如何编码
Printf(“%x\n”,’+’)–>打印结果就是2b–>把某个特殊字节字符进行16进制转换–>标准做法一个字节的前4位组成数字后4位拿出组成一个数字(前4位为2后4位为b)一起则成了2b
如果直接写wd=2b会认为本身提交就是2b为了告诉服务器是经过编码的需要拿个特殊符号标识一下所以用%,只要遇到%后面这两个2b就是16进制数字–>需要将其转换为字符
Urlencode/urldecode
因为http的url中特殊字符一般都有特殊含义,所以我们提交的查询字符中步能随意出现特殊字符,如果非要有特殊字符,就需要对特殊字符进行转义(url编码)
如何编码:将一个字节的前四位/后四位转换为16进制数据合并一起显示,使用%标识这是经过url编码过的字符eg:±->%2b
如何解码:2*16+b
Fiddler(抓包)–>浏览器和服务器之间搭了个代理–>浏览器发送情趣的时候会把数据发送到fiddler然后fiddler在把数据发送到服务器上,fiddler可以显示你发送了什么请求,当服务器回复,先回复到fiddler上,会显示服务器回复了什么数据然后在发送给浏览器浏览器再进行显示–>代理作用
打开tool->captureHTTPScpmmects
Decrypt HTTPPStraffic选中这两个

否则抓不到http的包
https://www.baidu.com/index.html
Cotrl+a Delete是删除

则在fiddler里面爪了一串包

可以看到这个就是刚才的请求

看到row这列就是刚给百度服务器发送的请求信息
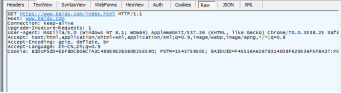
此处就是回复
然后要进行解码点击responsebody…
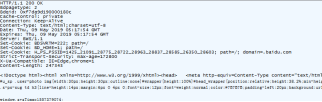
结果如下
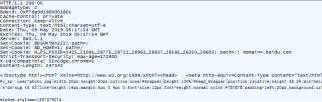
然后对抓包数据进行保存

右键–>save -->selected sessions–>astext…
将其保存到桌面
Fiddler工作原理:是以代理web服务器的形式工作的,它使用代理地址(本地地址)127.0.0.1,端口8888当fiddler启动后将自己变成一个代理服务器,这个代理服务器默认监听127.0.0.1:8888然后打开ie浏览器会以127.0.0.1:8.退出时候会自动注销,不会影响其他程序fiddler非正常退出,这时候fiddler没有自动注销会造成网页无法访问
http协议怎么组织序列化

上图就是http请求
如下:
GET https://123.207.58.25/longin/index.html HTTP/1.1 首行
Host: 123.207.58.25
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: BIDUPSID=EEF8DCB06C7A3C489E9E2B360D25E590;:FG=1; BDUSS=GhveGF3MlN0VENsRmV4c2hxd35uellvMDZpMHlZcERSSWo1VHBOemRna2liTWxjRVFBQUFBJCQAAAAAAAAAAAEAAAB3sIBcuqPDwLqj6eS6o8WvAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACLfoVwi36FcZ; BD_UPN=1a314353; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=1425_21091_28775_28722_28963_28837_28585_26350_28603; delPer=0; BD_CK_SAM=1; PSINO=2; BD_HOME=1
http是一个明文传输协议–传输层使用的是tcp协议
http请求分了三大部分:第一部分首行以 空格间隔包含了(1)请求方法(post)(2)url(3)协议版本(4)换行\r\n
从houst到accept-language都是http的头信息,头部信息里面是是一个个健值盾,排布方式为k:空格value—>Host: 123.207.58.25–>组织头信息
K: value\r\n–>k空格value\r\n
空行下是http协议的正文–正文可以是任意数据
http的协议格式:首行:包含请求方法 url 协议版本
请求方法有:GET请求和POST请求
Get 获取某些资源也可以递交一些数据
Post:递交传递某个表单数据–>向服务器上传数据
Head:数据发送过去不要正文信息返回一个头部信息就可以了只是验证一些http是否通
协议版本–>http1.0版本–>请求方法有post get head
http1.0版本–>请求方法有post put delete trace connect get head
GET和POST都是获取资源,get获取资源轻于上传数据(get上传数据没有正文,它的数据放在查询字符串当中),提交的数据在url的查询字符串中上传给服务器,没有正文
Get请求提交数据在url中,所以url有限制,长度(早间1k现在大约4k)
Post:获取资源,用于提交表单数据之后返回某个页面(注册用户:姓名密码邮箱信息,提交给服务器,服务器返回一个注册成功页面)–>侧重于提交大量数据给服务器,提交的数据在正文中
最大区别get没有正文而post有正文
首行 头部 空行 正文
头部:包含有提交给服务器端的一些关键信息并且这些关键信息的组织格式:以key:value表示,并且每一条关键信息之间以\r\n间隔
比较常见的头部信息:
Host–>请求主机的服务器地址信息
User-agent–>windows版本以及cpu的架构操作系统是多少位的当前使用说明浏览器,浏览器是哪个版本–>向服务器发送硬件和软件信息
作用:根据版本选择性发送一些数据给返回页面(版本太低无法显示)
Accept:当前浏览器器可以接受哪些数据–>text:文本html类型(显示网页)image图片信息*/*随意信息
Eg:Accept: text/html,application/xhtml+xml,application/xml;q=0.9,
Accept-Encoding–>能够接受的数据格式gzip(服务器返回的数据过大可以先用gzip将数据压缩然后进行发送)
Accept-Language:zh-CH,zh;q=0.9---->支持的语言中文
Referer:http://123.207.58.25/admin
当前url请求是从哪个页面跳转过来从–>admin跳转过来–>更多的应用是统计流量
Eg:搜花–>是从百度搜索还是搜狗–>从哪里跳转过来-
http明文->中间把数据截取,改成自己的网站–>统计的都是自己的网站–>用https加密协议–>保证安全
Content-Type:application/x-www-from-urlencoded
x-www-form–>格式 urlencoded–>url编码–正文是经过url编码过的正文–>正文的类型格式
Content-Length:27—>正文长度–>tcp存在粘包问题是因为数据没有边界–>无法获知协议多少–>http使用的是tcp协议所以不知道整个http数据有多长–>服务端接受数据时候不知道有多长->怎么接受–>就先接受http头部信息–>当接受数据时候遇到连续两个\n\r(因为有正文头之间有一行空格)–>代表头部接受完了–>一个字节一个字节接收效率慢–>tcp–>recv中一个选项标志为msgpeek探测性接受数据并不移除(读出数据但是并不从缓冲区移除)–>eg:接受信息时候直接接受4096个数据都过来了头部一定接受完了–>在获取的一大段数据中找\r\n就可以找到头了(strstr(buf,”\r\n\r\n”)–>不为空找到了并返回\r\n\r\n起始位置,通过这个位置减去起始位置+4就是头部长度,重新recv读取就是头部长度–>然后解析从contentlength(指定正文长度)获取正文长度就可以将正文拿出来–>数据都是指定长度–>解决粘包了
接收http数据的时候先接受头部从头部获取正文长度然后从正文获取指定数据长度
总结:
http协议格式:
首行:请求方法 url 协议版本
Cet:获取资源,提交的数据在url的查询字符串中上传给服务器没正文
Post:获取资源侧重于提交大力数据给服务器,提交的数据在正文中
头部:
包含提交给服务端的一些相关信息并且这些关键信息的组织格式为:
Key:val\r\nkey:val\r\n
Content-length content-type host user-agent accept referer
空行:间隔头部与正文
正文:提交给服务器端的数据
响应格式:
第一行首行
首行之后到空行的部分是头部信息接下来是空行然后使正文
首行:hhtp/1.1 303 See other
协议版本 响应状态:当前客户端发送过去的http请求处理的怎么样了数字有很几十种1开头提示信息,2开头:200 ok–>请求服务器已经响应成功(处理成功)
3开头的:重定向,原本请求现在服务器,请求过去之后–服务器说资源不对资源已经很早不用了重新返回一个资源路径–>重新请求另一个位置–>请求的位置为location
Location:http://123.207.58.25/
该信息一旦发送过来之后浏览器就会重新请求该地址
重定向:永久重定向和临时重定向都是以3开头
以4开头404 page not found当前页面没有找到(没有该资源)
400 bad request 403 forbiden 还有一个认证失败也是4开头—>4开头都是客户端错误
5开头:服务端错误–>请求资源服务端先打开资源读取数据给用户端返回,但是打开时候有可能文件打开失败就会显示服务端出现错误–eg 502服务器内部错误
:hhtp/1.1 303 See other中seeother响应的状态码描述信息每个状态码都有相应的信息可以写自己的描述也可以用标准的,响应最后看的是响应码
响应(response):
首行:协议版本 状态码 状态码描述信息
状态码 1提示信息2正常处理完毕3资源重定向4客户端的错误5**服务端错误
头部格式: key: val\r\nkey: val\r\n
Location transfer-Encoding Set-Cookie
空行:间隔头部与正文
正文
比较常见的响应头信息:
location:重定向的位置
Trasnfer-Encoding:chunked
功能:不知道正文有多长,但是每次发送一段之前这一段有多长,然后在发送数据所以在发送正文之前有一个数字–>16进制数字–>接下来发送正文长度,并且最后当正文发送完后还会发送一个0\r\n–>表示正文发送完毕–通常应用不知道数据多长响应数据有多长
Content-Type: text/html; charset=utf8—>htm页面字符编码为utf8
Set-Cookie:PHPSESSID=d446bnf6kkca6k86o08ier9473; path=/ -->服务端响应信息中的cookie
Set-cookie:loginStatus=yes;expires=sun,13019—>expries过期时间
Cookie:BAIDUID=59C96026…97E0: FG=1;–>请求中的cookie
Set-cookie与请求头里的cookie一样有setcookie才会保存cookie
使用cookie可以提升用户体验:没有cookie前
服务端响应时候设置setcookie客户端保存cookie文件,文件当中保存当前网站的登录信息认证信息会话信息在cookie文件中,每次请求网站时候都会从文件中读取认证信息,直接发送过去,就不用每次登录了,在setcookie还包含了过期时间(什么时候过期,过了就用不了了)
http协议传输层使用tcp协议第一步建立tcp服务端程序,(要解析一个http请求头)之后按照人家的请求组织响应头然后发送
编写一个最简单的http服务器:
功能:不管浏览器向服务端法什么请求,服务端都只返回一个页面
在notepad++里面写下














 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









